记录一些神经网络结构,先占个坑。。。
文章目录
1.resnet:Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
论文链接:https://arxiv.org/pdf/1512.03385.pdf
网络结构:
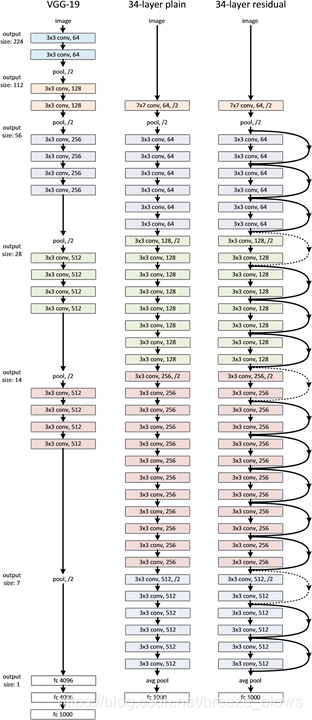

注意点:
- 每经过一个conv_x 都会被下采样一次,除了conv2_x的下采样是由max pool完成,其他的都是由第一个Bottleneck(比如conv3_x是由4个Bottleneck组成)中的第一个conv的stride设置为2完成,比如在conv3_x就是由第一个1 * 1 128的 conv的stride设置为2,残差连接也发生在第一个Bottleneck,Bottleneck中的第二个conv 3*3 的padding设置为1来弥补从而不产生stride。
- resnet中的所有conv的bias都被设置为了false,主要是因为在每个conv后都会接上bn,而bn可以起到这个bias的效果,其实这个操作在其他的网络结构中也很常见,比如SEnet等 参考
- 有时候可以将最后一个conv5_x的第一个Bottleneck的第一个conv 1 * 1 的stride设置为1,所有Bottleneck的第二个conv 3 * 3 的dilation设置为2,作为空洞卷积,从而保证conv5_x虽然不增加stride但是仍然扩大了感受野
- pytorch版本与caffe版本的resnet结构是不一样的,区别在于: If style is “pytorch”, the stride-two layer is the 3x3 conv layer, if it is “caffe”, the stride-two layer is the first 1x1 conv layer.也就是说stride为2的conv位置不同,pytorch在每个Bottleneck的33conv,而caffe在每个Bottleneck的第一个11conv位置,记得原来看AlexNet的时候pytorch版本也与caffe版本有所不同
2. resnext: Aggregated Residual Transformations for Deep Neural Networks
Aggregated Residual Transformations for Deep Neural Networks
论文链接:https://arxiv.org/pdf/1611.05431v2.pdf
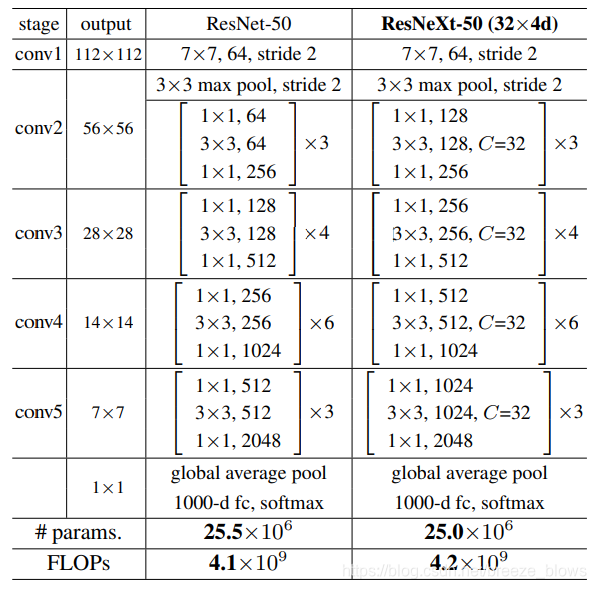
每个Bottleneck结构图
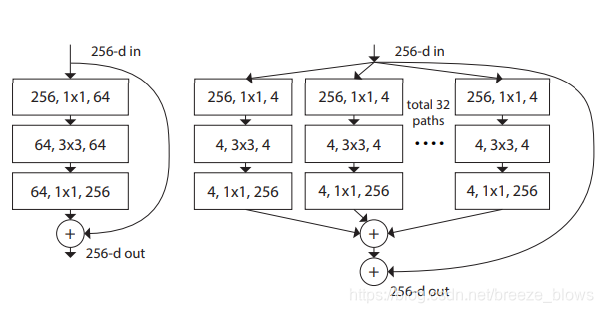
其中resneXt50-32*4d中的32就是指totol 32 paths,4指的是宽度,即每条path的第一个conv的out_channel.
作者通过实验发现以下三种形式是等价的
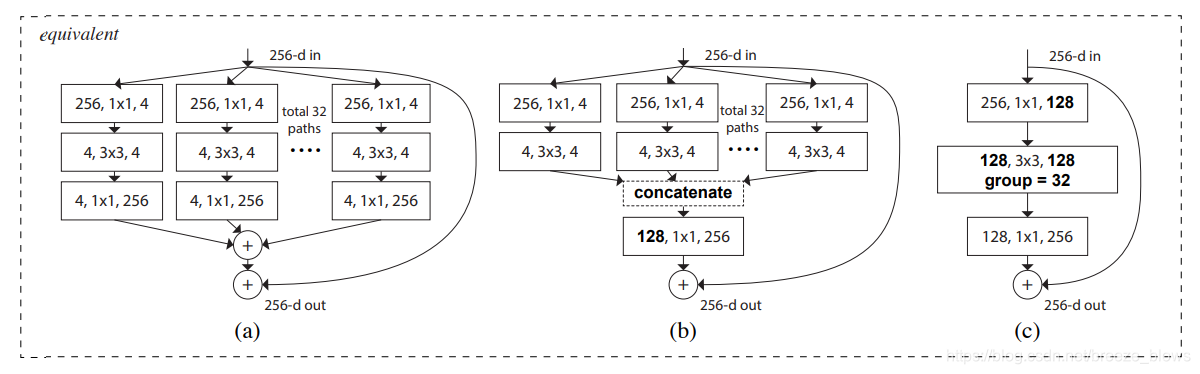
所以在代码实现中就直接采用的图©的形式,主要是更加简洁而且速度更快,其实就是组卷积(分组卷积(Group Convolution)与深度可分离卷积(Depthwise Separable Convolution)),在pytorch中直接通过设置conv的group参数即可
3. Resnest:Split-Attention Networks
ResNeSt: Split-Attention Networks
论文链接:https://hangzhang.org/files/resnest.pdf
代码:https://github.com/zhanghang1989/ResNeSt
对resnet进一步改进,resnest中的s应该代表Split-Attention[code],结构图如下图
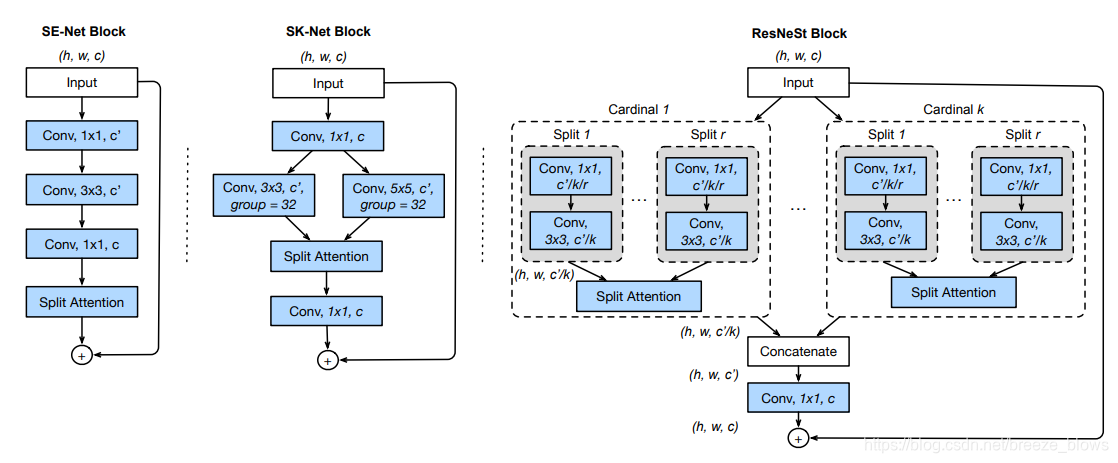
其实就是基于 SENet,SKNet(计算机视觉(CV)中的注意力Attention机制 )和 ResNeXt,把 attention 做到 group level。仿照resnext中cardinal的概念将SKNet 多分支不易模块化做的更加易用一些,可以看出sknet多分支的一种特殊情况,即kernel都是相同的。
实际上在代码中为了方便与检测与分割任务,cardinal取值为1,split r取值为2
resnest-50的结构图:gist
从网络结构中看(这些在文中中4.1 Network Tweaks可以看到),与resnext的区别:
- 第一个conv从单纯的conv 7*7换成了
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace)
(6): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
- 每个layer1的第一个Bottleneck的第一个conv之后利用AvgPool2d(kernel_size=3, stride=2, padding=1)进行下采样,文中描述为采用原来的conv 3*3 stride=2会损失空间信息,shortcut的downsample是采用AvgPool2d(kernel_size=2, stride=2, padding=0)来进行的(第一个layer除外),
- Split-Attention用在每个layer中的每个Bottleneck的第二个conv即conv2