词汇表
上周我们学习了RNN、GRU和LSTM单元,本周我们将会将他们应用到NLP当中,其中,在词处理有一个很重要的概念叫词嵌入(word embeddings)这是语言的一种表达方式,可以让算法自动理解一些词语的类别关系,例如苹果和橘子都是水果,再比如男人对女人类比到国王对王后。
我们之前是采用one hot向量表示词,这种算法最大的缺点是将每个词孤立起来,使得算法对相关词的泛化能力不强。

我们采用一种新的方式来表达词,如下图,我们把新的向量的词特征定义为300个,而不是之前的10000个。其次,我们可以看到man和woman以及king和queen的对比。我们可以把每个特征看做一个类别,例如男女、是否水果、是否食物等等。
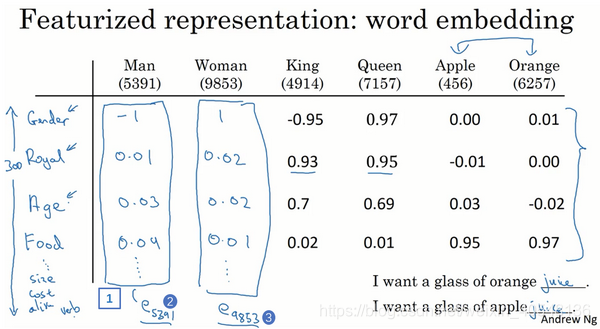
通过以上方法我们可以学习到一个300维的特征向量,我们可以把这个特征向量嵌入到二维空间中,这样就可以可视化,常用的是t-SNE算法。

最后,强调一下,词嵌入已经是NLP领域最重要的概念之一了。
使用词嵌入
1.先从大量文本学习词嵌入,或者下载已经训练好的词嵌入 模型。
2.使用词向量表示训练集的单词,通过一个更加紧凑的向量来表示。
3.当在新的数据集上训练模型时,可以选择是否微调下词嵌入。
词嵌入的特性
可以帮助实现类比推理,这里不再赘述,下图可以较好理解

通过这种类比的方法准确率大约在30%~75%
相似度函数
,这其实是两个向量的余弦值,当两个向量相似时,可以看出
会很大

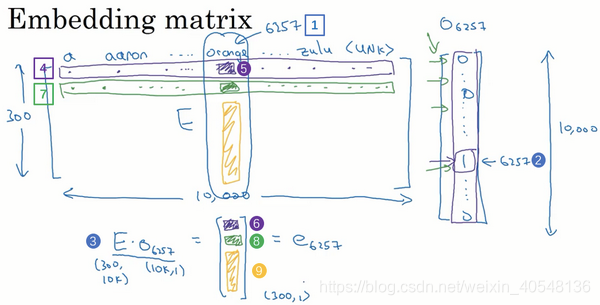
嵌入矩阵
假如我们有10000个单词想要转化为词向量,我们需要学习一个嵌入矩阵,它是300x10000,每一列代表的就是每一个单词向量。我们将词嵌入矩阵与onehot词向量相乘,其实就是嵌入矩阵的第6257列。
在实际计算中,会有专门的函数来查找矩阵的某一列,而不是用同行的矩阵乘法来计算,提升计算效率。
学习词嵌入
实践表明,建立一个语言模型是学习词嵌入的好方法。
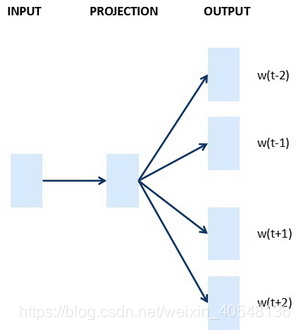
我们建立一个模型来预测序列的下一个单词
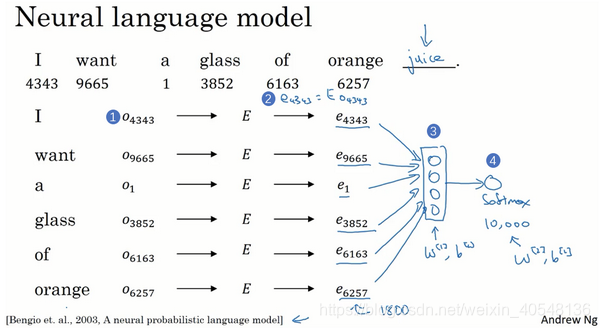
首先初始化生成一个参数矩阵E,然后E与onehot词向量相乘获得每个嵌入向量,然后将嵌入向量放入神经网络,然后经过softmax层,这里我们输入6个单词,每个单词是300维的向量,所以输入是1800维的向量。更常见的一种训练方式是预测四个单词后的下一个单词,
我们也可以选择只提供目标词的前一个词等等,这都是不同的学习问题。下一节我们学习更加简洁的Word2Vec模型。
Word2Vec
这里使用的是skip-grams的思想,我们构造一个监督学习问题,给定上下文词,预测该词10个词距或者5个词距随机选择的某个目标词,当然我们的目的不是解决这个监督学习本身,而是学到一个更好的词嵌入模型。

下面我们看下模型的细节。
假设我们继续使用一个10000词的词汇表。首先表示输入,例如单词orange,先从one-hot向量
开始,然后嵌入矩阵乘one-hot向量
,然后我们将
喂入softmax单元,输出不同单词的概率
,这里
是与输出t有关的参数。
损失函数采用常用的

实际使用这个算法会遇到一些问题,会有10000个求和计算速度偏慢。有一些解决方案分级的softmax分类器和负采样。其中分级的softmax分类器与词汇表大小的对数成正比。
关于skipgram我们还要了解一点就是上下文的采样,我们知道首先进行上下文采样,然后在上下文随机选择目标单词t,如果我们均匀随机的选择上下文样本,会发现to of a and等单词会相当频繁,而orange apple等单词就不那么频繁了,因而上下文采样并不是均匀随机的,而是采用了不同的分级来平衡常见的词和不常见的词。
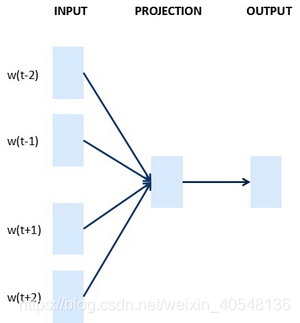
此外,还有一种word2vec的模型叫做连续词袋模型(CBOW),它获取中间词两边的上下文,然后用周围的词去预测中间的词。下图分别是skipgram和CBOW
负采样
负采样构造一个新的监督学习问题,给定一对单词,我们来预测是否是一对上下文词-目标词。通常我们会对单个上下文构造目标词,一个正样本和K个负样本。这里就变成一个逻辑回归模型,预测
,也就是y=1的概率。
这里我们将之前的问题转化为一个10000个二分类问题,每次迭代我们只训练其中K+1个二分类问题,每次迭代的成本比更新10000维的softmax分类器成本低。
如何采样负样本?
,
是观测到的在语料库的某个英语词的词频,通过
乘方使其处于完全独立的分布和训练集的观测分布两个极端之间。
Glove算法
Glove算法定义上下文和目标单词为两个位置相近的单词,假设是左右各10词的距离
是获取单词和j位置相近的频率的计数器。
Golve模型的loss函数
,两个参数相乘所获取的结果与
越接近,loss越小。然后我们对上式引入一个权重因子,当
等于0,我们也令权重
,约定
。然后引入偏移向量
,
最后,关于模型有趣的一点是
是完全对称的,最终的
可以表示为
情感分类
情感分类:就是看一段文本,分辨这个人是否喜欢他在讨论的东西。
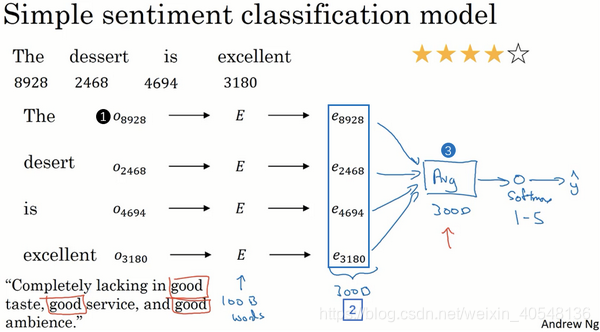
我们可以将输入的词转化为300维的词向量,然后取平均最后获取一个300维的向量,然后送进softmax分类器输出预测y。当然这种方式并不好用,因为一句话可能出现一个否定词就会将整个句子的意义变化。所以我们下面介绍采用RNN的情感分类。
词嵌入除偏
一个完成学习的词嵌入可能会出现man输出programmer而woman输出homemaker。
未完待续…
参考自自然语言处理与词嵌入