学习视频:
鲁鹏-计算机视觉与深度学习
1 图像分类任务
图像分类任务是计算机视觉的核心任务,其目标是根据图像信息中所反映的不同特征,把不同类别的图像区分开来。

比如这只狗,我们的目的是给计算机一些选项,比如说猫、狗、飞机、车,让计算机看到这张图片,并得出“这是一只狗”的结论。给出一些猫、飞机、车的图片,机器也能够分类正确。能做到这一点的机器,可以被称作是一种“分类器”。
2 数据驱动的图像分类方法
分为以下三步:
- 数据集构建
- 分类器设计与学习
- 分类器决策
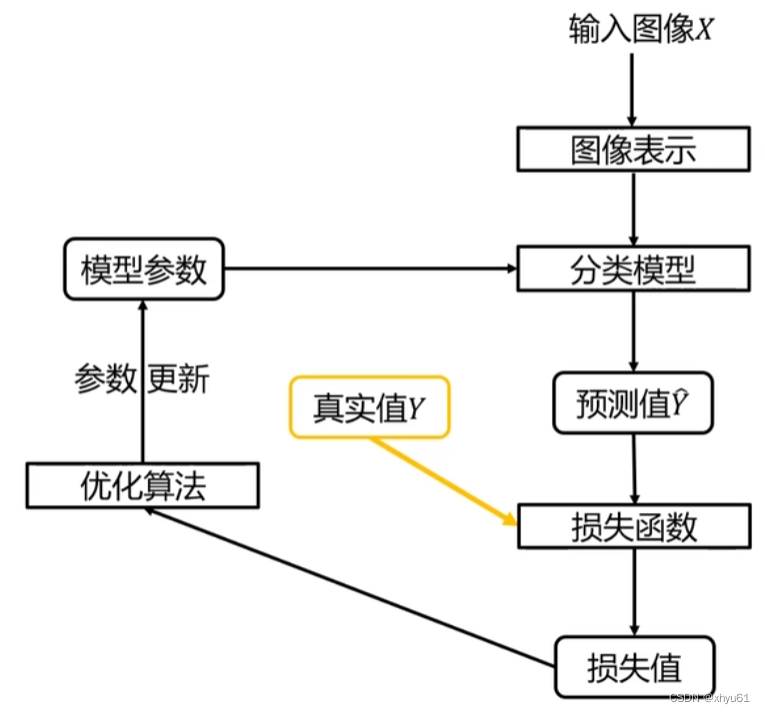
分类器的学习过程图:
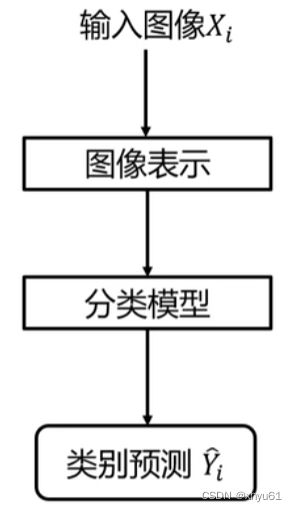
分类器的决策过程图:
3 图像表示方法
3.1 像素表示
根据RGB的原理,图片中的每一个像素的颜色都可以用一个三元组来表示。假设我们要表示的图像为 n × m n\times m n×m的大小的图像,那么就可以用 3 × n × m 3\times n\times m 3×n×m维向量来表示这张图像。
3.2 全局特征表示(如GIST)
通过提取整张图像中的全部像素体现出来的特征来表征图像,目的是降低维度。全局提取特征的方法适用于景色类图像的分类,细节较多的分类效果不好。
3.3 局部特征表示(如SIFT)
通过提取整张图像中的部分特征点来表示图像,如人脸识别,识别出两个眼睛一个嘴巴一个鼻子作为特征,这时挡住一个眼睛,也能够做一个较好的判断。同样的场景用于全局特征表示方法,由于其使用所有的像素作为特征提取,去掉一个眼睛会对数据造成很大的变化,导致失败率很高。
4 图像分类任务的评价指标
4.1 正确率与错误率
正确率(accuracy) = 分对的样本数 / 全部样本数
错误率(error rate) = 1 - 正确率
4.2 Top1指标与Top5指标
对于同一张图片,分类器给出其得出的五个最有可能正确的答案,并将他们按照正确的可能性从大到小排序。
Top1指标:可能性最大的答案正确,才被认为分类正确。
Top5指标:可能性最大的五个答案中有正确答案,即被认为分类正确。
5 线性分类器
5.1 图像表示
课程中采用的图像表示方法为像素表示法,将图像的每一个像素的颜色用一个三元组 ( x i , y i , z i ) (x_i, y_i, z_i) (xi,yi,zi)表示,其中 0 ≤ x i , y i , z i ≤ 255 0\leq x_i, y_i, z_i \leq 255 0≤xi,yi,zi≤255。然后将所有点的 x i , y i , z i x_i,y_i,z_i xi,yi,zi依次排开,假设图像有 n n n个点,那么构造一个向量 x \mathbf{x} x(本系列笔记中会将代表向量的数学符号像这样加粗):
x = [ x 0 y 0 z 0 x 1 y 1 z 1 ⋮ ] \mathbf{x} = \begin{bmatrix} x_0 \\ y_0 \\ z_0 \\ x_1 \\ y_1 \\ z_1 \\ \vdots \end{bmatrix} x= x0y0z0x1y1z1⋮
当所选用的图像是 32 × 32 32\times 32 32×32时,所得到的 x \mathbf{x} x就是一个 32 × 32 × 3 = 3072 32\times 32\times 3=3072 32×32×3=3072维的向量。
5.2 简介
线性分类器是一种线性映射,将输入的图像特征映射为类别函数。
设 x \mathbf{x} x为输入的 d d d维图像向量, c c c为类别个数。对于第 i i i个类别的线性分类器,我们有:
f i ( x , w i ) = w i T x + b i , i = 1 ⋯ c f_i(\mathbf{x},\mathbf{w}_i)=\mathbf{w}_i^T \mathbf{x}+b_i,\ i=1\cdots c fi(x,wi)=wiTx+bi, i=1⋯c
f i f_i fi为第 i i i个类的线性分类器的打分。 w i = [ w i 1 w i 2 ⋯ w i d ] T \mathbf{w}_i=\begin{bmatrix} w_{i1} & w_{i2} & \cdots & w_{id} \end{bmatrix} ^T wi=[wi1wi2⋯wid]T是一个列向量表示第 i i i个类别的权值向量, b i b_i bi为偏置。
得到的 f i f_i fi是一个常数(不难看出, w i T \mathbf{w}_i^T wiT是 1 × d 1\times d 1×d的, x \mathbf{x} x是 d × 1 d\times 1 d×1的)。
对于每一个类别,都有属于自己的 x \mathbf{x} x和 b b b。通过公式可以看出,求解分数的这个变换是线性的,所以这个分类器叫做线性分类器。
5.3 决策规则
如果 f i ( x ) > f j ( x ) , ∀ j ≠ i f_i(\mathbf{x})>f_j(\mathbf{x}), \forall j\neq i fi(x)>fj(x),∀j=i,则决策输入图像 x \mathbf{x} x输入第 i i i类。
其实就是通过线性分类器对这个图像打完分以后,哪一个类别的分数最高,就认为这张图像属于哪一个类别。
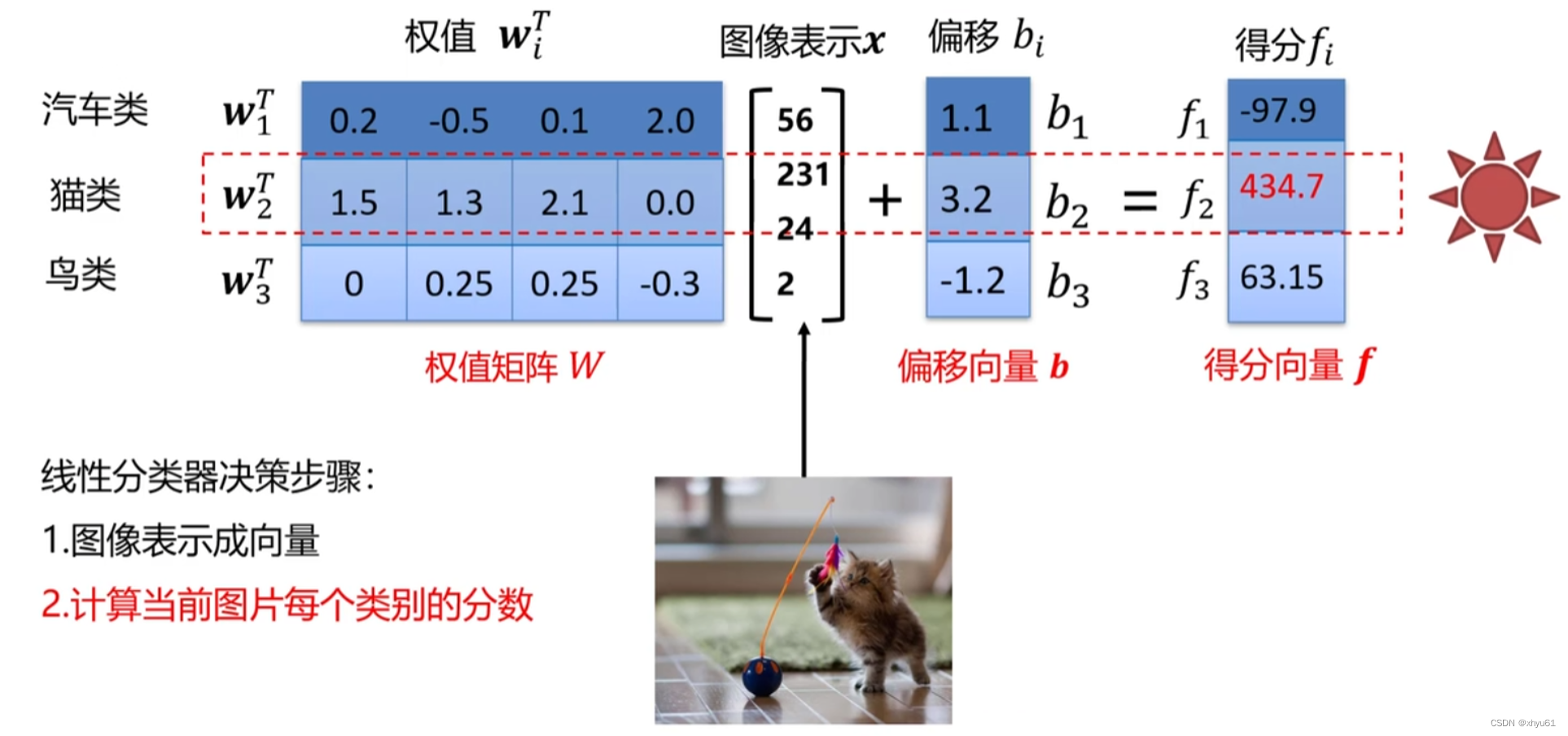
如图所示,将 i i i个类别的权值向量并到一起可以形成一个权值矩阵 W \mathbf{W} W,将每一个类的偏移构成一个便宜向量 b \mathbf{b} b,将每一个类最后得到的得分构成一个得分向量 f \mathbf{f} f。于是不同于刚刚针对一个类的转移式,我们可以写出一个对于一整个线性分类器的向量转移式:
f ( x , W ) = W x + b \mathbf{f}(\mathbf{x},\mathbf{W})=\mathbf{W}\mathbf{x}+\mathbf{b} f(x,W)=Wx+b
5.4 权值
线性分类器的权值可以看做是一个模板,每一个类别通过学习给定的图像,不断调整其中的数值,使其数值更加贴合对应类别的特征。比如说一个具有10个类别的线性分类器,训练后的模板长这个样子:

其模板若隐若现能看出对应类别的图像,但由于是对很多图片的统合学习,所以会出现 w 8 \mathbf{w}_8 w8这样子的两个头的马(有的图片马头朝左,有的图片马头朝右导致的)。
输入图像与评估模板的匹配程度越高,分类器输出的分数就越高。
5.5 决策边界
假设我们只用 2 2 2个特征来表征一个图像,通过画分界面将图片分类开来,大概是这样:
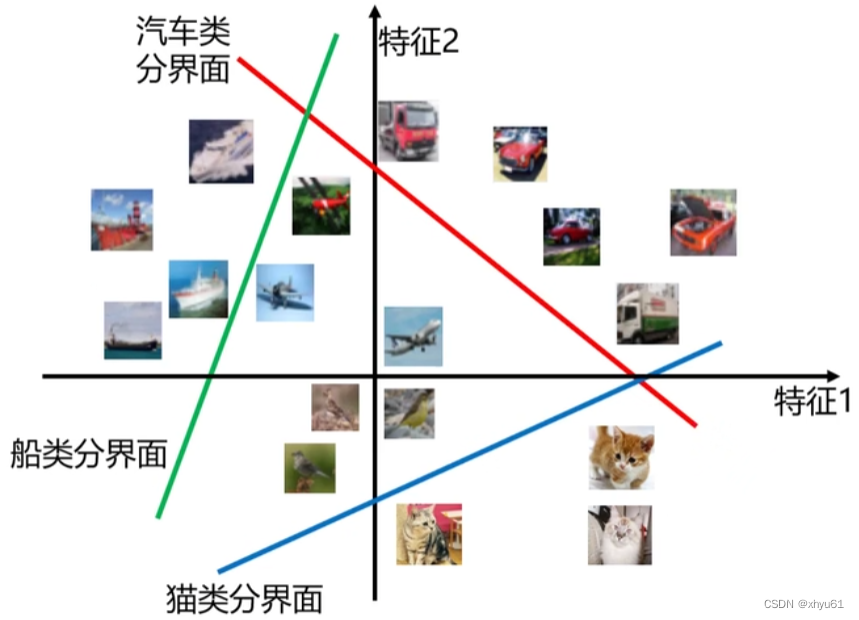
分数为 0 0 0的线就是分界面, w i x + b i = 0 , i = 1 ⋯ c \mathbf{w}_i \mathbf{x}+b_i=0, \ i=1 \cdots c wix+bi=0, i=1⋯c。
因为只有分数大于 0 0 0,这个图像才有可能为这个类别,假设汽车类分界面,相当于一侧包含所有可能为汽车的图像,而另一侧没有。
我们对线性分类器学习,主要是学习权值矩阵 W \mathbf{W} W和偏置向量 b \mathbf{b} b,换句话说就是在学习这个分界面。
5.6 损失函数
找到最优的分类模型,还需要损失函数与优化算法的帮忙。我们通过损失函数来判断当前模型的预测情况。具体来说,就是使用测试集对分类器进行测试,观察分类器得出的结果和实际结果的差距,并用损失函数量化表达出来。
损失函数搭建了模型性能和模型参数之间的桥梁,指导模型进行参数优化。具体地说,损失函数是一个函数,用于度量给定分类器的预测值与真实值的不一致程度,其输出通常是一个非负实值。
其输出的非负实值可以作为反馈信号来对分类器参数进行调整,以降低当前示例对应的损失值,提升分类器的分类效果。
损失函数的一般定义
L = 1 N ∑ i L i ( f ( x i , W ) , y i ) L=\frac{1}{N}\displaystyle\sum\limits_{i} L_i(f(\mathbf{x}_i,\mathbf{W}),y_i) L=N1i∑Li(f(xi,W),yi)
其中 x i x_i xi表示数据集里面第 i i i张图片; f ( x i , W ) f(x_i,W) f(xi,W)为分类器对 x i x_i xi的类别预测; y i y_i yi是该图片的真实类别; L i L_i Li为第 i i i个样本的预测损失值; L L L为数据集的损失,它是数据集中所有样本损失的平均。
多类支撑向量机损失
s i j = f i ( x i , w j , b j ) = w j T x i + b j s_{ij}=f_i(\mathbf{x}_i,\mathbf{w}_j,b_j)=\mathbf{w}_j^T\mathbf{x}_i+b_j sij=fi(xi,wj,bj)=wjTxi+bj
这个式子中的部分字母和前面所述不同:
j j j:类别标签,取值范围为 { 1 , 2 , ⋯ , c } \{1,2,\cdots,c\} {
1,2,⋯,c}
w j , b j \mathbf{w}_j, b_j wj,bj:第 j j j个类别的权值向量与偏置参数
x i \mathbf{x}_i xi:表示数据集里第 i i i个样本
s i j s_{ij} sij:第 i i i个样本第 j j j类别的预测分数
第 i i i个样本的多类支撑向量机损失定义如下:
L i = ∑ j ≠ y i { 0 i f s y i ≥ s i j + 1 s i j − s y i + 1 o t h e r w i s e = ∑ j ≠ y i max ( 0 , s i j − s y i + 1 ) \begin{aligned} L_i &= \displaystyle\sum\limits_{j\neq y_i} \begin{cases} 0 \qquad & if \ s_{y_i}\geq s_{ij}+1 \\ s_{ij}-s_{y_i}+1 \qquad & otherwise \end{cases} \\ &=\displaystyle\sum\limits_{j\neq y_i} \max (0, s_{ij}-s_{y_i}+1) \end{aligned} Li=j=yi∑{ 0sij−syi+1if syi≥sij+1otherwise=j=yi∑max(0,sij−syi+1)
其中 s y i s_{y_i} syi为第 i i i个样本真实类别的预测分数。
正确类别的得分比不正确类别的得分高出1分,就没有损失;否则,就会产生损失。
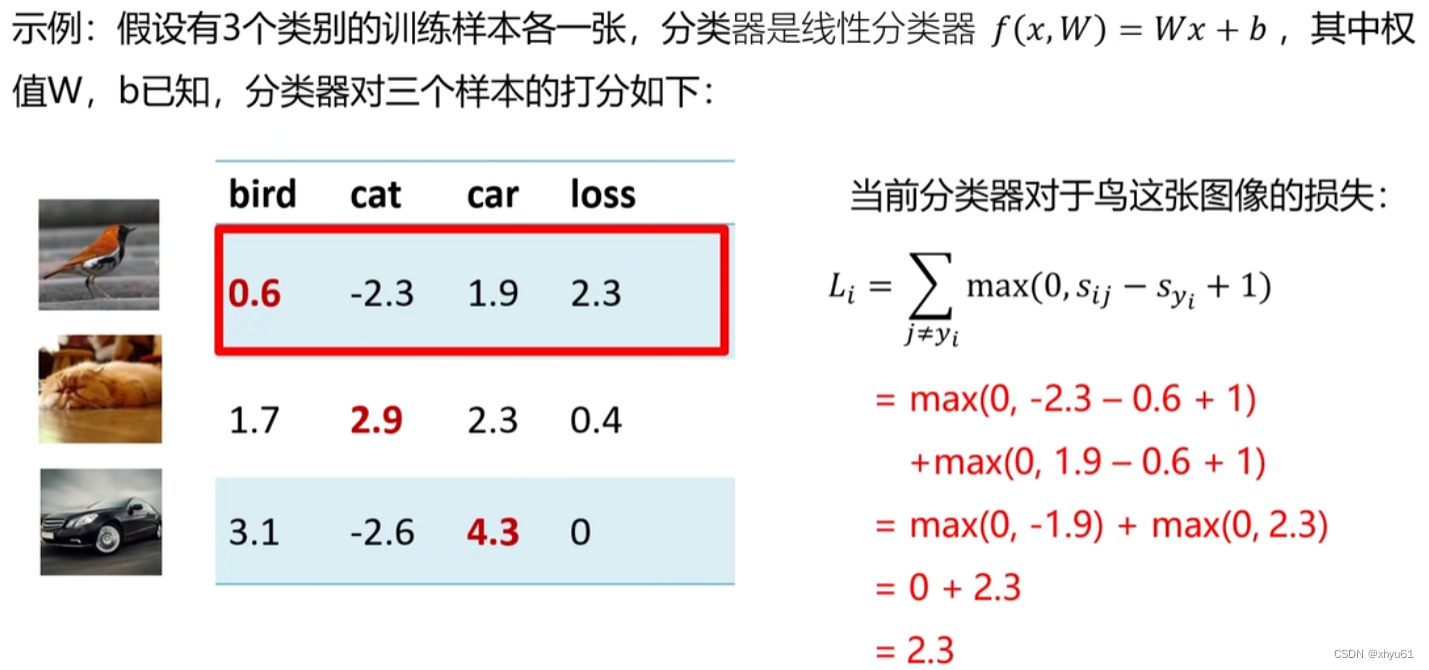
思考:
问 多类支撑向量机损失 L i L_i Li的最大/最小值会是多少?
答 预测非常离谱(分值打到了无穷大的极端情况)时预测值可以达到无穷大;完全预测正确时达到最小值 0 0 0。
问 如果初始化时 w \mathbf{w} w和 b b b很小,损失 L L L会是多少?
答 有 c c c个类别时,令 w \mathbf{w} w和 b b b中的全部权值取 0 0 0,得到 s i j s_{ij} sij和 s y i s_{y_i} syi为 0 0 0,代入式中得到 L = c − 1 L=c-1 L=c−1。该特性可以用来检测代码编写是否正确。
问 考虑所有类别(包括 j = y i j=y_i j=yi),损失 L i L_i Li会有什么变化?
答 最终结果会比原来增加 1 1 1,不会对结果又太大影响,也因此不采用 j = y i j=y_i j=yi。
问 在总损失 L L L计算时,如果用求和代替平均?
答 根据公式,相当于结果乘上 N N N,对结果本身不产生影响。
问 如果使用 L i = ∑ j ≠ y i max ( 0 , s j − s y i + 1 ) 2 L_i= \displaystyle\sum\limits_{j\neq y_i} \max(0,s_j-s_{y_i}+1)^2 Li=j=yi∑max(0,sj−syi+1)2?
答 大于 1 1 1的损失被放大,小于 1 1 1的损失被缩小,本质上的损失函数会产生一些差异,影响模型优化,可能会出现不同的结果。
问 假设存在一个 W \mathbf{W} W使得损失函数 L = 0 L=0 L=0,这个 W \mathbf{W} W是唯一的吗?
答 不是。
5.7 正则项与超参数
通过5.6节的思考中最后一个问题可以得知,可能会存在多种情况,使得损失函数 L = 0 L=0 L=0,这时我们需要用一种方法来判断哪一种更好,或者说找到一种方法去选择。
做法:在损失函数公式后面加入一个正则项。
L = 1 N ∑ i L i ( f ( x i , W ) , y i ) + λ R ( W ) L=\frac{1}{N}\displaystyle\sum\limits_{i} L_i(f(\mathbf{x}_i,\mathbf{W}),y_i)+\lambda R(\mathbf{W}) L=N1i∑Li(f(xi,W),yi)+λR(W)
式中 λ R ( W ) \lambda R(\mathbf{W}) λR(W)为正则项。
其中我们将 1 N ∑ i L i ( f ( x i , W ) , y i ) \frac{1}{N}\displaystyle\sum\limits_{i} L_i(f(\mathbf{x}_i,\mathbf{W}),y_i) N1i∑Li(f(xi,W),yi)称作数据损失,模型预测需要和训练集相匹配;将 λ R ( W ) \lambda R(\mathbf{W}) λR(W)称作正则损失,防止模型在训练集上学习得“太好”。
R ( W ) R(\mathbf{W}) R(W)是一个与权值有关,跟图像无关的函数。
λ \lambda λ是一个超参数,控制着正则损失在总损失中所占的比重。
超参数
超参数是学习过程之前设置的参数,而不是学习中得到的。超参数一般都会对模型的性能有重要的影响。
观察
L = 1 N ∑ i L i ( f ( x i , W ) , y i ) + λ R ( W ) L=\frac{1}{N}\displaystyle\sum\limits_{i} L_i(f(\mathbf{x}_i,\mathbf{W}),y_i)+\lambda R(\mathbf{W}) L=N1i∑Li(f(xi,W),yi)+λR(W)
当 λ = 0 \lambda = 0 λ=0时,优化结果仅与数据损失相关。
当 λ = ∞ \lambda = \infty λ=∞时,优化结果与数据损失无关,仅考虑权重损失。此时,系统最优解为 W = 0 \mathbf{W}=\mathbf{0} W=0。
L2正则项
R ( W ) = ∑ k ∑ l W k , l 2 R(\mathbf{W})=\displaystyle\sum\limits_{k}\displaystyle\sum\limits_{l} W_{k, l}^2 R(W)=k∑l∑Wk,l2
举例说明

L2正则损失对大数值权值进行惩罚,喜欢分散数值,鼓励分类器将所有维度的特征都用起来,而不是强烈的依赖其中少数几维特征。
正则项让模型有了偏好!
常用的正则项
L1正则项: R ( W ) = ∑ k ∑ l ∣ W k , l ∣ R(\mathbf{W})=\displaystyle\sum\limits_{k}\displaystyle\sum\limits_{l} |W_{k, l}| R(W)=k∑l∑∣Wk,l∣
L2正则项: R ( W ) = ∑ k ∑ l W k , l 2 R(\mathbf{W})=\displaystyle\sum\limits_{k}\displaystyle\sum\limits_{l} W_{k, l}^2 R(W)=k∑l∑Wk,l2
Elastic net(L1+L2): R ( W ) = ∑ k ∑ l β W k , l 2 + ∣ W k , l ∣ R(\mathbf{W})=\displaystyle\sum\limits_{k}\displaystyle\sum\limits_{l} \beta W_{k, l}^2 + |W_{k, l}| R(W)=k∑l∑βWk,l2+∣Wk,l∣
5.8 参数优化
参数优化是机器学习的核心步骤之一,它利用损失函数的输出值作为反馈信号来调整分类器参数,以提升分类器对训练样本的预测性能。
损失函数 L = 1 N ∑ i = 1 N L i + λ R ( W ) L=\frac{1}{N}\displaystyle\sum\limits_{i=1}^N L_i + \lambda R(\mathbf{W}) L=N1i=1∑NLi+λR(W),是一个与参数 W \mathbf{W} W有关的函数,优化的目标是找到使损失函数 L L L达到最优的那组参数 W \mathbf{W} W。
有直接方法: ∂ L ∂ W = 0 \frac{\partial L}{\partial W}=0 ∂W∂L=0
但由于 L L L形式一般很复杂,很难求解,因此提出梯度下降算法。
梯度下降算法
梯度下降算法是一种简单而高效的迭代优化算法。
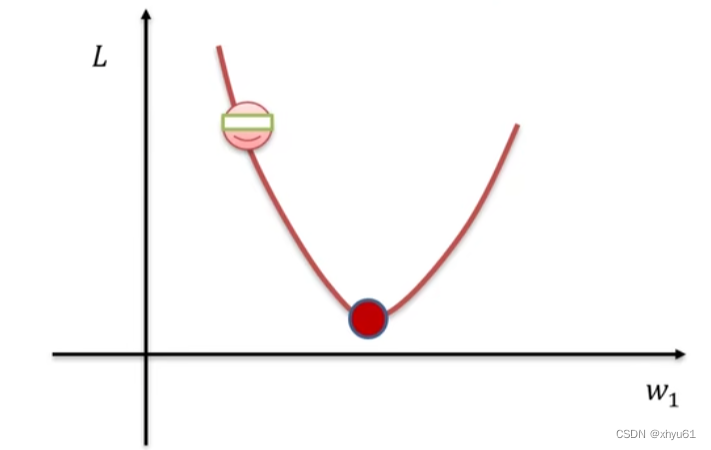
如图所示,红色点左上角的蒙上眼睛的笑脸是我们当前的位置。假设当前我们在 L L L函数的图像上遇到了一个极值点,我们通过一点一点向着往下的坡的方向去移动。于是有两个问题:
- 往哪儿走?——负梯度方法
- 要走多远?——步长来决定
梯度下降:利用所有样本计算损失并更新梯度。
while true
权值的梯度 ← 计算梯度(损失、训练样本、权值)
权值 ← 权值 - 学习率 * 权值的梯度
数值法
一维变量,函数求导:
d L ( w ) d w = lim h → 0 L ( w + h ) − L ( w ) h \frac{dL(w)}{dw}=\displaystyle\lim\limits_{h\rightarrow 0} \frac{L(w+h)-L(w)}{h} dwdL(w)=h→0limhL(w+h)−L(w)
解析法
示例:损失函数 L ( w ) = w 2 L(w)=w^2 L(w)=w2,求 w = 1 w=1 w=1点处的梯度。
∇ L ( w ) = 2 w \nabla L(w)=2w ∇L(w)=2w
∇ w = 1 L ( w ) = 2 \nabla_{w=1} L(w)=2 ∇w=1L(w)=2
解析法精确、快速,但是导数函数推导易错。
一般求解梯度使用解析法,通过数值法验证(梯度检查)。
如何计算多类支撑向量机损失的导数函数?
L i = ∑ j ≠ y i max ( 0 , s i j − s y i + 1 ) L_i= \displaystyle\sum\limits_{j\neq y_i} \max(0,s_{ij}-s_{y_i}+1) Li=j=yi∑max(0,sij−syi+1)
将 s i j = w j T x i + b j s_{ij}=\mathbf{w}_j^T \mathbf{x}_i +b_j sij=wjTxi+bj代入上式,得到:
L i = ∑ j ≠ y i max ( 0 , w j T x i + b j − w y i T x i + b y i + 1 ) L_i= \displaystyle\sum\limits_{j\neq y_i} \max(0,\mathbf{w}_j^T \mathbf{x}_i +b_j-\mathbf{w}_{y_i}^T \mathbf{x}_i +b_{y_i}+1) Li=j=yi∑max(0,wjTxi+bj−wyiTxi+byi+1)
现尝试通过解析法求解,我们先以简单例子入手:假设 y = max ( 0 , w 2 − 1 ) y=\max(0, w^2-1) y=max(0,w2−1),那么有
∂ y ∂ w = { 2 w i f w 2 − 1 ≥ 0 0 o t h e r w i s e \frac{\partial y}{\partial w}= \begin{cases} 2w \qquad & if \ w^2-1 \geq 0 \\ 0 \qquad & otherwise \end{cases} ∂w∂y={
2w0if w2−1≥0otherwise
同理,对于我们要求的 ∂ L i ∂ w j \frac{\partial L_i}{\partial \mathbf{w}_j} ∂wj∂Li,也可以分段:
当 w j T x i + b j − w y i T x i + b y i + 1 < 0 \mathbf{w}_j^T \mathbf{x}_i +b_j-\mathbf{w}_{y_i}^T \mathbf{x}_i +b_{y_i}+1<0 wjTxi+bj−wyiTxi+byi+1<0时,有 ∂ L i ∂ w j = 0 \frac{\partial L_i}{\partial \mathbf{w}_j}=0 ∂wj∂Li=0。
当 w j T x i + b j − w y i T x i + b y i + 1 ≥ 0 \mathbf{w}_j^T \mathbf{x}_i +b_j-\mathbf{w}_{y_i}^T \mathbf{x}_i +b_{y_i}+1\geq0 wjTxi+bj−wyiTxi+byi+1≥0时,有 ∂ L i ∂ w j = x i \frac{\partial L_i}{\partial \mathbf{w}_j}=\mathbf{x}_i ∂wj∂Li=xi。这个导数涉及到了矩阵求导,推导过程如下:
观察 L i L_i Li式中只有 w j T x i \mathbf{w}_j^T \mathbf{x}_i wjTxi这一项与 w j \mathbf{w}_j wj有关,其他的都可以忽略不计,于是我们可以把 L i L_i Li的式子(仅在求导时)看作:
L i = w j T x i = x i 1 w j 1 + x i 2 w j 2 + ⋯ + x i d w j d L_i=\mathbf{w}_j^T \mathbf{x}_i=x_{i1}w_{j1}+x_{i2}w_{j2}+\cdots + x_{id}w_{jd} Li=wjTxi=xi1wj1+xi2wj2+⋯+xidwjd
根据矩阵求导,我们有
∂ L i ∂ w j = [ ∂ L i w j 1 ∂ L i w j 2 ⋮ ∂ L i w j d ] = [ x i 1 x i 2 ⋮ x i d ] = x i \frac{\partial L_i}{\partial \mathbf{w}_j}= \begin{bmatrix} \frac{\partial L_i}{w_{j1}} \\ \frac{\partial L_i}{w_{j2}} \\ \vdots \\ \frac{\partial L_i}{w_{jd}} \\ \end{bmatrix}= \begin{bmatrix} x_{i1} \\ x_{i2} \\ \vdots \\ x_{id} \\ \end{bmatrix}=\mathbf{x}_i ∂wj∂Li=
wj1∂Liwj2∂Li⋮wjd∂Li
=
xi1xi2⋮xid
=xi
所以我们有:
∂ L i ∂ w j = { x i i f w j T x i + b j − w y i T x i + b y i + 1 ≥ 0 0 o t h e r w i s e \frac{\partial L_i}{\partial \mathbf{w}_j}= \begin{cases} \mathbf{x}_i \qquad & if \ \mathbf{w}_j^T \mathbf{x}_i +b_j-\mathbf{w}_{y_i}^T \mathbf{x}_i +b_{y_i}+1\geq0 \\ 0 \qquad & otherwise \end{cases} ∂wj∂Li={ xi0if wjTxi+bj−wyiTxi+byi+1≥0otherwise
而 ∂ L i ∂ b j \frac{\partial L_i}{\partial b_j} ∂bj∂Li较好求,不多说明:
∂ L i ∂ b j = { 1 i f w j T x i + b j − w y i T x i + b y i + 1 ≥ 0 0 o t h e r w i s e \frac{\partial L_i}{\partial b_j}= \begin{cases} 1 \qquad & if \ \mathbf{w}_j^T \mathbf{x}_i +b_j-\mathbf{w}_{y_i}^T \mathbf{x}_i +b_{y_i}+1\geq0 \\ 0 \qquad & otherwise \end{cases} ∂bj∂Li={ 10if wjTxi+bj−wyiTxi+byi+1≥0otherwise
利用这些已求导数,我们可以求出 L ( W ) L(\mathbf{W}) L(W)的梯度。
L ( W ) = 1 N ∑ i = 1 N L i ( x i , y i , W ) + λ R ( W ) L(\mathbf{W})=\frac{1}{N}\displaystyle\sum\limits_{i=1}^N L_i(x_i, y_i, \mathbf{W}) + \lambda R(\mathbf{W}) L(W)=N1i=1∑NLi(xi,yi,W)+λR(W)
∇ W L ( W ) = 1 N ∑ i = 1 N ∇ W L i ( x i , y i , W ) + λ ∇ W R ( W ) \nabla_\mathbf{W} L(\mathbf{W})=\frac{1}{N}\displaystyle\sum\limits_{i=1}^N \nabla_\mathbf{W}L_i(x_i, y_i, \mathbf{W}) + \lambda \nabla_\mathbf{W}R(\mathbf{W}) ∇WL(W)=N1i=1∑N∇WLi(xi,yi,W)+λ∇WR(W)
while true
权值的梯度 ← 计算梯度(损失、训练样本、权值)
权值 ← 权值 - 学习率 * 权值的梯度
不难发现,当 N N N很大时,权值的梯度所需的计算量很大。
随机梯度下降算法
每次随机选择一个样本 x i x_i xi,计算损失并更新梯度。
L ( W ) = L i ( x i , y i , W ) + λ R ( W ) L(\mathbf{W})=L_i(x_i, y_i, \mathbf{W}) + \lambda R(\mathbf{W}) L(W)=Li(xi,yi,W)+λR(W)
∇ W L ( W ) = ∇ W L i ( x i , y i , W ) + λ ∇ W R ( W ) \nabla_\mathbf{W} L(\mathbf{W})= \nabla_\mathbf{W}L_i(x_i, y_i, \mathbf{W}) + \lambda \nabla_\mathbf{W}R(\mathbf{W}) ∇WL(W)=∇WLi(xi,yi,W)+λ∇WR(W)
while true
数据 ← 从训练数据采样(训练数据, 1)
权值的梯度 ← 计算梯度(损失, 训练样本, 权值)
权值 ← 权值 - 学习率 * 权值的梯度
但是单个样本的训练可能会带来很多噪声,不是每次迭代都向着整体最优化的方向。
小批量梯度下降算法
每次随机选取 m m m个(批量的大小,也是一个超参数)个样本,计算损失并更新梯度。
L ( W ) = 1 m ∑ i = 1 m L i ( x i , y i , W ) + λ R ( W ) L(\mathbf{W})=\frac{1}{m}\displaystyle\sum\limits_{i=1}^m L_i(x_i, y_i, \mathbf{W}) + \lambda R(\mathbf{W}) L(W)=m1i=1∑mLi(xi,yi,W)+λR(W)
∇ W L ( W ) = 1 m ∑ i = 1 N ∇ W L i ( x i , y i , W ) + λ ∇ W R ( W ) \nabla_\mathbf{W} L(\mathbf{W})=\frac{1}{m}\displaystyle\sum\limits_{i=1}^N \nabla_\mathbf{W}L_i(x_i, y_i, \mathbf{W}) + \lambda \nabla_\mathbf{W}R(\mathbf{W}) ∇WL(W)=m1i=1∑N∇WLi(xi,yi,W)+λ∇WR(W)
一些名词的介绍(会实现的代码中)
iteration:表示1次迭代,每次迭代更新1次网络结构的参数;
batch_size:1次迭代所使用的样本量;
epoch:1个epoch表示过了1遍训练集中的所有样本。
通常使用2的幂数作为批量大小,比如说32或64或128个样本。
while true
小批量数据 ← 从训练数据采样(训练数据, 批量大小)
权值的梯度 ← 计算梯度(损失, 小批量数据, 权值)
权值 ← 权值 - 学习率 * 权值的梯度
6 数据集
6.1 数据集划分
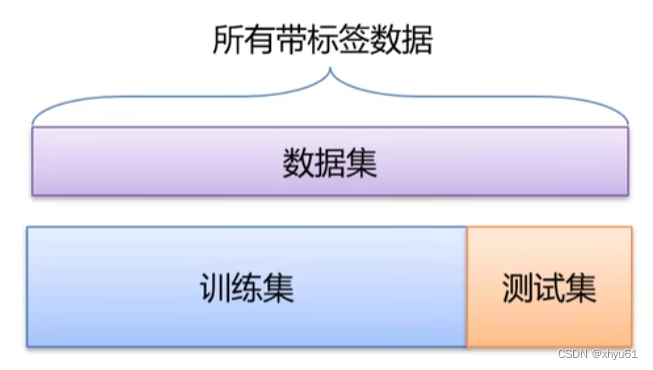
训练集→训练模型,寻找最优的分类器;
测试集→评估模型,评测泛化能力。
问 如果模型含有超参数(比如正则化强度),如何找到泛化能力最好的超参数?
答 再设立一个验证集,用于选择超参数。
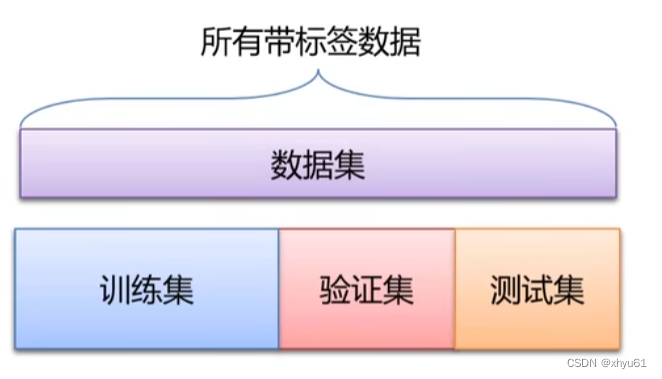
训练集用于给定的超参数时分类器参数的学习;
验证集用于选择超参数;
测试集评估泛化能力。
(这样可以避免训练过程中看到测试集,使得出现过拟合现象)
问 如果数据很少,那么可能验证集包含的样本就很少,从而无法在统计上代表数据。
这个问题很容易发现,如果在划分数据前进行不同的随机打乱,最终得到的模型性能差别很大,那么就存在这个问题。
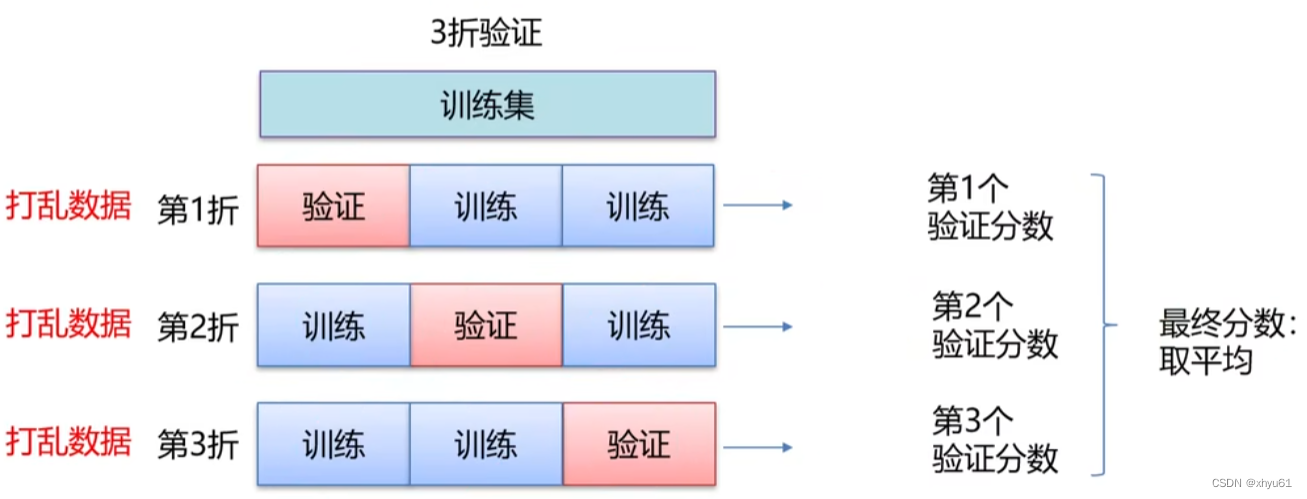
K折交叉验证
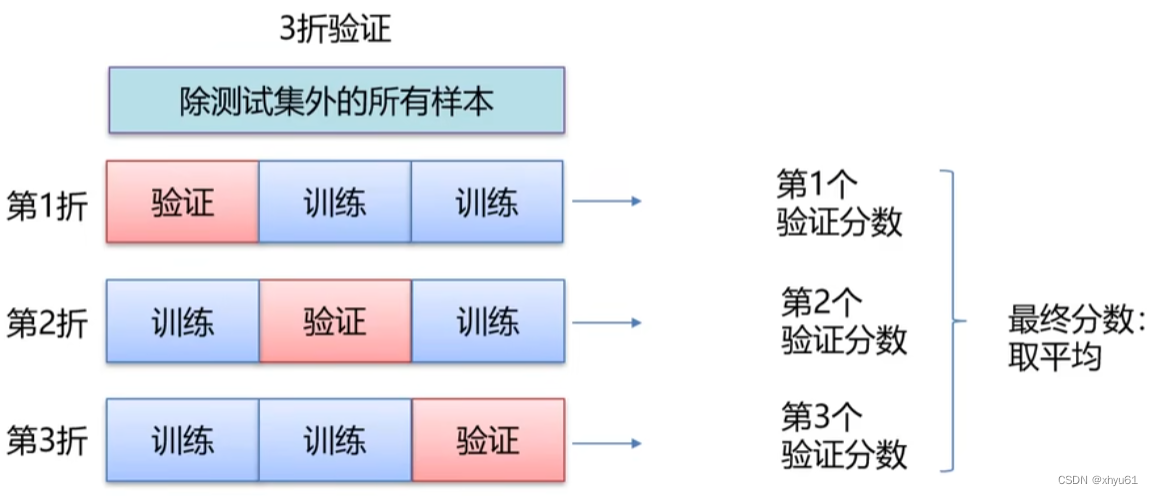
带打乱顺序的K折交叉验证
6.2 数据预处理
数据能否直接使用?有哪些处理方式?

通常不太会直接使用原始数据进行学习。
假设原始数据中的数据分别为 x i x_i xi,均值为 x ˉ \bar{x} xˉ,最小值为 min ( x ) \min(x) min(x),最大值为 max ( x ) \max(x) max(x),标准差为 σ ( x ) \sigma(x) σ(x)。
去均值的方法: x i ← x i − x ˉ x_i \leftarrow x_i-\bar{x} xi←xi−xˉ。
归一化的方法有两种:
- min-max归一化: x i ← x i − min ( x ) max ( x ) − min ( x ) x_i \leftarrow \frac{x_i-\min(x)}{\max(x)-\min(x)} xi←max(x)−min(x)xi−min(x)
- mean归一化: x i ← x i − x ˉ max ( x ) − min ( x ) x_i \leftarrow \frac{x_i-\bar{x}}{\max(x)-\min(x)} xi←max(x)−min(x)xi−xˉ
标准化的方法: x i ← x i − x ˉ σ ( x ) x_i \leftarrow \frac{x_i-\bar{x}}{\sigma(x)} xi←σ(x)xi−xˉ
事实上,归一化和标准化都是把数据图像中心平移到原点。但是归一化没有改变数据分布的形状,而标准化使样本数据的分布近似为某种分布(通常为正态分布)。
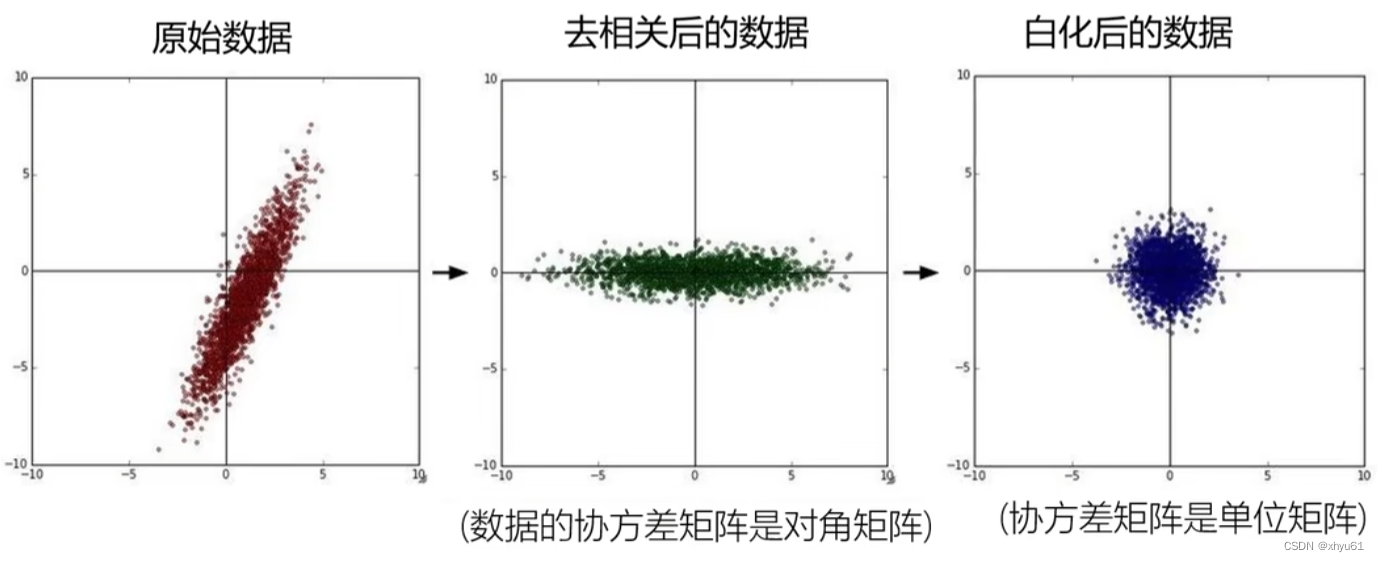
原始数据中可以看出, x x x增大时, y y y也有总体增大的趋势,所以我们可以认为此时 x x x和 y y y是相关的。但学习的过程中,我们不希望把 x x x和 y y y两种东西放在一起去考虑,这时我们采取去相关的操作。去相关后,可以看出 y y y的变化方式与 x x x没有关系了。如此一来,我们可以把 x x x和 y y y分开单独考虑,实现“降维”的效果。
白化为去相关后进行标准化。
神经网络中用到更多的是去均值和标准化、归一化。