线性分类
目录
-
线性分类概念
-
解释线性分类器
-
损失函数
-
实例
-
总结
线性分类概念
承上:上一节介绍了图像分类的基本概念。我们还介绍了KNN分类器,它通过比较测试集到训练集所有图像的距离来决定测试集的类别。然而KNN有着众多的缺点:
- 分类器必须记住所有的训练数据并且将此数据存储以用于将来和测试数据比较。这在空间上是低效率的,因为数据及大小很容易超出存储限制。
- 对一张测试图片分类代价昂贵,因为它要求和所有的训练图像进行比较。
启下:我们将选择一种更加有效的方法来进行图像分类。最后再延伸到整个神经网络和卷及神经网络。这种方法主要有两个部分:
- 一个得分函数:将原生数据映射到类别得分。
- 一个损失函数:量化预测分数与真实得分的一致性。
我们将此问题当作优化问题,即我们将最小化以得分函数的参数为变量的损失函数。
将设我们有N个样本,每一张维度为D且由K个不同的类别。例如在CIFAR中,我们有50000张训练图片,每一张的维度为D=32*32*3=3072像素,且K=10。现在定义得分函数。
线性分类器:在这个样例中,我们将使用最简单的概率函数,一个线性映射:
表示训练集输入图像,它的所有像素值被压平为一个列向量,其shape[D*1],矩阵W(shape[K*D])。最后向量b(size[k*1])表示函数偏置参数。
在CIFAR10中,D的shape[3072 x 1],W是权重,其shape[10 x 3072]和偏置b的[10*1]。

假设输入图像仅有四个像素点,不考虑颜色通道。类别标签有三个。我们拉伸图像像素成一个列向量,并与矩阵相乘。
一般情况下,分别跟踪权重W和偏置b有些麻烦。一个常用的技巧是将这两个部分的参数并成为一个矩阵,而输入向量在末尾额外增加一项值为1的的特征。

有几点需要注意
- 单独的矩阵相乘是在同时有效的评估10个独立的分类器,每一个分类器是矩阵W的一行。
- 假设输入数据已经给定且固定,我们控制着参数W,b的设置。我们的目标是设置这些参数使得计算机在整个数据集上,计算的得分,匹配真实标签得分。
- 这种方法的优点是,训练集用于学习参数W,b。一旦学习过程完毕,我们可以直接丢弃整个训练集,仅仅保留参数。因为测试图片可以直接前向传播,并通过计算的得分被分类。
- 相较于KNN,线性分类器仅包含一个单独的矩阵相乘和相加,这大大的减少了计算量和测试时间。
解释线性分类器
请注意,线性分类器将类的分数计算为其所有3个颜色通道中所有像素值的加权和。依赖于我们为这些权重设置的确切值,函数有能力在某些点,喜欢或者不喜欢(决定于权重的符号)某种颜色。例如,如果图像两侧有很多蓝色(这可能对应着水),你可能认为这是一个船类。你可能希望船的分类器在蓝色通道有很多正向的权重(表现为蓝色提升ship得分),而在绿色和红色通道由反向的权重(表现为绿色和红色减少船类得分)。
详细解释见https://github.com/cs231n/cs231n.github.io/blob/master/linear-classify.md
数据预处理技巧:一般图像像素值都在[0,255]之间。在机器学习中,一种很常见的操作是对输入特征进行标准化处理和归一化处理,即均值为0,方差为1,取值在[-1, 1]之间。
损失函数
损失函数(代价函数或者目标函数):用于衡量我们对结果的满意程度,如果损失很高则表现差,反之亦然
支持向量机损失详情
实例
支持向量机是两种常见的分类器之一(对于具体的公示步骤我没有实现过)。另一种流行的选择是softmax分类器,它有着一种不同的损失函数。softmax分类器是二元逻辑回归分类器的泛化,它比SVN更加直观。
在logistic回归中,训练集由 个已标记的样本构成:
,由于logistic回归是针对二分类问题的,因此类标记
假设函数如下:

训练模型参数 ,使其能够最小化代价函数:
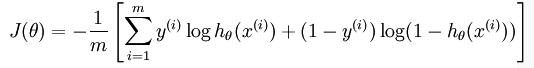
在softmax回归中,解决的是多分类问题,类标 可以取
个不同的值。
对于给定的测试输入 ,用假设函数针对每一个类别
估算出概率值
,即,估计
的每一种分类结果出现的概率。假设函数将要输出 一个
维的向量来表示这
个估计的概率值。假设函数
形式如下:
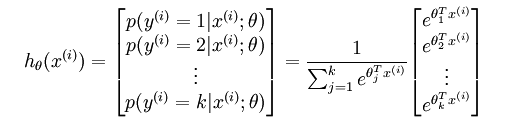

2 代价函数
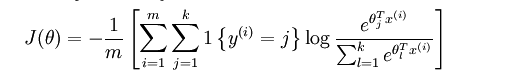
上述公式是logistic回归代价函数的推广。logistic回归代价函数可以改为:
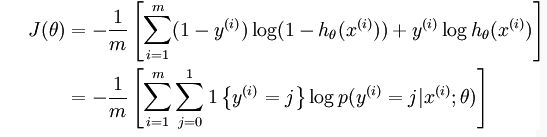
Softmax代价函数与logistic 代价函数在形式上非常类似,只是在Softmax损失函数中对类标记的 个可能值进行了累加。注意在Softmax回归中将
分类为类别
的概率为:

3 softmax回归模型参数化的特点

这表明前面的 softmax 回归模型中存在冗余的参数。更正式一点来说, Softmax 模型被过度参数化了。
实际问题:
当书写代码来计算softmax函数,内置项由于指数而变得非常大。除以非常大的数字将会非常不稳定,因此使用标准化技巧将至关重要。
另一个常用的操作如代码所示,设置除数最高值为零

总结
- 本节图像得分函数即将图像像素映射到类别得分的函数,本节中线性函数决定于权重W和【偏置b
- 不像KNN分类方法,参数化方法的优点是,一旦学习完参数,训练集就可以被丢弃。并且,新的测试集图像的预测很快,仅仅包含一个惩罚,不需要和训练集每张图片比较。
- 本节介绍了偏置技巧。它使得我们可以折叠偏置向量到权重矩阵中,使我们方便地只用追踪一个参数矩阵。
- 本节介绍两个常用线性模型常用损失函数,SVM和softmax,其用于测量给定参数集与训练集的兼容性。我们还看到损失函数以这样的方式在训练集预测效果良好,即等效于有一个较小的损失。
如何有效的决定参数,以使得模型给出最低的损失?这个过程叫做优化,下一节讲解。
更多细节内容https://github.com/cs231n/cs231n.github.io/blob/master/linear-classify.md
向量机论文