week 1 10/11-10/14
计算机视觉综述:cs231n_2018_lecture01
观看视频p1和p2热身,了解计算机视觉概述以及历史背景。观看p3了解整门课程的大纲。
学习数据驱动的方法和KNN算法和线性分类器[上]:cs231n_2018_lecture02
观看视频p4,p5和p6学习图像分类笔记上(链接:https://zhuanlan.zhihu.com/p/20894041?refer=intelligentunit,图像分类笔记下链接:https://zhuanlan.zhihu.com/p/20900216?refer=intelligentunit )和线性分类笔记上(链接:https://zhuanlan.zhihu.com/p/20918580?refer=intelligentunit )
-->为什么要有验证集
在基于数据进行学习的机器学习算法设计中,超参数是很常见的。一般说来,这些超参数具体怎么设置或取值并不是显而易见的。
你可能会建议尝试不同的值,看哪个值表现最好就选哪个。好主意!我们就是这么做的,但这样做的时候要非常细心。特别注意:决不能使用测试集来进行调优。当你在设计机器学习算法的时候,应该把测试集看做非常珍贵的资源,不到最后一步,绝不使用它。如果你使用测试集来调优,而且算法看起来效果不错,那么真正的危险在于:算法实际部署后,性能可能会远低于预期。这种情况,称之为算法对测试集过拟合。从另一个角度来说,如果使用测试集来调优,实际上就是把测试集当做训练集,由测试集训练出来的算法再跑测试集,自然性能看起来会很好。这其实是过于乐观了,实际部署起来效果就会差很多。所以,最终测试的时候再使用测试集,可以很好地近似度量你所设计的分类器的泛化性能
测试数据集只使用一次,即在训练完成后评价最终的模型时使用。
好在我们有不用测试集调优的方法。其思路是:从训练集中取出一部分数据用来调优,我们称之为验证集(validation set)。以CIFAR-10为例,我们可以用49000个图像作为训练集,用1000个图像作为验证集。验证集其实就是作为假的测试集来调优。
把训练集分成训练集和验证集。使用验证集来对所有超参数调优。最后只在测试集上跑一次并报告结果。
-->交叉验证
有时候,训练集数量较小(因此验证集的数量更小),人们会使用一种被称为交叉验证的方法,这种方法更加复杂些。还是用刚才的例子,如果是交叉验证集,我们就不是取1000个图像,而是将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。
实际应用。在实际情况下,人们不是很喜欢用交叉验证,主要是因为它会耗费较多的计算资源。一般直接把训练集按照50%-90%的比例分成训练集和验证集。但这也是根据具体情况来定的:如果超参数数量多,你可能就想用更大的验证集,而验证集的数量不够,那么最好还是用交叉验证吧。至于分成几份比较好,一般都是分成3、5和10份。

常用的数据分割模式。给出训练集和测试集后,训练集一般会被均分。这里是分成5份。前面4份用来训练,黄色那份用作验证集调优。如果采取交叉验证,那就各份轮流作为验证集。最后模型训练完毕,超参数都定好了,让模型跑一次(而且只跑一次)测试集,以此测试结果评价算法。
线性分类器:在本模型中,我们从最简单的概率函数开始,一个线性映射:

一个将图像映射到分类分值的例子。为了便于可视化,假设图像只有4个像素(都是黑白像素,这里不考虑RGB通道),有3个分类(红色代表猫,绿色代表狗,蓝色代表船,注意,这里的红、绿和蓝3种颜色仅代表分类,和RGB通道没有关系)。首先将图像像素拉伸为一个列向量,与W进行矩阵乘,然后得到各个分类的分值。需要注意的是,这个W一点也不好:猫分类的分值非常低。从上图来看,算法倒是觉得这个图像是一只狗。
-->即W中一行代表一个类别,有多少类,W就有多少行。每一行点乘像素加上偏置就是每类别的分数。
将图像看做高维度的点:既然图像被伸展成为了一个高维度的列向量,那么我们可以把图像看做这个高维度空间中的一个点(即每张图像是3072维空间中的一个点)。整个数据集就是一个点的集合,每个点都带有1个分类标签。
既然定义每个分类类别的分值是权重和图像的矩阵乘,那么每个分类类别的分数就是这个空间中的一个线性函数的函数值。我们没办法可视化3072维空间中的线性函数,但假设把这些维度挤压到二维,那么就可以看看这些分类器在做什么了:
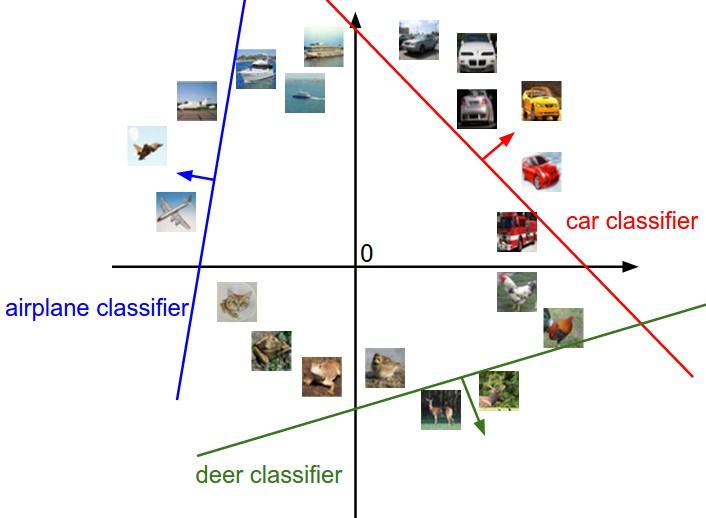
图像空间的示意图。其中每个图像是一个点,有3个分类器。以红色的汽车分类器为例,红线表示空间中汽车分类分数为0的点的集合,红色的箭头表示分值上升的方向。所有红线右边的点的分数值均为正,且线性升高。红线左边的点分值为负,且线性降低。
从上面可以看到,W的每一行都是一个分类类别的分类器。对于这些数字的几何解释是:如果改变其中一行的数字,会看见分类器在空间中对应的直线开始向着不同方向旋转。而偏差b,则允许分类器对应的直线平移。需要注意的是,如果没有偏差,无论权重如何,在时分类分值始终为0。这样所有分类器的线都不得不穿过原点。
图像数据预处理:在上面的例子中,所有图像都是使用的原始像素值(从0到255)。在机器学习中,对于输入的特征做归一化(normalization)处理是常见的套路。而在图像分类的例子中,图像上的每个像素可以看做一个特征。在实践中,对每个特征减去平均值来中心化数据是非常重要的。在这些图片的例子中,该步骤意味着根据训练集中所有的图像计算出一个平均图像值,然后每个图像都减去这个平均值,这样图像的像素值就大约分布在[-127, 127]之间了。下一个常见步骤是,让所有数值分布的区间变为[-1, 1]。零均值的中心化是很重要的,等我们理解了梯度下降后再来详细解释。
作业:
1.阅读python和numpy教程(链接:https://zhuanlan.zhihu.com/p/20878530?refer=intelligentunit )和代码(https://github.com/sharedeeply/cs231n-camp/blob/master/tutorial/python_numpy_tutorial.ipynb )写一个矩阵的类,实现矩阵乘法,只能使用 python 的类(class)和列表(list)。
2. 完成assignment1中的knn.ipynb