学习内容:
1、单词意思
2、word2vec 简介
3、word2vec 目标函数
4、优化目标函数
wordnet词汇
人们很难从同义词词典中获取跟多的价值,虽然有很多资源但是存在很多细微的差别。
比如good的一组同义词:行家,专家,好的,熟练的,精通的,擅长的。这些其实是完全不同的东西,比如深度学习专家和擅长深度学习。
难以发现新的词汇,比如深度学习忍者。
人们往同义词集里加词汇,有很大的主观性,如何区分一个词有哪些含义,那些词你认为是一样的,哪些词是不一样的,是非常模糊的判断。
需要大量的人力去维护
很难对词汇的相似性给出准确的定义。比如精通比好,更接近专家,但是在wordNet就找不到这样的差别。
因此,这就是个问题,这个就是离散化表征普遍存在的一个问题。几乎所有的NLP研究,除了现代深度学习,其他所有的NLP都使用了原子符号来表示单词,比如酒店、会议、散步。如果从神经网络的角度考虑这个问题,那么使用原子符号就像是使用 one-hot 编码(只有1个位置是1,其它都是0),那么我们就有了大量与原子符号相对应的词汇向量,这就代表一个特定的符号,比如酒店。而这样的向量会非常长。
那么这些向量为什么会有问题呢?
因为它没有给出任何词汇之间的内在关系概念,而我们经常想得到的是,一些有相近含义的词汇和短语。
比如,在一个网络搜索应用中,如果用户搜索“戴尔笔记本的电池大小” 我们希望匹配的是关于”戴尔便携式电脑电池容量“的文档,所以我们就要知道笔记本(notebook)和便携式电脑(laptop)含义相近,大小 和 容量 是近似的意思,因此可以等同起来。酒店 和 汽车旅馆 有近似的含义。问题是如果我们使用独热向量编码,他们没有天然的近似含义,这两个向量的点积是0,他们之间没有内在相似性。这种符号编码的问题不仅存在于自然语言处理中,传统的基于规则的理性主义方法,也存在于所有基于概率统计的传统的机器学习方法,尽管这些模型运用了真是的数字,它们计算了某些词在其它词存在背景下出现的可能性,但是因为它们都是基于符号表示开发的,所以不能得出词汇和模型之间的关联,每个词都是独立存在而已。
我们必须建立词汇之间的相似性关系,我们探索了一种直接的方法,一个单词编码表示的含义,是可以直接阅读的,在这些表示中可以看出相似性,我们要做的就是构造这些向量,然后做一种类似求解点积的操作,这样就可以让我们了解词汇之间有多少相似性。
怎么做?
NLP概念,称作分布相似性,分布相似性是指,你可以得到大量表示某个词汇含义的值,只需要通过观察其出现的上下文,并对这些上下文做一些处理来得到单词的意思。
如果我想知道banking这个单词的意思,需要做的就是找到数千个包含banking的例句,观察每一次它出现的场合,会看到和它一起出现的词,”debt problems, governments,regulation,Europe,unified",然后开始统计所有出现过的内容,通过某种方式用这些上下文中的词来表示banking的含义。“你应该通过一个词的同伴来理解这个词的意思”,理解一个词的含义,应该通过上下文的来解决。因此,从本质上来说,如果你可以预测这个单词出现的文本上下文,你也就能理解这个单词的含义了。
需要做?
就是给每一个单词构造一个向量,一个密集型向量,让它可以预测目标单词所在文本的其它词汇,所有其它的词汇也是由一个个单词组成的,接下来看一些相似性方法,比如两个向量间的点积,对它进行一些修改,让它可以预测,通过递归循环,这些词汇就可以预测上下文的其它词汇,反之亦然。
两个关键词,分布式(distributional),分布式表示(distributed representations),即用密集型向量表示词汇的含义
什么是word2vec
这是我们一种通用的方法,来学习神经词嵌入问题。
定义一个模型,来根据中心词汇预测它上下文的词汇,有一些概率的方法,根据给定单词预测上下文单词出现的概率,就可以用损失函数来判断预测的准确性,理想状态下,我们可以准确预测中心词汇周围的词。这里的-t表示围绕在t中心词周围的其它单词,如果我们可以根据t精准预测这些词,那么概率就为1,那就没有损失了。如果有25%的概率预测对,就有75%的损失。所以就得到一个损失函数,我们将会在答应语料库的各个地方重复这样的操作,所以我们的目标是调整词汇表示,从而使损失最小化。实质上是让每个单词的向量,能够预测其周围的词汇,反之亦然。
wt是中心词汇,w-t 是除它外所有其它的上下文。
p(context|wt)=..
损失函数:J = 1 - p(w-t|wt)
word2vec 的思想
word2vec尝试去做的最基本的事情就是利用语言的意义理论,来预测每个单词和它上下文的词汇。word2vec里面有两个用于生产词汇向量的算法。
两个算法:
1、Skip-grams(SG)
Predict context words given target (position independent)(预测上下文)
2、Continuous Bag of Words(CBOW)
Predict target word from bag-of-words context(预测目标单词)
两套效率中等的训练方法
1、Hierarchical softmax
2、Negative sampling
今天重点:Skip-grams(SG)、一种低效的训练方法(基本),作业是实现一套有效的算法。
Skip-grams 预测
Skip-grams概念:每一步都去一个词作为中心词汇,比如在这里选取banking为中心词汇,接下来尝试去预测它一定范围内的上下文词汇,所以这个模型将定义一个概率分布,即给定一个中心词汇,某个单词在它上下文中出现的概率,会选取词汇的向量表示,以让概率分布值最大化,并不是对左边或右边的词汇分布有一个概率分布,对一个词汇,我们有且仅有一个概率分布,这个概率分布就是输出,也就是出现在中心词汇周围的上下文的一个概率分布输出。
word2vec 细节
接下来要做的就是定义一个半径为m,从中心词汇开始,到距离为m的位置,来预测周围的词汇,在多处进行多次重复操作,要选择词汇向量,以便让预测的概率达到最大。
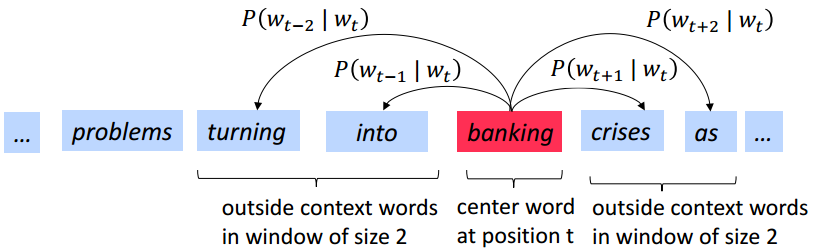

上面给出的公式L(θ)表示,我们拿到很长的文本,然后遍历文本中所有位置,然后对于文本中的每一个位置,我们都会定义一个围绕中心词汇的大小为2m的窗口,这样就得到一个中心词汇预测上下文词汇的概率分布。我们的目标就是选择词汇向量使得这个预测概率L(θ)最大。
θ是我们需要优化的模型参数。除了词汇的表示,还有其他一些参数也可以进行优化调整,如窗口大小等,但我们这里暂不考虑。
对公式稍作调整,就可以得到下面的损失函数J(θ)。对函数取log,求积变成了求和(对数概率分布),前面乘以1/T,相当于对每个词汇进行归一化处理,相比于最大化,我们更喜欢处理最小化问题,因此前面加一个负号。这样我们就得到一个负的对数似然,我们的目标就是最小化J(θ)。负的对数似然准则意味着我们使用的是交叉熵损失函数(cross-entropy loss)

例子:
the cat jump over the dog
假设我们用表示,如果window=2,那么左右两边的上下文就可以用
,
,
,
来表示,由于上下文四个词与jump连接在一起,于是看到jump,我们有理由估计出现在它左右两边的词就是上下文四个词,这个“估计”可以用条件概率来表示P(
,
,
,
|
),如果它们的组合在所有文本中出现的越多,这个概率就越大,我们假设每个词的出现是相互独立的,当然事实上词与词之间存在着很强的关联,但为了计算方便,我们暂时假定词与词之间没有关联,于是前面的联合条件概率可以分解成:P(
*P(
|W_i)*P(
)*P(
),遍历每一个词汇后,就是L(θ)。
P(wt+j|wt;θ)这个条件概率要怎么表示???
现在我们只有一个one-hot目标,所以就只预测一个当前的单词。怎么利用单词向量来最小化负的对数似然函数呢?
采用的方法是,根据单词向量构造而成的中心词汇,来得出其上下文的概率分布,概率分布的形式如下:

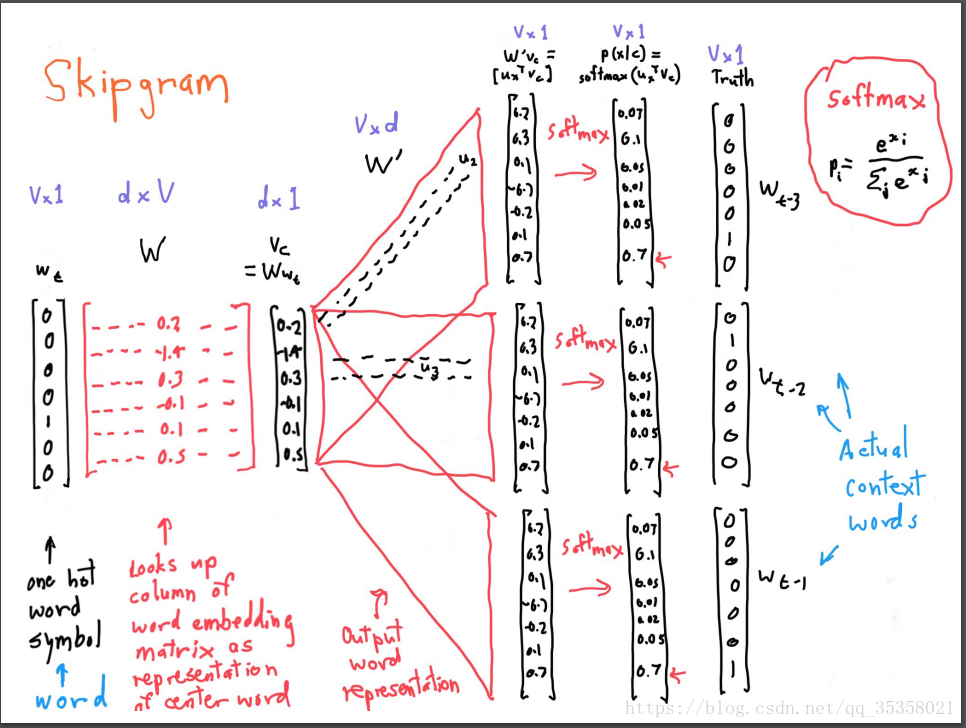
首先,每种单词类型都有一个对应的向量,uo是索引为o的单词所对应的向量(上下文单词的向量),vc是中心单词对应的向量,c和o分别是它们的单词索引值,就是单词在文本中的位置。所以uoTvc是向量内积,如果两个词向量比较接近,他们的内积会比较大。V是整个词典词的个数,所以其实分母部分就是所有词的词向量与目标词向量(即上面图中的示例banking的词向量)的内积之和。而使用指数(softmax)是为了将实数(有负有正)映射成整数,然后分母部分是为了归一化变成概率。
我们有一个中心词汇的独热编码向量,然后有一个所有中心词汇表示组成的矩阵,如果我们将这个矩阵和向量相乘,我们选出这个矩阵的列代表的就是中心词汇的表示。接着我们构造第二个矩阵,用于存储上下文词汇的表示。对于上下文的每个位置,我们把这个向量和这个矩阵相乘,这个矩阵就是上下文的词汇表示。我们挑出中心词汇和上下文表示的点积,然后用softmax方法将它们转化成概率分布,给定一个中心词汇作为一个生成模型,它可以预测在上下文中出现的词汇的概率,概率最高的就是我们应该选择的单词,但如果实际的上下文单词不是这个,说明你的预测做的不够好,产生了一些误差。
从左到右是one-hot向量,乘以center word的W于是找到词向量,乘以另一个context word的矩阵W’得到对每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失
参考:https://www.jianshu.com/p/cdb93906607b
一般来说,我们会把模型中所有的参数都放进一个大的向量θ 里,然后进行优化,通过改变这些参数,让模型的目标方程最大化,所以我们要的参数就是对每个单词都有一个小向量,不管它是中心词汇还是上下文词汇,这样我们就得到一个一定大小的单词表。
对vc 和 uo求偏导,他们都是这个模型的参数。



使用随机梯度下降法,优化目标函数。
总结:对于任意位置,给定中心词汇c的情况下,这个单词x,就是出现在窗口中的词汇的概率。