残差网络ResNet系列网络结构详解:从ResNet到DenseNet
1. 残差神经网络综述
AlexNet的提出开启了卷积神经网络应用的先河,随后的GoogleNet、VGG等网络使用了更小的卷积核并加大了深度,证明了卷积神经网络在处理图像问题方面具有更加好的性能;
但是随着层数的不断加深,卷积神经网络也暴露出来许多问题:
- 理论上讲,层数越多、模型越复杂,其性能就应该越好;但是实验证明随着层数的不断加深,性能反而有所下降。
- 深度卷积网络往往存在着梯度消失/梯度爆炸的问题;由于梯度反向传播过程中,如果梯度都大于1,则每一层大于1的梯度会不断相乘,使梯度呈指数型增长;同理如果梯度都小于1,梯度则会逐渐趋于零;使得深度卷积网络难以训练。
- 训练深层网络时会出现退化:随着网络深度的增加,准确率达到饱和,然后迅速退化。
而ResNet提出的残差结构,则一定程度上缓解了模型退化和梯度消失问题:
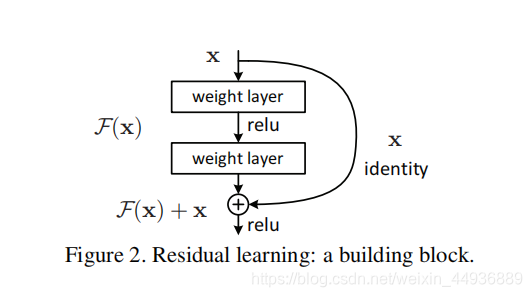
作者提出,在一个结构单元中,如果我们想要学习的映射本来是y=H(x),那么跟学习y=F(x)+x这个映射是等效的;这样就将本来回归的目标函数H(x)转化为F(x)+x,即F(x) = H(x) - x,称之为残差。
于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(x)和x的差值,即去掉映射前后相同的主体部分,从而突出微小的变化,也能够将不同的特征层融合。而且y=F(x)+x在反向传播求导时,x项的导数恒为1这样也解决了梯度消失问题。
2. ResNet详解
2.1 论文地址:
《Deep Residual Learning for Image Recognition》
2.2 核心思想:
将本来回归的目标函数H(x)转化为F(x)+x,即F(x) = H(x) - x,称之为残差。
2.3 网络结构:
2.3.1 残差单元:
ResNet的基本的残差单元如图所示:
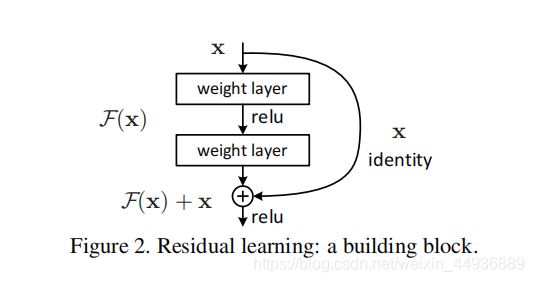
基本结构如图,假设每个单元输入的特征层为x,经过两个卷积层获得输出y,将x与y求和即得到了这个单元的输出;
在训练时,我们将该单元目标映射(即要趋近的最优解)假设为F(x) + x,而输出为y+x,那么训练的目标就变成了使y趋近于F(x)。即去掉映射前后相同的主体部分x,从而突出微小的变化(残差)。
用数学表达式表示为:
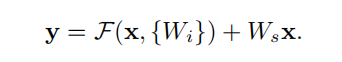
其中:
- x是残差单元的输入;
- y是残差单元的输出;
- F(x)是目标映射;
- {Wi}是残差单元中的卷积层;
- Ws是一个1x1卷积核大小的卷积,作用是给x降维或升维,从而与输出y大小一致(因为需要求和);
2.3.2 改进单元:
同时也可以进一步拓展残差结构:
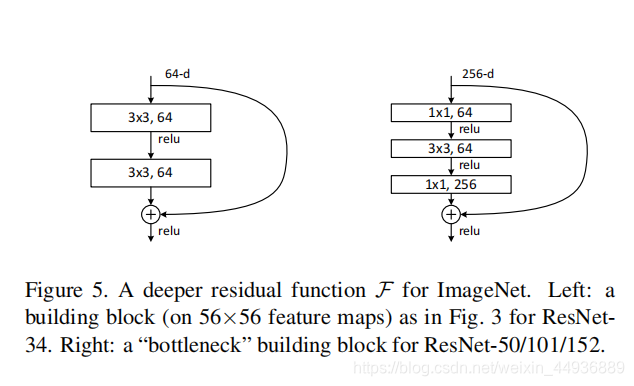
原论文中则以VGG为例:
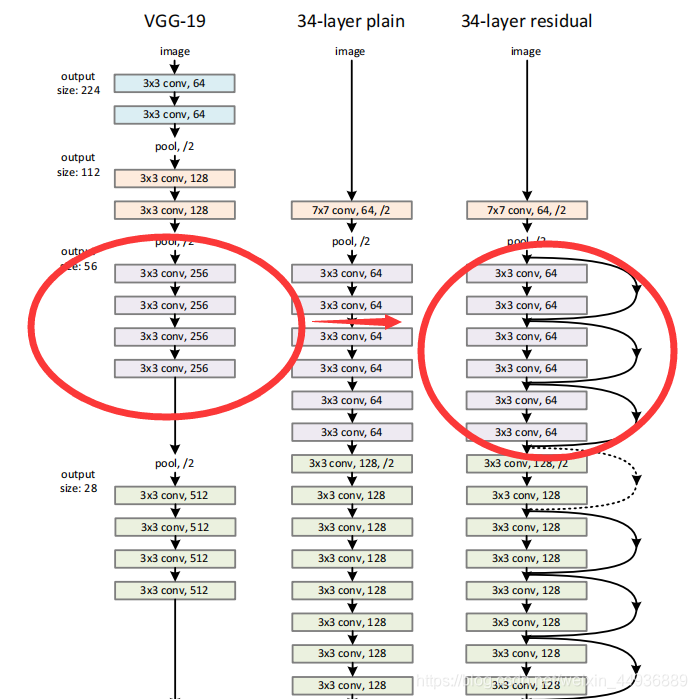
从VGG的19层,拓展到了34层。
可见使用了残差单元可以大大加深卷积神经网络的深度,而且不会影响性能和训练速度.
2.4 实现代码:
传送门:
ResNet-tensorflow
残差单元的实现:
# block1
net = slim.repeat(res, 2, slim.conv2d, 64, [3, 3],
scope='conv1', padding='SAME')
res = net
# block2
net = slim.repeat(res, 2, slim.conv2d, 64, [3, 3],
scope='conv2', padding='SAME')
net = tf.add(net, res) # y=F(x)+x
ResNet的实现:
slim = tf.contrib.slim
def resnet(self, inputs):
with tf.variable_scope('RESNET'):
net = slim.conv2d(inputs, 64, [7, 7],
2, scope='conv7x7', padding='SAME')
net = slim.max_pool2d(net, [2, 2], scope='pool1', padding='SAME')
res = net
# block1
net = slim.repeat(net, 2, slim.conv2d, 64, [3, 3],
scope='conv1', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block2
net = slim.repeat(net, 2, slim.conv2d, 64, [3, 3],
scope='conv2', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block3
net = slim.repeat(net, 2, slim.conv2d, 64, [3, 3],
scope='conv3', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = slim.conv2d(net, 128, [3, 3], 2,
scope='reshape1', padding='SAME')
# block4
net = slim.conv2d(net, 128, [3, 3], 2,
scope='conv4_3x3', padding='SAME')
net = slim.conv2d(net, 128, [3, 3], 1,
scope='conv4_1x1', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block5
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3],
scope='conv5', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block6
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3],
scope='conv6', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block7
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3],
scope='conv7', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = slim.conv2d(net, 256, [3, 3], 2,
scope='reshape2', padding='SAME')
# block8
net = slim.conv2d(net, 256, [3, 3], 2,
scope='conv8_3x3', padding='SAME')
net = slim.conv2d(net, 256, [3, 3], 1,
scope='conv8_1x1', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block9
net = slim.repeat(net, 2, slim.conv2d, 256, [3, 3],
scope='conv9', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block10
net = slim.repeat(net, 2, slim.conv2d, 256, [3, 3],
scope='conv10', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block11
net = slim.repeat(net, 2, slim.conv2d, 256, [3, 3],
scope='conv11', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = slim.conv2d(net, 512, [3, 3], 2,
scope='reshape3', padding='SAME')
# block12
net = slim.conv2d(net, 512, [3, 3], 2,
scope='conv12_3x3', padding='SAME')
net = slim.conv2d(net, 512, [3, 3], 1,
scope='conv12_1x1', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block13
net = slim.repeat(net, 2, slim.conv2d, 512, [3, 3],
scope='conv13', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
res = net
# block14
net = slim.repeat(net, 2, slim.conv2d, 512, [3, 3],
scope='conv14', padding='SAME')
net = tf.add(net, res)
net = tf.layers.batch_normalization(net, training=self.is_training)
avg_pool = slim.avg_pool2d(net, [7, 7], scope='avg_pool')
avg_pool = tf.layers.flatten(avg_pool)
logits = tf.layers.dense(avg_pool, 1000)
if self.is_training:
logits = tf.nn.dropout(logits, keep_prob=self.keep_rate)
logits = tf.layers.dense(logits, self.cls_num)
return tf.nn.softmax(logits, name='softmax')
2.5 实验结果:
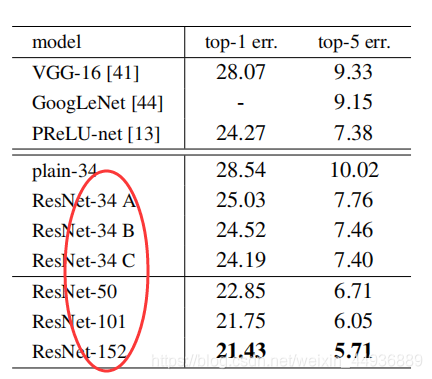
在ImageNet数据集上的测试表明,随着层数的加深,ResNet取得的效果越来越好,有效解决了模型退化的和梯度消失的问题。
3. ResNext详解
3.1 论文地址:
《Aggregated Residual Transformations for Deep Neural Networks》
3.2 核心思想:
对比于之前改进模型的方法,大都是在网络的深度depth(如VGG)和宽度width(如GoogleNet)上改进;这里作者提出一种新改进的方式,命名为Cardinality。
即每个结构单元取多组卷积,分别进行映射;再将每个卷积组的映射求和,再与输入的x求和(与ResNet类似),得到结构单元的输出y。
这样用一种平行堆叠相同拓扑结构,代替原来 ResNet 的三层卷积,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,也减少了参数。
数学公式如图:
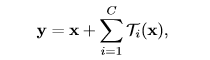
其中:
- x是结构单元的输入;
- y是结构单元的输出;
- C是卷积组的数量;
- Ti(x)是每个卷积组的映射;
3.3 网络结构:
3.3.1 结构单元:

网络结构如上图所示,其中左边是ResNet的残差单元,右边是ResNext的结构单元;
可以看到这里,一个结构单元获取一个depth为256的输入,我们就记为X-256;这里使用了共32组卷积:
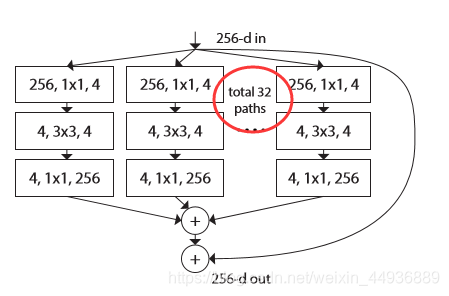
具体过程:
- 每组卷积首先通过4个1x1大小的卷积核进行降维操作,depth变为4以减少参数;
- 然后通过3x3卷积提取特征,最后再通过256个1x1大小的卷积升维返回为原来的深度256;
- 将卷积获得的32组depth为256的特征图求和,再与X-256求和,即得到输出y;
可以看到这里不仅有ResNet的残差思想,也有GoogleNet的Inception的思想;
最后通过类似于VGG的结构单元的堆叠,就得到了ResNext的网络结构:

其中参数C就是每个结构单元的卷积组的数量。
3.3.2 等效结构:
同时作者也列出了等效的结构单元:
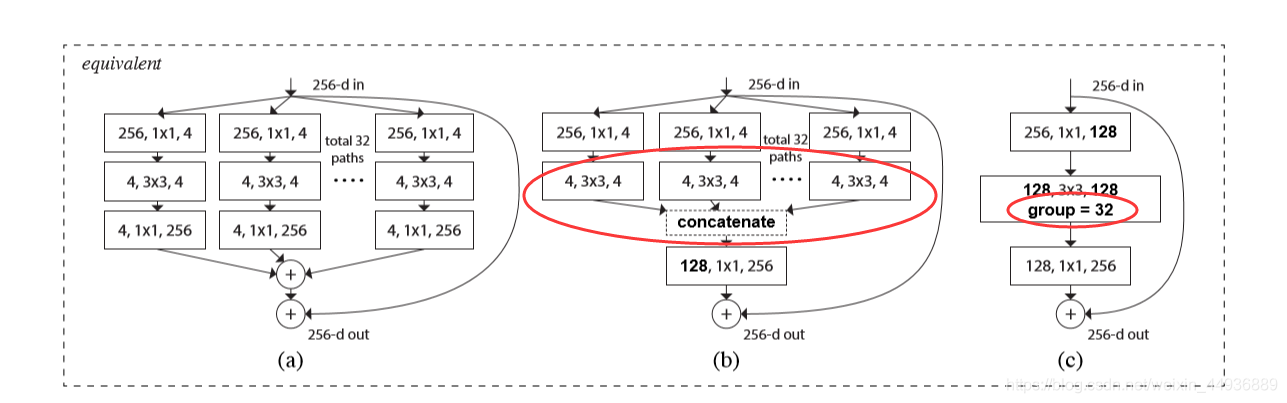
3.4 实现代码:
3.5 实验结果:
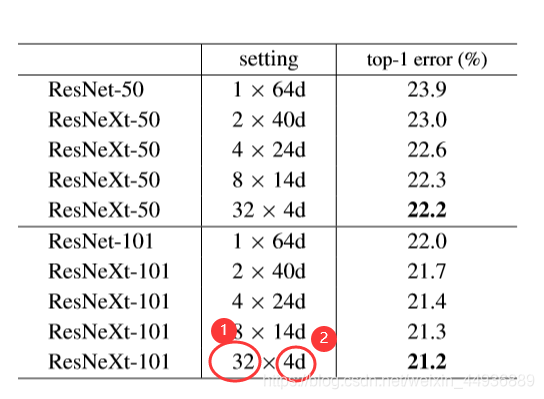
可以看到相同深度下,ResNext 比 ResNet 有更好的性能。
其中的参数:
① 代表每个结构单元的卷积组数;
②代表每组卷积降维后的depth;
4. DenseNet详解
4.1 论文地址:
《Densenet: densely connected convolutional networks》
4.2 核心思想:
当CNN增加深度的时候,就会出现一个紧要的问题:当输入或者梯度的信息通过很多层之后,它可能会消失或过度膨胀。作者提出的架构为了确保网络层之间的最大信息流,将所有层直接彼此连接。
主要思想是将每一层都与后面的层都紧密(Dense)连接起来,将特征图重复利用,网络更窄,参数更少,对特征层能够更有效地利用和传递,并减轻了梯度消失的问题。
这种连接方式使得网络的梯度信息在层与层之间更紧密地传递,从而使网络更加容易训练并能够在一定程度上防止过拟合。
4.3 网络结构:
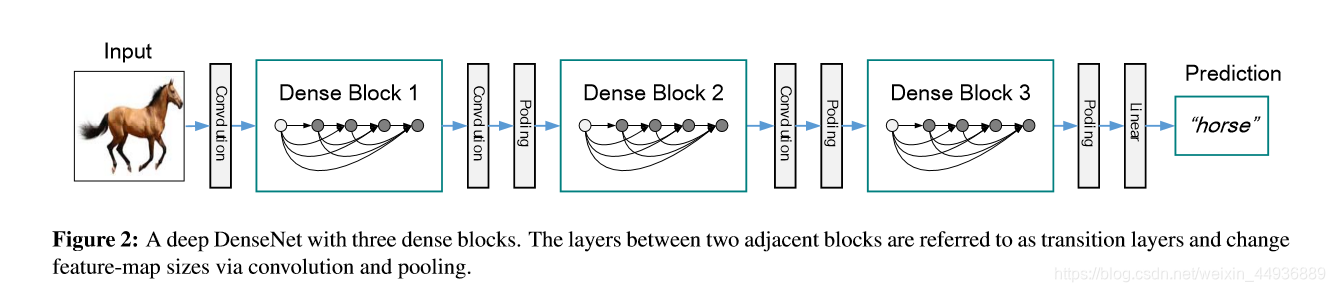
4.3.1 结构单元:
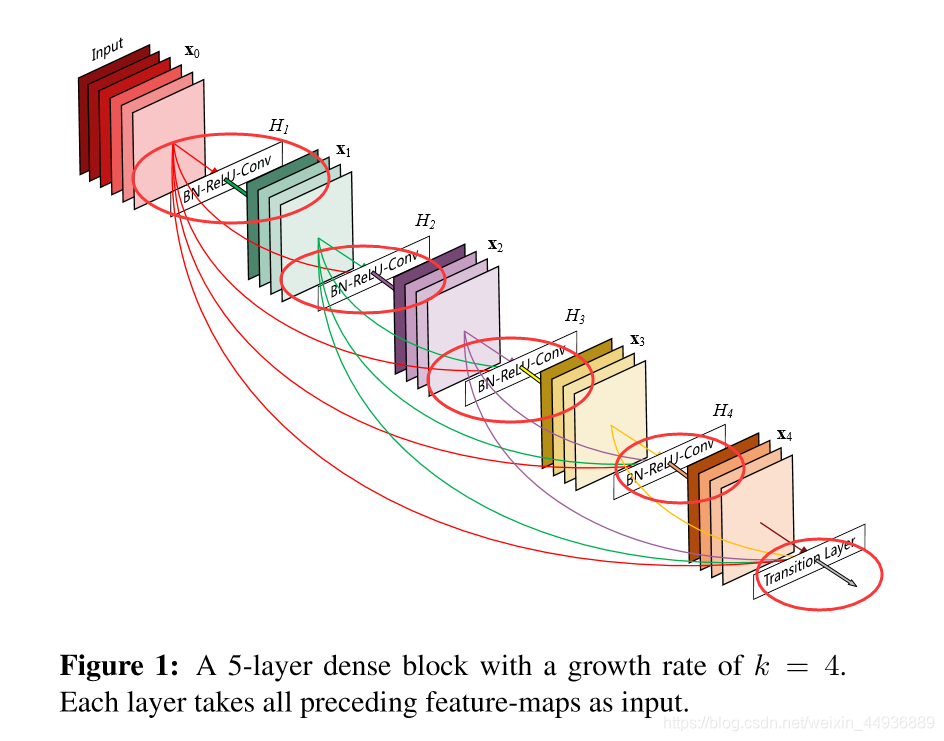
如图所示,在一个DenseNet结构单元中,前面的特征层会与它后面的所有特征层相连,称之为Dense Block,其具体结构为:
X —>(BN+ReLU+3x3 Conv)× 4 —> translation layer;
(BN为batch normalization)
其中子单元(BN+ReLU+3x3Conv)的depth称为growth rate,一般取为32;
4.3.2 Bottleneck Layer:
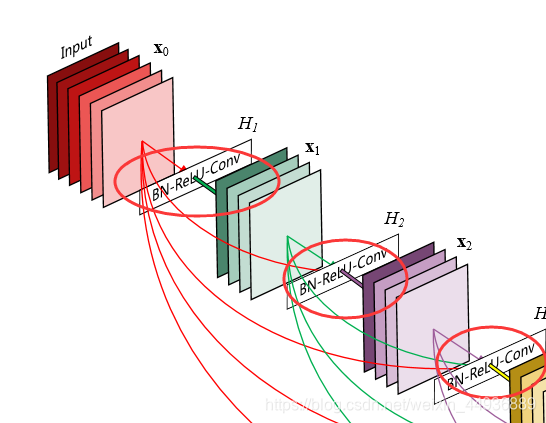
有文章中指出,在每3×3卷积之前可以引入1×1卷积作为瓶颈层,可以减少输入特征映射的数量,从而提高计算效率。
作者就将子单元(BN-ReLU-3x3Conv)改成了bottleneck layer:
(BN+ReLU+1x1Conv—>BN+ReLU-3x3Conv)
4.3.3 Translation Layer:
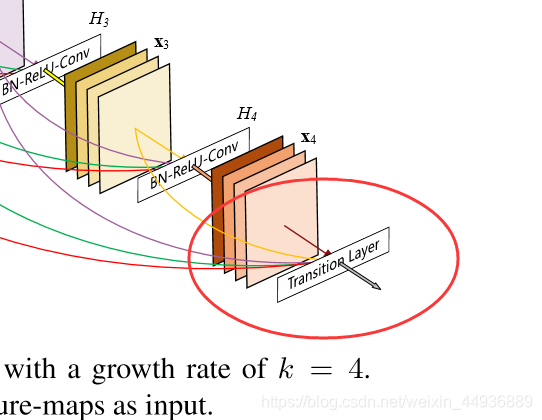
为了解决前后特征层深度和尺寸不同的问题,作者加入了Translation Layer:
BN+Relu+1x1Conv+Pooling
4.3.4 总体结构:
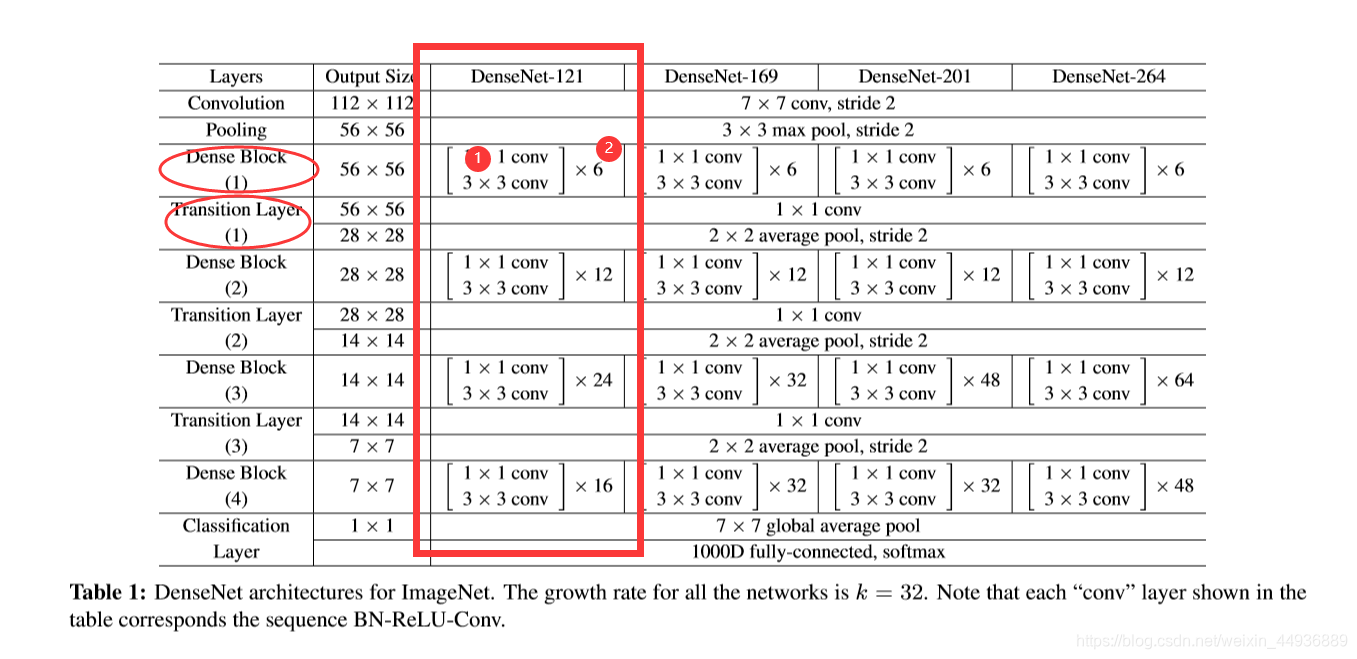
以DenseNet-121为例,每个DenseBlock都会连接一个Transition Layer;
参数:
① 一个Bottleneck Layer,可以看到是一个1x1卷积连接一个3x3卷积;
② 一个DenseBlock中Bottleneck Layer的数目;
4.4 实现代码:
4.4.1 Bottleneck Layer的实现:
def Dense_Block(self, inputs, scope, block_num=6):
net = inputs
tmp = []
with tf.variable_scope(scope):
net = slim.conv2d(inputs, self.growth_rate, [1, 1],
scope='conv1x1', padding='SAME')
for k in range(block_num):
tmp.append(self.copy_tensor(net))
net = slim.conv2d(inputs, self.growth_rate, [1, 1],
scope='conv1x1_{}'.format(k), padding='SAME')
net = slim.conv2d(inputs, self.growth_rate, [3, 3],
scope='conv3x3_{}'.format(k), padding='SAME')
for value in tmp:
net = tf.add(net, value)
return net
4.4.2 Translation Layer的实现:
def Transition_Layer(self, inputs, scope):
net = inputs
with tf.variable_scope(self):
net = slim.conv2d(inputs, self.growth_rate, [1, 1],
scope='conv1x1', padding='SAME')
net = slim.max_pool2d(
net, [2, 2], scope='pool2x2', padding='SAME')
return net
4.5 实验结果:
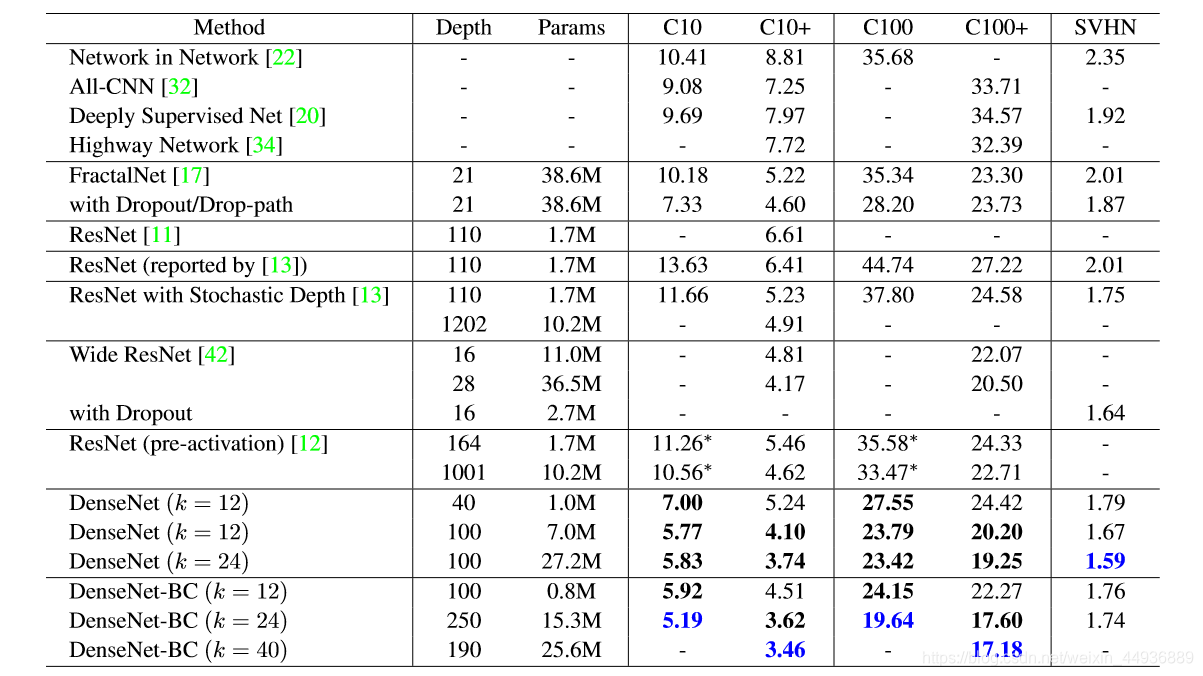
5. 总结
特征层与特征层之间紧密的连接和重复利用,是残差神经网络的基本思想,这样不仅提高了特征层的有效利用和信息的利用率、防止了梯度消失,也减少了参数,一定程度上抑制了过拟合。
如果对你有帮助的话,记得点赞关注哦~

