目录
介绍
简单的表达式
模块化
反向传播中的模式
多个分支梯度相加
介绍
在本节中,我们将对反向传播(这是一种通过递归的应用链式法则计算梯度表达式的方法)进行直观而专业的理解。理解反向传播的过程以及其中的细节对我们理解,有效开发、设计和调试神经网络至关重要。
问题陈述
本节核心问题是:给定一些函数f(x),x是输入向量。我们着力于计算f在x的梯度。
动机
回想最初我们对这个问题感兴趣的原因,在具体的神经网络中,f对应着损失函数,输入x包含训练数据和神经网络权重。例如损失函数可以使SVM损失函数,输入是训练数据(x_i, y_i),i=1...N和,权重及偏置(W,b)。一般情况下,我们认为训练数据给定且固定,且权重作为我们可以控制的变量。因此,尽管我们可以使用反向传播计算输入样本x_i的梯度,实际中我们经常仅仅计算参数(W,b)的梯度,以便于我们可以使用它来执行参数更新。然而输入x_i的梯度有时也可以发挥作用,例如,为了可视化和翻译神经网络正在做什么。
简单的表达式
我们用一个简单的例子开始,以便于我们为更复杂的表达式定义概念和惯称。
假设函数。这个表达式可以被分解为q = x + y和f = q*z。并且,我们知道如何分开单独计算两个表达式的值,之后利用链式法则计算。我们赋予初始值,表示如下图

计算图如图所示
则香草代码如图所示,绿色表示输入,红色数字表示此处f的梯度值。
# set some inputs
x = -2; y = 5; z = -4
# perform the forward pass
q = x + y # q becomes 3
f = q * z # f becomes -12
# perform the backward pass (backpropagation) in reverse order:
# first backprop through f = q * z
dfdz = q # df/dz = q, so gradient on z becomes 3
dfdq = z # df/dq = z, so gradient on q becomes -4
# now backprop through q = x + y
dfdx = 1.0 * dfdq # dq/dx = 1. And the multiplication here is the chain rule!
dfdy = 1.0 * dfdq # dq/dy = 1反向传播计算梯度如图

每一个节点之前的梯度(即偏导数)等于它的前向梯度乘它的本地梯度。举例,最后一个节点之后的偏导数等于它的前向梯度,即f对自己的偏导数,结果为1。最后一个节点由两输入部分相乘组成,即上箭头所指,和下箭头所指。上箭头的本地梯度z,带入输入值z(如图绿色部分),则本地梯度值为-4,此处梯度值为-4*1。下箭头梯度公式为q,带入q的值,则梯度为-3*1。
另一个节点的的输入由两输入部分相加得到,则节点的上箭头的本地梯度为q对x的偏导数,本体梯度为1,则此处梯度值为-4*1。下箭头的本地梯度为q对y的偏导数,本地梯度为1,则此处梯度值为-4*1。
更复杂的例子如下计算图

模块化
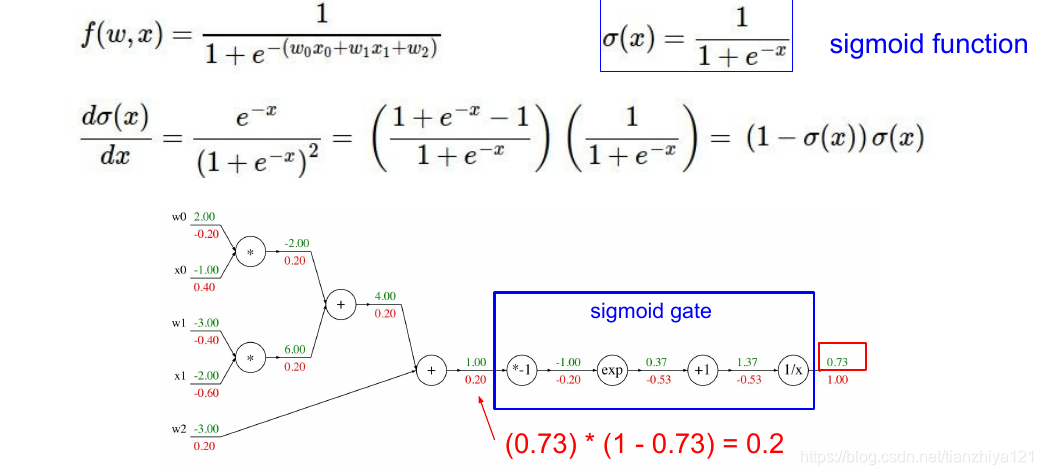
上图中,我们把梯度计算尽可能地分解成最简单的加法和乘法节点。实际上我们可以把一些节点组合在一起,形成更复杂的节点,如果我们想这么做的话,我们需要知道组合节点的本地梯度。例如sigmoid函数,将e的指数看为sigmoid函数输入
则计算如下图变得极为方便。
反向传播中的模式
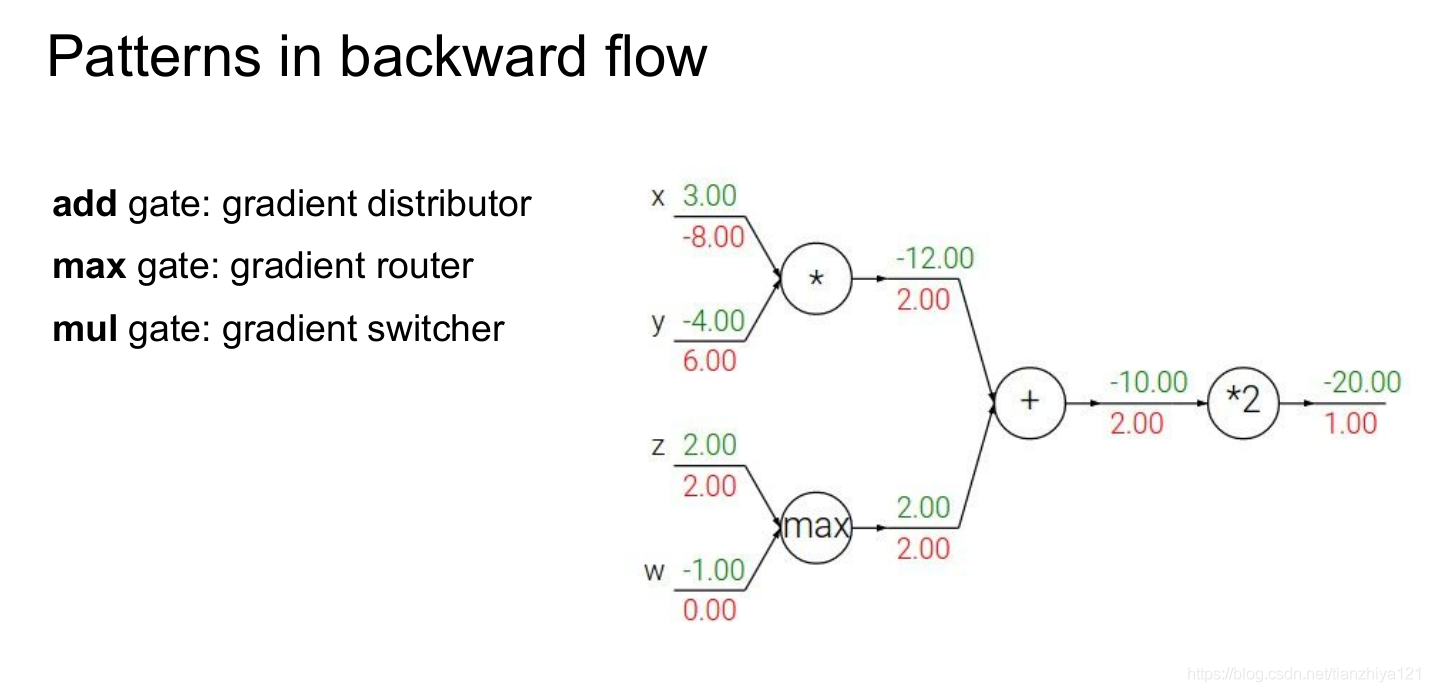
值得注意的是,在许多案例中,反向传播梯度可以在直观层面上解释。例如,三个最常用的门(相加,相乘和求最大值),针对于这些门在反向传播过程中发挥的作用,它们都有各自非常形象的解释。
加法节点的分支梯度(注意是反向传播)等于它的上游梯度,我们可以将计算图加法节点当做梯度分布器,其将上游梯度分布到各个分支。最大值结点在正向传播过程中,仅有最大输入值对输出的影响,在反向过程中(max(a, 0)的在a>=0时候,梯度为1,在梯度小于0的时候,梯度为0),将梯度路由到其中一个分支,这类似路由器的功能。乘法结点将上游梯度通过缩放分步到各输入上,因此乘法结点类似于梯度分布器。
多个分支梯度相加
如果一个节点的输出给n个节点,这个节点的梯度公式如下:

矢量化操作梯度
示例,细节解释见参考

具体见
- https://study.163.com/course/courseLearn.htm?courseId=1004697005&from=study#/learn/video?lessonId=1050180950&courseId=1004697005
- http://cs231n.stanford.edu/vecDerivs.pdf
总结:
- 我们研究了各种梯度的含义,它们是怎样在回路中反向传播,怎样更新。
- 我们讨论了实际中分阶段计算的重要性,我们总是将函数打碎成各种模块,在这些模块中你可以轻易地得到局部梯度并使用链式法则,计算最终结果。更重要的是,我们一点也不想把损失函数的梯度求出来,并一次性计算梯度,我们不需要一个清楚地数学梯度等式。因此,分解表达式到多个阶段以便于你能够独立区分每个阶段。
下一节我们将开始定义神经网络,反向传播将使我们高效得在连接出计算损失函数梯度。换句话说,我们已经准备好训练神经网络。卷及神经网络近在咫尺。