RNN
RNN cell
吴恩达的课后练习很重要一点就是模块化的设计,使整个问题看起来简化了很多。第一个模块是前向传播,输入
以及隐藏层参数W和b(以字典的形式)。
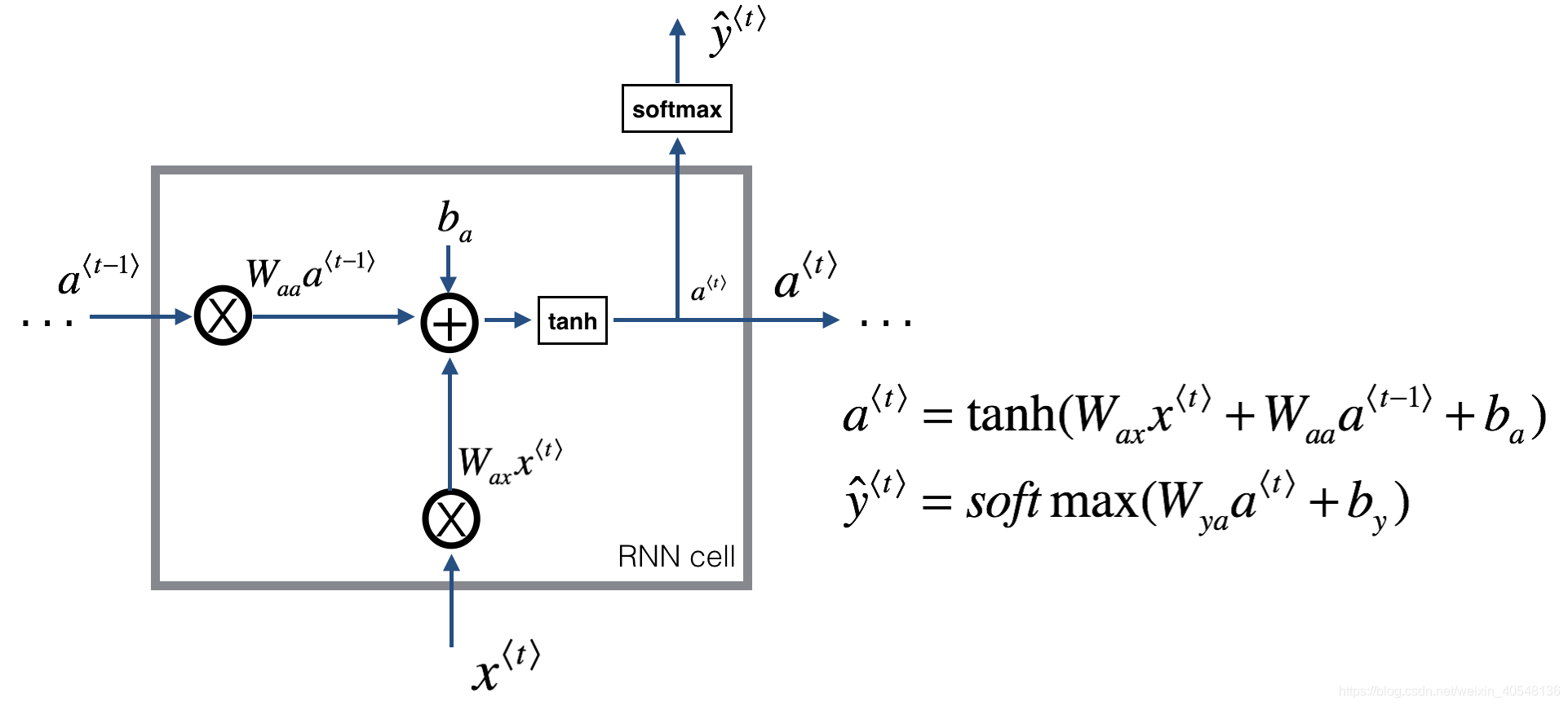
def rnn_cell_forward(xt, a_prev, parameters):
Wax = parameters["Wax"]#从字典取值,方便计算
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
a_next = np.tanh(np.dot(Wax,xt)+np.dot(Waa,a_prev)+ba) #计算a_t
yt_pred = softmax(np.dot(Wya,a_next)+by)#计算输出
cache = (a_next, a_prev, xt, parameters)#返回一个tuple供反向传播使用
return a_next, yt_pred, cache
#输入每一个时间步的多个数据x
def rnn_forward(x, a0, parameters):
caches = []
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wya"].shape
a = np.zeros((n_a,m,T_x))#初始化隐藏状态
y_pred = np.zeros((n_y,m,T_x))#初始化预测输出的数组
a_next = a0
# loop over all time-steps
for t in range(T_x):
a_next, yt_pred, cache = rnn_cell_forward(x[:,:,t], a_next, parameters)# 每个timesteps共享参数,因此循环的parameters不变
a[:,:,t] = a_next#保存隐藏状态
y_pred[:,:,t] = yt_pred#保存预测值
caches.append(cache)#将返回的tuple添加到列表中
caches = (caches, x)#将列表与x组成一个tuple
return a, y_pred, caches
下面构建一个常见的LSTM。
LSTM cell
LSTM大图还是一目了然的,计算遗忘门、更新门、输出门。遗忘门和更新门来更新记忆细胞状态c_t,获取新的记忆细胞与输出门更新新的隐藏状态a_t。

def lstm_cell_forward(xt, a_prev, c_prev, parameters):
#从parameters取参数
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wc = parameters["Wc"]
bc = parameters["bc"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wy = parameters["Wy"]
by = parameters["by"]
n_x, m = xt.shape
n_y, n_a = Wy.shape
#连接隐藏状态a_t-1和x_t,单个cell中样本是二维的
concat = np.zeros((n_x+n_a,m))
concat[: n_a, :] = a_prev
concat[n_a :, :] = xt
#遗忘门和更新门都输出一个包含元素0到1的向量,0到1的值可以理解为遗忘和更新的比例
ft = sigmoid(np.dot(Wf,concat)+bf)#遗忘门
it = sigmoid(np.dot(Wi,concat)+bi)#更新门
cct = np.tanh(np.dot(Wc,concat)+bc) #新的记忆细胞
c_next = ft*c_prev+it*cct #经过遗忘门和更新门更新后的记忆细胞
ot = sigmoid(np.dot(Wo,concat)+bo)#输出门
a_next = ot*np.tanh(c_next)#新的隐藏状态
yt_pred = softmax(np.dot(Wy,a_next)+by)#输出
cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters)#保存各结果值用作反向传播
return a_next, c_next, yt_pred, cache
#LSTM cell的前向传播,与上述类似
def lstm_forward(x, a0, parameters):
caches = []
n_x, m, T_x = x.shape
n_y, n_a = parameters['Wy'].shape
a = np.zeros((n_a,m,T_x))
c = np.zeros((n_a,m,T_x))
y = np.zeros((n_y,m,T_x))
a_next = a0
c_next = c[:,:,0]
for t in range(T_x):#遍历每一个时间步
a_next, c_next, yt, cache = lstm_cell_forward(x[:,:,t], a_next, c_next, parameters)
a[:,:,t] = a_next
y[:,:,t] = yt
c[:,:,t] = c_next
caches.append(cache)
caches = (caches, x)
return a, y, c, caches
基础RNN反向传播
两张图说明问题。
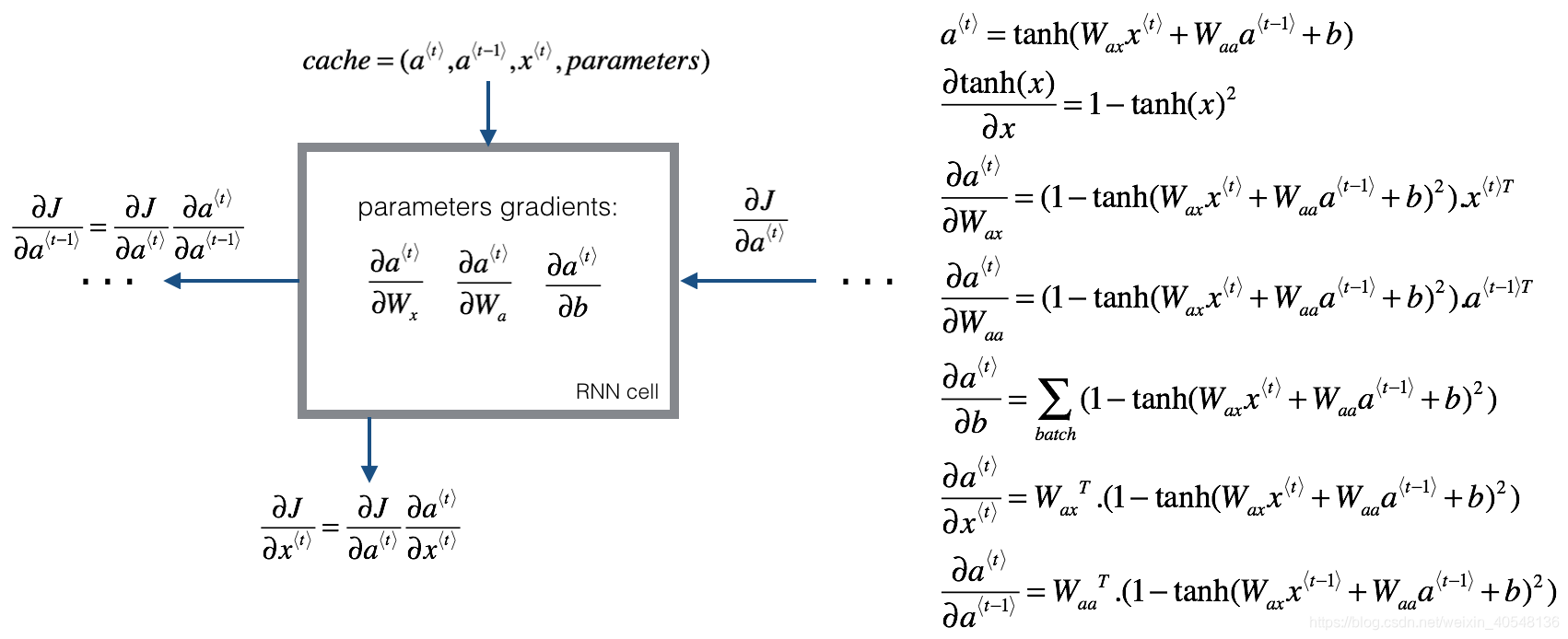
def rnn_cell_backward(da_next, cache):#输入为a_t的导数和前向传播返回的cache
(a_next, a_prev, xt, parameters) = cache#从前向传播的cache取值
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
#这里应该注意的是反向传播的思路是一步步求导
dtanh = (1-a_next**2)*da_next #套用tanh求导公式
dxt = np.dot(Wax.T,dtanh)
dWax = np.dot(dtanh,xt.T)
da_prev = np.dot(Waa.T,dtanh)
dWaa = np.dot(dtanh,a_prev.T)
dba = np.sum(dtanh,axis=1,keepdims=True)
gradients = {"dxt": dxt, "da_prev": da_prev, "dWax": dWax, "dWaa": dWaa, "dba": dba}
return gradients
def rnn_backward(da, caches):
(caches, x) = caches
(a1, a0, x1, parameters) = caches[0]
n_a, m, T_x = da.shape
n_x, m = x1.shape
dx = np.zeros((n_x,m,T_x))
dWax = np.zeros((n_a,n_x))
dWaa = np.zeros((n_a,n_a))
dba = np.zeros((n_a,1))
da0 = np.zeros((n_a,m))
da_prevt = np.zeros((n_a,m))
for t in reversed(range(T_x)):
gradients = rnn_cell_backward(da[:,:,t] + da_prevt, caches[t]) # 损失来自于两部分:一部分是下一个时间步的a_t,一部分来自于当前步的y_t.这里并没有详细推导。
dxt, da_prevt, dWaxt, dWaat, dbat = gradients["dxt"], gradients["da_prev"], gradients["dWax"], gradients["dWaa"], gradients["dba"]
dx[:, :, t] = dxt
dWax += dWaxt
dWaa += dWaat
dba += dbat
da0 = da_prevt
gradients = {"dx": dx, "da0": da0, "dWax": dWax, "dWaa": dWaa,"dba": dba}
return gradients
LSTM 反向传播
LSTM求导复杂一些,还是一步步推导,以最初的ot(输出门)为例,前向传播时,输出门和at的关系如下,所以从a_next传到ot的参数应为da_next*np.tanh(c_next)ot(1-ot),(sigmoid的导数 = sigmoid *(1-sigmoid))
ot = sigmoid(np.dot(Wo,concat)+bo)
a_next = ot*np.tanh(c_next)

LSTM我在课程里写的没保存,网上copy了一下。
#反向传播要按照正向传播的每个值一步步求导。课程中每一步都给出公式也就是下列代码
def lstm_cell_backward(da_next, dc_next, cache):
(a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters) = cache
n_x, m = xt.shape
n_a, m = a_next.shape
dot = da_next*np.tanh(c_next)*ot*(1-ot)
dcct = (dc_next*it+ot*(1-np.square(np.tanh(c_next)))*it*da_next)*(1-np.square(cct))
dit = (dc_next*cct+ot*(1-np.square(np.tanh(c_next)))*cct*da_next)*it*(1-it)
dft = (dc_next*c_prev+ot*(1-np.square(np.tanh(c_next)))*c_prev*da_next)*ft*(1-ft)
dWf = np.dot(dft,np.concatenate((a_prev, xt), axis=0).T)
dWi = np.dot(dit,np.concatenate((a_prev, xt), axis=0).T)
dWc = np.dot(dcct,np.concatenate((a_prev, xt), axis=0).T)
dWo = np.dot(dot,np.concatenate((a_prev, xt), axis=0).T)
dbf = np.sum(dft,axis=1,keepdims=True)
dbi = np.sum(dit,axis=1,keepdims=True)
dbc = np.sum(dcct,axis=1,keepdims=True)
dbo = np.sum(dot,axis=1,keepdims=True)
da_prev = np.dot(parameters['Wf'][:,:n_a].T,dft)+np.dot(parameters['Wi'][:,:n_a].T,dit)+np.dot(parameters['Wc'][:,:n_a].T,dcct)+np.dot(parameters['Wo'][:,:n_a].T,dot)
dc_prev = dc_next*ft+ot*(1-np.square(np.tanh(c_next)))*ft*da_next
dxt = np.dot(parameters['Wf'][:,n_a:].T,dft)+np.dot(parameters['Wi'][:,n_a:].T,dit)+np.dot(parameters['Wc'][:,n_a:].T,dcct)+np.dot(parameters['Wo'][:,n_a:].T,dot)
gradients = {"dxt": dxt, "da_prev": da_prev, "dc_prev": dc_prev, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradients
计算整个模型(多个时间步)的梯度
def lstm_backward(da, caches):
(caches, x) = caches
(a1, c1, a0, c0, f1, i1, cc1, o1, x1, parameters) = caches[0]
n_a, m, T_x = da.shape
n_x, m = x1.shape
dx = np.zeros((n_x, m, T_x))
da0 = np.zeros((n_a, m))
da_prevt = np.zeros((n_a, m))
dc_prevt = np.zeros((n_a, m))
dWf = np.zeros((n_a, n_a + n_x))
dWi = np.zeros((n_a, n_a + n_x))
dWc = np.zeros((n_a, n_a + n_x))
dWo = np.zeros((n_a, n_a + n_x))
dbf = np.zeros((n_a, 1))
dbi = np.zeros((n_a, 1))
dbc = np.zeros((n_a, 1))
dbo = np.zeros((n_a, 1))
for t in reversed(range(T_x)):
gradients = lstm_cell_backward(da[:,:,t]+da_prevt,dc_prevt,caches[t])
dx[:, :, t] = gradients['dxt']
dWf = dWf+gradients['dWf']
dWi = dWi+gradients['dWi']
dWc = dWc+gradients['dWc']
dWo = dWo+gradients['dWo']
dbf = dbf+gradients['dbf']
dbi = dbi+gradients['dbi']
dbc = dbc+gradients['dbc']
dbo = dbo+gradients['dbo']
da0 = gradients['da_prev']
gradients = {"dx": dx, "da0": da0, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradients
未完待续…