happy birthday to me
序列模型
为什么选择序列模型
序列模型如循环神经网络等模型在语音识别、自然语言处理和其他领域带来重要的变革。

构建模型
首先,模型的目的是为了识别一句话中的人名和地名。
1.定义输入序列
和输出序列
,i指第几个数据集,t指的序列中的位置。同时构建一个10000个单词大小的词典,构建方法是遍历数据集,找到前10000个常用词,然后用one-hot表示法来表示词典里的每个单词,最后将不在词典里的单词记
。
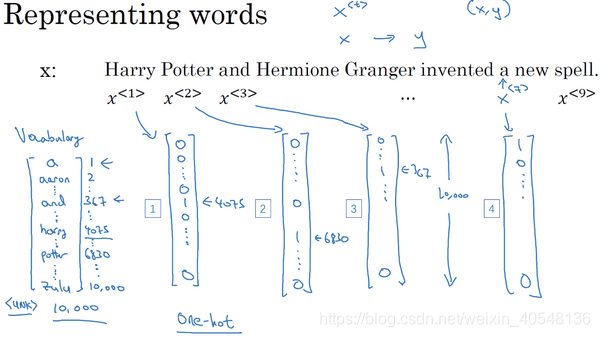
接下来构建模型
可以尝试的方法是构建标准的神经网络,输入n个单词,获取n个0或1的项,表明每个输入单词是否是人名的一部分。
但是有三个问题:
一是输入和输出的长度固定,虽然我们可以通过设定最大长度,通过零填充来解决问题,但这仍然不是一个好的表达方式。
二是一个单纯的这样的神经网络,并不共享从文本的不同位置学到的特征。
三是
都是10000维的one-hot向量,参数矩阵会有巨大的参数。
而循环神经网络可以解决上述问题:
循环神经网络将一个序列依次传入一个神经网络层,同时传入上一个节点的隐藏状态,这样在每个节点输出一个预测和隐藏状态,隐藏状态做为下一节点的输入。
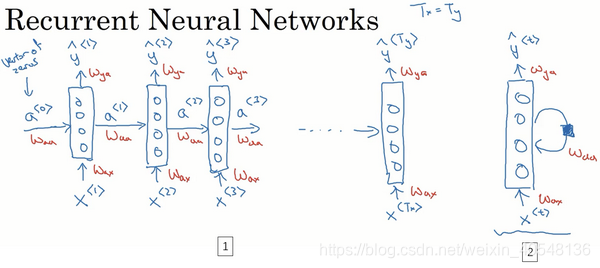
这里的循环网络模型的一个限制是某一节点预测只有用了序列前的信息,而没有之后的信息,这个我们在之后的双向循环模型(BRNN)处理这个问题。
注意,每个时间步的参数是共享相同的。
表示管理
到隐藏层的连接的参数,每个时间步使用的都是相同的
。而隐藏状态的传递由参数
决定。输出结果由
。
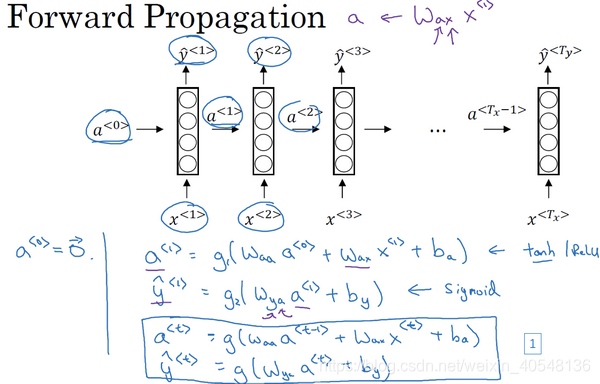
如上图所示,每个时间步完成两步计算,一是计算隐藏层状态,而是计算输出值。
而关于隐藏层激活函数选择,通常是tanh,有时候也会选择relu。输出层激活函数选择取决于输出y,如果是二分类函数,可以选择sigmoid函数,如果是k分类可以选择softmax函数。
模型简化
我们可以将 合并为一个矩阵,这样参数矩阵并列放置亦可以合成一个矩阵 。这里我们举个例子,如果a是100维的,x是10000维的,那么 是 维度的矩阵, 维度的矩阵,合并 就是 维度的矩阵。
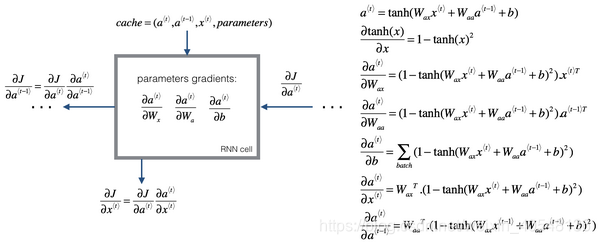
反向传播
首先定义损失函数
,如下图。

首先定义某一时间步的输出损失函数,所有时间步的输出累加获取整个序列的损失函数。
然后我们要做的是通过对相关的参数求导,然后用梯度下降函数来更新。
关于梯度的计算如下图,这里后面有个课程练习,十分建议做一下这个练习,对于RNN神经网络的反向传播会有一个清晰的认识。
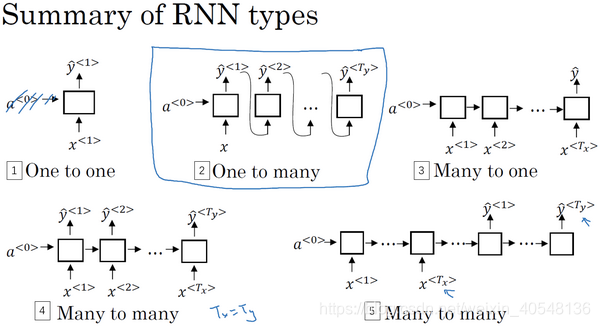
RNN的输入和输出
多对多、多对一、一对一和一对多
语言模型和序列生成
在语音识别或机器翻译里,语言模型会告诉你某个句子出现的出现的概率是多少。
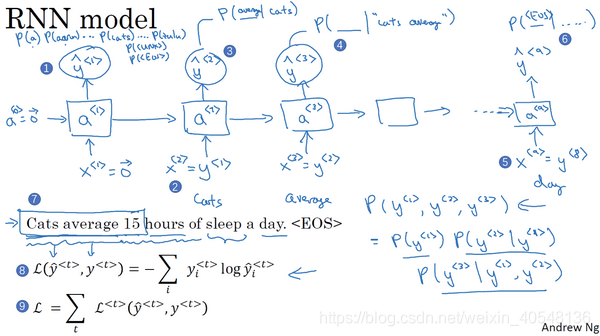
如上图所示,我们要搞懂以下几点:
1.每一个时间步,通过隐藏状态
计算输出,
上一时间步的结果值。
2.第一个时间步,
都被设为全为0的集合,这里
其实输出的是每个单词输出的概率。
3.假如通过softmax函数输出10000种结果,也就是字典里单词有10000个,或者10002个(未知词 结尾词)。每一步的输出实际是计算了一个条件概率,在前面的真实结果值的基础上求当前时间步结果值的概率,而模型训练的过程其实就是在提高正确结果值的预测概率。
4.softmax损失函数的计算公式是上图编号8,上述交叉熵损失函数将
带入获得下式。
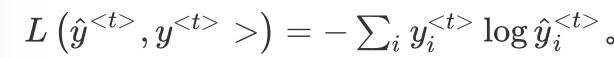
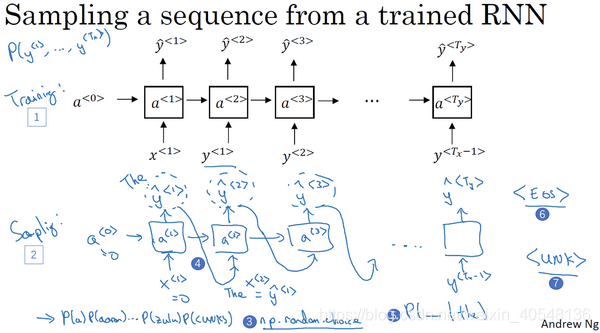
对新序列采样
训练完序列模型后,我们对新序列模型进行一次采样。
初始输入与训练输入相同皆为0向量,以上一时间步的输出
作为后续时间步的输入。第一个输出的选择我们通过一个numpy函数np.random.choice来选择。直到预测出结尾标志结束。
循环神经网络的梯度消失
关于梯度消失:反向传播时从输出得到的梯度很难传播和影响到前层的权重。换言之,我们上面构造的RNN没有很好的解决长期依赖问题。
当然,可能也会出现梯度爆炸的现象,相比于梯度消失,梯度爆炸的方式可以采用最大值修剪的方法来解决,而梯度消失更棘手一些。
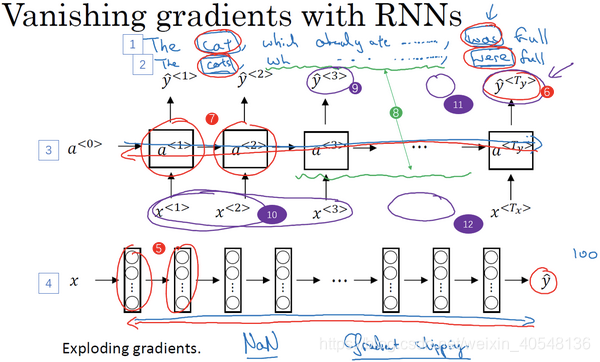
下面我们将介绍几种RNN模型来解决梯度消失和长期依赖问题。
GRU单元-更新门和相关门
下面我们简要介绍下GRU,GRU采用
取代
,与之不同的是,我们还会通过sigmoid激活函数计算一个更新门
来决定是否更新状态
,当更新门的值为0,则不更新,当为1,则完全更新。实际应用中更新门可能会取一个0到1的值。
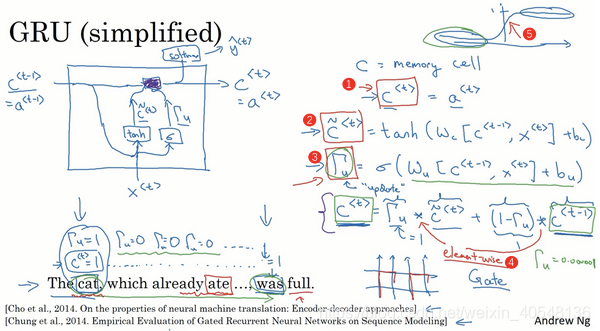
以下是GRU的计算流程,还要注意,更新门的维度与隐藏状态
的维度相同。
最后,完整的GRU我们还需要添加一个门
,我们可以将它理解为前后两个隐藏状态
的相关性,因而
门在计算当前时间步的隐藏状态发挥作用。

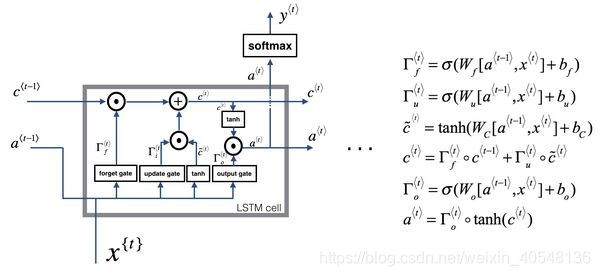
长短时记忆(LSTM)
LSTM有三个门控制:更新门 遗忘门 输出门。
这里有以下几点需要注意:
1.三个门的系数都是由
计算。
2.记忆细胞的更新值由更新门与新的记忆细胞和遗忘门与旧的记忆细胞来决定。
3.隐藏状态的更新通过新的记忆细胞和更新门来决定。
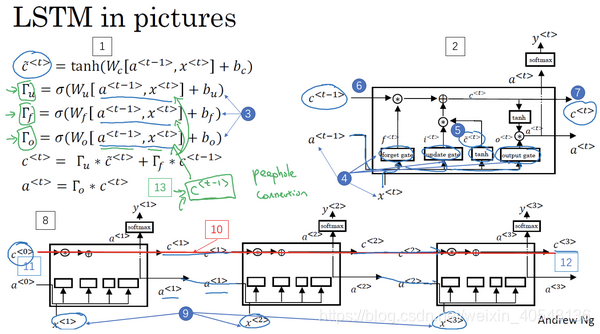
补充一张前向传播大图,关于反向传播的计算,建议参考课后练习,更具有实操性。
最后,关于GRU和LSTM的选择,GRU是个更加简洁的模型,也更容易创建更大的网络;而LSTM更加强大和灵活,通常LSTM是一个更优先的选择。
未完待续…