1.1 为什么选择序列模型?(Why Sequence Models?)

语音识别:将输入的语音信号直接输出相应的语音文本信息。无论是语音信号还是文本信息均是序列数据。
音乐生成:生成音乐乐谱。只有输出的音乐乐谱是序列数据,输入可以是空或者一个整数。
情感分类:将输入的评论句子转换为相应的等级或评分。输入是一个序列,输出则是一个单独的类别。
DNA序列分析:找到输入的DNA序列的蛋白质表达的子序列。
机器翻译:两种不同语言之间的想换转换。输入和输出均为序列数据。
视频行为识别:识别输入的视频帧序列中的人物行为。
命名实体识别:从输入的句子中识别实体的名字。
1.2 数学符号(Notation)
Harry Potter and Herminoe Granger invented a new spell
如果想要表示一个句子里的单词
- 做一张词典,通常通过遍历训练集,找到常用的10000个常用词
- 然后用one-hot表示法来表示词典里的每个单词
- 组成词典里有对应单词得为1,其他都为0的向量

1.3 循环神经网络模型(Recurrent Neural Network Model)
我们要建立一个神经网络来学习X到Y的映射,如果使用标准的神经网络有缺陷:
- 输入和输出数据在不同的例子中可以有不同的长度
- 这种朴素的神经网络结果并不能共享从文本不同位置所学习到的特征。(如卷积神经网络中学到的特征的快速地推广到图片其他位置)
RNN( 循环神经网络):
每一个时间步中,循环神经网络传递一个激活值到下一个时间步中用于计算。
- 开始之前,需要构造一个激活值 ,通常是0向量
- 将第一个词 输入第一个神经网络隐藏层,让网络预测输出
- 将第二个词 输入第二个神经网络隐藏层,同时也会将时间步1的 传到时间步2上,在预测输出
- 以此类推
循环神经网络是从左向右扫描数据,同时每个时间步的参数也是共享的。

- 代表 传向每t层隐藏层的参数
- 代表激活值传向下一个时间步中的参数
- 代表控制输出结果的参数
所以当t层输出的时候,都用到了前面 t - 1 层的信息参数,但是缺点是他只能用序列之前的信息来做预测。可以用双向神经网络(BRNN)解决。
RNN计算过程:

前向传播:
下表字母代表对应值a,x,y运算,激活函数一般用tanh
- 输入
- 计算激活值:
- 计算y: =
t时刻公式为:
=
然后对公式进行简化:
矩阵定义为矩阵
水平并列放置。
所以可以把
化简为
同时矩阵
的维度也会叠加,例如a为(100,100) x为(100,10000)那么矩阵
的维度(100,10100)
RNN前向传播示意图:

1.4 通过时间的反向传播(Backpropagation through time)
反向传播,梯度下降法,定义一个损失函数,这是关于说某个时间步t上某个单词的预测值的损失函数。
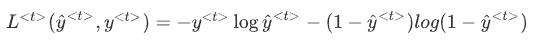
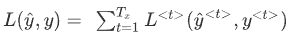
RNN反向传播示意图:

1.5 不同类型的循环神经网络(Different types of RNNs)
以上都是 = 的结构,实际上有很输入与输出多不相等的RNN结构。
many-to-many:
输入输出一样

many-to-one:
情感分析,输入一段文本,得出评价1到5棵星

one-to-many:
输入音乐的类型,生成一段音乐序列

many-to-many(
≠
)
输入输出序列长度不一致

1.6 语言模型和序列生成(Language model and sequence generation)
例如这两个句子发音差不多

语言模型所做的是告诉你某个特定的句子它出现的概率是多少。
为了建立一个语言模型:
- 需要一个语料库(corpus)来当训练集,语料库是指数量众多的句子组成的文本。
- 将句子用字典库标记化,字典库中未出现的词用UNK代替
- 将每个单词都转换成对应的one-hot向量,定义句子的结尾EOS
- 用 对第一个单词输出进行预测,即为某个词的概率
- 使用前面的输入,逐步预测后面的单词输出概率
- 训练网络:使用softmax损失函数计算损失,对网络进行参数更新,提升语言模型的准确率。
第一softmax层会告诉你 的概率 ,第二个softmax层会告诉你在 的情况下 的概率,第三个softmax层会告诉你在 的情况下 的概率,把这三个概率相乘,最后得到这个含3个词的整个句子的概率。
1.7 对新序列采样(Sampling novel sequences)
在你训练一个序列模型之后,要想了解这个模型学到了什么,一种非正式的方法就是进行一次新序列采样。
一个序列模型模拟了任意特定单词序列的概率,我们要做的就是对这些概率分布进行采样来生成一个新的单词序列。(从你的RNN语言模型中生成一个随机选择的句子。)
- 输入 =0, =0在这第一个时间步,我们得到所有可能的输出经过softmax层后可能的概率,根据这个softmax的分布,进行随机采样,获取第一个随机采样单词
- 然后继续下一个时间步,我们以刚刚采样得到的 作为下一个时间步的输入,进而softmax层会预测下一个输出 ,依次类推
- 如果字典中有结束的标志如:“EOS”,那么输出是该符号时则表示结束;若没有这种标志,则我们可以自行设置结束的时间步。
还可以构建一个基于字符的RNN结构

在你的训练数据中将会是单独的字符,而不是单独的词汇。
优点:不会出现未知的标识
缺点:序列太长,在捕捉句子中的依赖关系时,不如基于词汇的语言模型那样可以捕捉长范围的关系,并且基于字符的语言模型训练起来计算成本比较高昂。
1.8 循环神经网络的梯度消失(Vanishing gradients with RNNs)
训练很深的神经网络,会有梯度消失和梯度爆炸的问题。训练很深的RNN也是同理
例子:
“The cat, which already ate ……, was full.”
“The cats, which ate ……, were full.”
动词形式要对应前面名词的单复数,有长期的依赖。但是基本的RNN不擅长这个。
梯度消失:RNN反向传播会很困难,因为同样的梯度消失的问题,后面层的输出误差很难影响前面层的计算。
梯度爆炸:梯度爆炸的一个解决方法就是用梯度修剪。梯度修剪的意思就是观察你的梯度向量,如果它大于某个阈值,缩放梯度向量,保证它不会太大,这就是通过一些最大值来修剪的方法。然而梯度消失更难解决。
1.9 GRU单元(Gated Recurrent Unit(GRU))
门控循环单元,它改变了RNN的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题。
- GRU单元将会有个新的变量称为c (cell)记忆细胞,记忆细胞提供了记忆能力。
- 对于GRU而言, 的值等于 的值。
- 对于每一个时间步,使用一个候选重写记忆细胞 ,代替 , =
- 更新门: ,经过sigmiod,值为0到1之间, = ,用以决定是否对当前时间步的记忆细胞用候选值更新替代
- , , 维度相同。
= 1则用新值,
= 0则用旧值,实际中会是0到1之间的值
有利于维持细胞的值,这就是缓解梯度消失问题的关键。
过程如下:

完整的GRU要加一个
=
,γ代表相关性(relevance)。同时
=
判断
有多大的关联性。

1.10 长短期记忆(LSTM(long short term memory)unit)
LSTM相较于GRU的区别:LSTM利用了单独的更新门,遗忘门来控制更新值
公式:
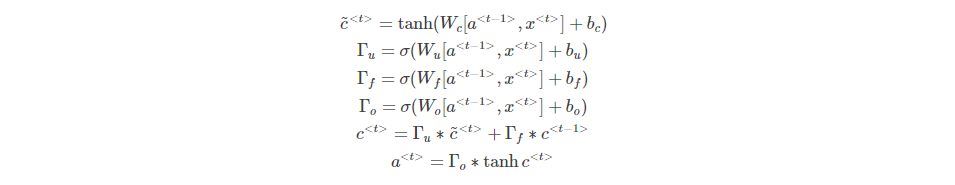
实际使用,还可能会取决于上一个记忆细胞的值
,称为偷窥孔连接。

GRU更简单,计算速度快,可以计算大模型,但是LSTM更灵活,更强大。
1.11 双向循环神经网络(Bidirectional RNN)
RNN存在的问题就是只能根据之前的序列信息进行判断,BRNN不仅仅可以获取之前的信息,还能获取未来的信息。

BRNN与RNN相比除了前向传播连接层,还会增加一个反向连接层。
例如预测y3 会有一条a4到a3到y3反向传播路径。

缺点:要获取完整的一段信息后才能进行判断。NLP中经常使用双向RNN的LSTM网络。
1.12 深层循环神经网络(Deep RNNs)
对于RNN来说3层已经很多了,因为时间的维度会很大,常见的一种情况是,在后面堆叠层数得到输出,但是没有横向传播,另外这些单元也可以是LSTM,RNN,GRU。
