从0到1理解神经网络结构(下)
从0到1理解神经网络结构(上):
https://blog.csdn.net/weixin_40192195/article/details/88252340
模型训练目的是找到最优的参数可以和最真实的模型逼近,具体的训练方式,首先给所有的参数赋予随机的值,然后通过随机生成的值和输入的特征进行运算,得到预测的训练目标yp,真是的目标是y,那么他们之间就存在一个损失loss。
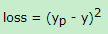
我们的目的就是将损失减到最低,也就是预测值和真实值相差很小。我们目前面临的问题就是如何优化参数使损失降到最低。
优化问题,首先想到的就是求导,但是因为参数可能会很多,计算导数等于0的运算量可能会很大。所以这里选择的是梯度下降算法。通俗来讲,梯度下降算法每次计算参数在当前的梯度,然后让参数向着梯度反方向前进,直到梯度接近0为止。参数这时使损失函数达到最低值的状态。
因为神经网络,结构复杂,计算梯度代价很大,所以使用反向传播算法。它从后往前,计算输出层梯度,第二个参数矩阵梯度,中间层梯度,第一个参数矩阵梯度,输出入梯度。
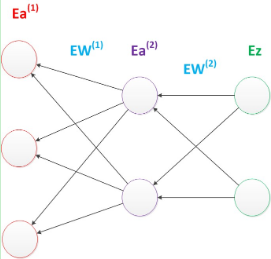
图14 反向传播算法
深度学习中并不只是优化问题,还有在新样本上的预测能力,所以还有使训练的模型具有泛化能力,相关的策略称为正则化方法。例如权重衰减。
Ps:需要补充BP神经网络的相关数学原理,梯度下降的数学原理。
五、多层神经网络(深度学习)
06年Hinton发表深度信念网络,提到了预训练和微调。大幅减少了训练多层神经网络的时间。赋予了深度学习。
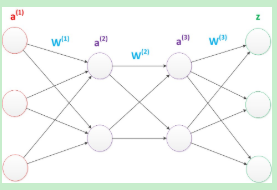
图15 多层神经网络
图16为多层神经网络的推导公式。

图16 推导公式
我们可以看出这张图的参数个数为16个
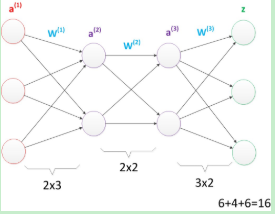
图17 多层神经网络(较少参数)
我们可以在层数不变的基础上,增加神经元的个数。参数为33个
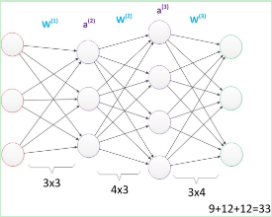
图18 较多参数
也可以在参数一种的情况下,增加层数。
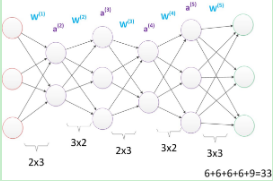
图19 更深层次
相比于两层的神经网络,多层的神经网络。可以深入的表示特征,拥有更强大函数模拟能力。
深入的表示特征,可以理解,随着层数的增加,每一层相比较前一层进行了更抽象的表示。更强的函数模拟能力可以依据数学的原理,可以了解,随着参数的增多模拟的函数就更加的复杂。
研究发现,参数一致的情况下,更深的网络往往比浅层的网络有更好的识别效率。层数可能更重要。
神经网络的不同类别

图20 神经网络的类别
PS:本文简单的介绍了神经网络的发展,下一篇将着重讲解BP神经网络数学原理。