全连接神经网络结构基础介绍
全连接层级组织
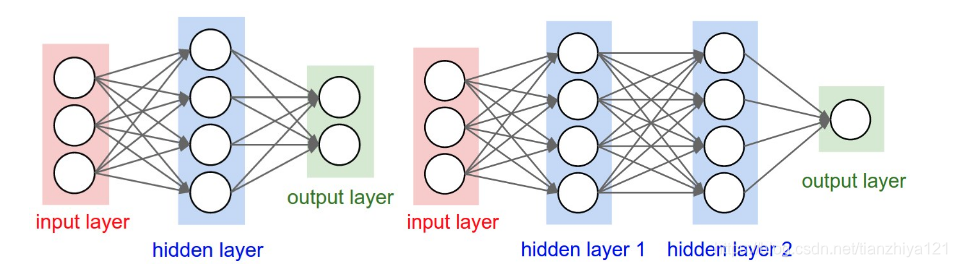
神经网络被建模为一系列相互连接单不循环的神经元的集合。即一些神经元的输出可以变为其他神经元的输入。对于常规神经元,最普通的层类型是全连接神经网络,其相互连接的两个层完全成对连接。但如果模型仅仅一层网络,则没有连接。下图展示两个拓扑图,用于表示全连接神经元的堆积。
 图片来源
图片来源
如上图,左边表示一个2层神经网络(隐藏层含有4个神经元,输出层由2个神经元)。右边是一个3层神经网络,仅仅比左边多了一个隐藏层。
命名约定:在我们说N层神经网络的时候,我们一般不把输入层计算在内。因此,一个单层神经网络描述着没有隐藏层的神经网络(直接输入输出)。有时,我们会听到人们说,逻辑回归或者SVMs仅仅是一个单层神经网络的特殊案例。有人也称这些网络也可以互换称为人工神经网络(ANN)或者多层感知机(MLP)。
输出层:不像神经网络其它层,输出层神经元一般不需要一个激活函数(或者你可以认为他们有一个线性激活函数)。
神经网络的尺寸:衡量神经网络的大小通常有两种方法,要么是通过神经元的个数,要么是一般参数的数量。例如上图中:
- 左边的神经网络 右4+2个神经元(不计算输入),[34]+[42]=20权重并且4+2=6个偏置,总共26个可学习的参数。
- 右边的神经元有4+4+1=9个神经元,[34]+[44]+[4*1]=12+16+4=32个权重和4+4+1=9个权重,总共41个可学习参数。
背景信息:现代卷及神经网络一般包含1亿个参数且常常有10-20层。
前向传播计算
重复的矩阵相乘交织着激活函数。神经网络有着这种结构的一个重要原因就是,它使得使用矩阵向量操作评估神经网络变得非常简单有效。
import numpy as np
f = lambda x:1.0/(1.0 + np.exp(-x))
x = np.random.randn(3, 1)
w1 = np.random.randn(3, 4)
w2 = np.random.randn(4, 4)
w3 = np.random.randn(4, 2)
b1, b2, b3 = 0, 0, 0
h1 = f(np.dot(w1.T, x) + b1)
h2 = f(np.dot(w2.T, h1) + b2)
out = np.dot(w3.T, h2) + b3
print(out)#[[-0.74313399], [-0.28903481]]
表现力
我们可以认为,全连接神经网络定义了一个集合函数家族,函数通过网络全中参数化。一个自然的问题是:这个集合函数家族为什么可以有建模作用?它可以用神经网络建模任何函数吗?
结论是,至少拥有一个隐藏层的神经网络是通用的逼近器( 更多参见Approximation by Superpositions of Sigmoidal Function from 1989 (pdf))。
或者 intuitive explanation
存在一个神经网络,其有着一个合理的非线性化函数的隐藏层,它可以逼近任何连续性函数。
问题接踵而来,如果一个隐藏层就可以逼近任何函数,为什么使用更多的层并且走向更深呢?答案是,一个两层的神经网络是一个通用的逼近器,尽管在数学上看起来很合理,但在实际中表现不尽如人意。更深层次的神经网络可以表现更好是由经验得来,尽管数学上是它的表现力和一层神经网络相同。
旁白:实际中,一般3层的神经网络效果会超过2层,但是更深的话基本不会有什么帮助了。这和卷积网络形成鲜明对比。在卷积神经网络中,深度被发现是一个非常重要的成分,其对最终的识别分类等任务有着极为重要的作用。一种观点是图像包含着分层结构(一张脸包含着眼睛,而眼睛又包含着颜色和角点等),而卷积神经网络的不同层可以提取不同层次的特征。更多关于相关话题参见:
- Deep Learning book in press by Bengio, Goodfellow, Courville, in particular Chapter 6.4.
- Do Deep Nets Really Need to be Deep?
- FitNets: Hints for Thin Deep Nets
如何设置层数和每层神经元个数
如何根据实际问题决定使用那种结构?如何设置隐层个数?每个隐层应该有多少神经元?首先,当我们提升层数和层大小时候,神经网络的表现力增加。伴随着可表现的函数空间增长,神经元可以聚集来表现不同的函数。举例,下图中显示一个二分类问题
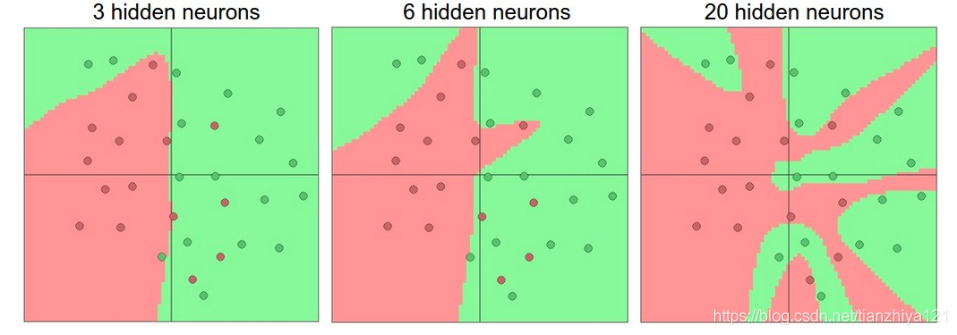
神经网络可以你和更加复杂的函数。图中不同颜色的圆圈表示不同的类别,上图显示了受过训练的神经网络的决策区域。你可以在ConvNetsJS demo自己尝试下。
在上图中,我们可以看到,更多的神经元可以表示更加复杂的函数。然而这既是一种祝福也是第一种诅咒。更多的神经元可以让我们分类更加复杂的数据,但是也更容易过拟合。过拟合发生在有着强大能力的模型拟合了数据中过多的噪声,而不是例如分类特征这样的特征。例如上图中,含有20个隐藏层的神经元拟合了所有的训练数据,但是代价是将数据空间分成了许多不规则的红色和绿色区域。拥有三个神经元的模型将数据区分成两大集中块,它将少数的在绿色区域中的红色点判断为噪声。在实际中,这在测试集上将导致更好的泛化效果。
基于以上讨论,看起来似乎如果数据不是很复杂,使用小型的神经网络足够避免过拟合。但实际上这是不正确的做法,有许多方法可以避免过拟合,例如L2 regularization,dropout,input noise等。实际中最好使用这些方法控制过拟合,而不是小型神经元。原因是小型的神经网络很难使用梯度下降法训练:显而易见的是网络损失函数有一些局部最小值,但是实验证明,小型模型很容易收敛到这些局部最小值点,通常这些点的损失函数很高。相反,虽然更大的神经网络有着更多的局部最小值,但是这些最小值表现更好一些。因为神经网络是非凸的,很难从数学上研究这些属性,但是在理解目标函数方面已经做了很多努力。例如, The Loss Surfaces of Multilayer Networks
。
减少过拟合:正则化举例
相对于重复迭代,正则化是更好地控制过拟合的方法。如下图所示,不同的正则化参数设置,导致不同的效果
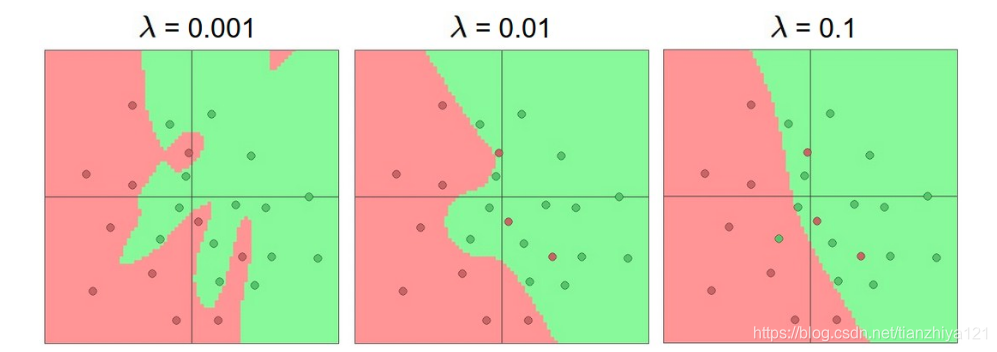
通过正则化操作,可以使得最终的决定区域更加平缓。一般建议,模型不要使用太浅层的神经元。如果条件允许,使用较大型的神经网络,并且使用正则化来控制过拟合。
总结
- 介绍了多种激活函数以及各自的优缺点
- 介绍了全连接神经网络的概念以及其通用逼近器概念,以及示例
- 探讨了一些实验中使用全连接神经网络的经验
- 比较小型的网络和大型的网络的优缺点。
Additional References
deeplearning.net tutorial with Theano
http://cs.stanford.edu/people/karpathy/convnetjs/
http://neuralnetworksanddeeplearning.com/chap1.html