目录
基础神经网络
常用非线性函数
基础神经网络
在线性分类中,我们不同视觉类别的得分函数是通过,W是权重矩阵,x是一个输入列向量。在神经网络中,我们计算的是
,如图所示结构。

函数max(0,x)是一个非线性化函数,其作用于输入的每个像素。像这样的非线性化函数有许多,但这个是一个常用的选择,其将所有的输入小于零的值归零,其他不变。如上图,假设输入shape为[1*3072],最终的size[100*100],最终我们得到10个类别得分。
非线性函数
每一个输入函数接受一个数字作为输入,并且对数字执行特定的数学操作。这里介绍一些实际中可能也遇到的激活函数。

1、Sigmoid
Sigmoid非线性化压缩输入值域到[0,1]。
sigmoid过去常常被使用,因为它可以被看做神经元的饱和放电率。但如今已经过时了。它主要由两个缺点:
- Sigmoid饱和并杀死梯度:sigmoid函数一个非常不理想的特性。当神经元饱和要么在0,要么在1,梯度在这些区域近乎为零。反向传播过程,本地梯度将会乘以门控输出梯度。因此,如果本地梯度非常小,它将会杀死梯度并且几乎没有更新权重信号能够流动在神经网络。例如初始权重太大,神经元将会饱和,神经网络很难学习到有用信息。如下图

当x=-10输出为0,则本体梯度可以计算为0,则最终梯度几乎为零。由此,此节点之后,更多节点梯度将被其杀死。x=10同理

- sigmoid输出非零中心zero-centered。zero-centered指的是数据有正有负,以零为中心分布。(数据处理中常常用减去均值的办法,使得每个数据达到zero-centered)对于sigmoid函数,在误差反向传播的过程中,我们可以得到其导数:
,则
的符号与输入保持一致。假设现在有w1、w2,为了达到最优的参数,当前的权值需要增大、减小,然而因为输入全为正值或者负值,导致二者更新方向总是同时增大或者同时减小,优化过程将会变为zig--zag过程。如下图

如果输入神经网络的数据都是正数,。最终求得的梯度要么全都是正数,要么全都是负数,相当于把上游的符号传下来。
如果训练的数据并不是“零为中心”,我们将多个或正或负的梯度结合起来就会使这种情况有所缓解,但是收敛速度会非常缓慢。该问题相对于神经元饱和问题来说还是要好很多。具体可以这样解决,我们可以按batch去训练数据,那么每个batch可能得到不同的信号或正或负,这个批量的梯度加起来后可以缓解这个问题。
- sigmoid中指数函数的计算比较消耗资源。
2、Tanh函数
tan函数表达式
导数
![]()
tanh非线性化函数及其导数如下图,黄色线表示tanh函数,蓝色线表示其导数

tanh函数与Sigmoid函数对比
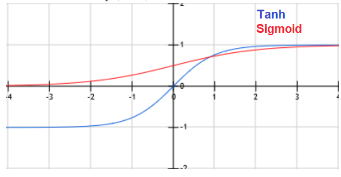
由图看出tanh函数相比于Sigmoid特点:
- tanh将输入压缩到[-1,1]之间
- 输出值以0为中心
- 依然在饱和的时候杀死梯度
3.Relu函数
函数表达式

函数导数
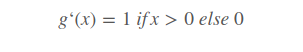

Relu函数特点:
- 以0为界,负值为0,正值为等值大小;导数是负值为0,正值为
优点:
- 在输入为正时候避免了梯度消失,从而计算SGD时速度比较快
缺点
- 依然输出有非0为中心的问题
- 在输入为负(x=0时候梯度为零)时,会产生梯度消失问题。
dead Relu原因
- 你的初始权重设置的特别差,导致大部分数据为负。
- 当你的学习率很大时候,权值不断波动,当有一个较大的梯度传来,导致w的分布改变。Relu开始正常,之后变差最后挂掉。参考
多数时候人们将Relu偏置设为0
4.Leaky Relu
表达式,如下图绿色表示原图,红色表示其导数图像

Leaky Relu特点:
- 当x<0,y不再为0,而是一个比例函数
优点:
- 理论上有Relu的一切优点,并且去除了‘Dyling Relu’问题。
缺点:
- 实际中的表现并非如理论那般那么好
5.PRelu
表达式,0<a<1。PRelu将LRelu的参数0.01替换为a,将它当做一个可以反向传播和学习的参数,这给与了它更多的灵活性。
6.ELU
指数线性单元ELU
表达式

特点:
- 当x<0时候,y为指数函数
- 理论上由Relu一切优点,去除了Dying Relu,同时输出近似zero-centered
缺点:
计算耗时
建议使用Relu,注意权重初始化和学习率大小设置。
