《Densely Connected Convolutional Networks 》
- 2017,Gao Huang et al,DenseNet
作者通过观察目前深度网络的一个重要特点就是都加入了shorter connections,能够让网络更深、更准确、更高效。作者充分利用了skip connection,设计了一种稠密卷积神经网络(Dense Convolutional Network),让每一层都接受它前面所有层的输出。对于传统卷积结构,L层一共有L个connections,但DenseNet,L层一共有L(L-1)/2个connection。
DenseNet优点:缓解梯度消失问题,加强特征传播,鼓励特征复用,减少计算量。
前向对比:
1)传统卷积:
将第上一层的输出作为下一层的输入:

2)ResNet:
除了本层与下一层的连接之外,还增加了一个skip-connection:
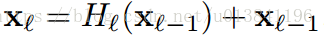
3)DenseNet:

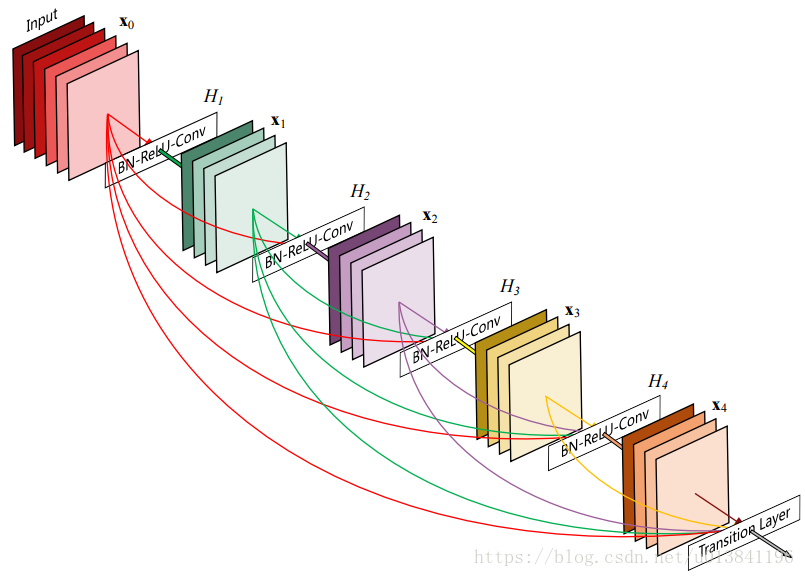
DenseNet结构:

DenseNet的整体结构主要包含稠密块(Dense Blocks)和过渡块(transition layers)。
Dense Blocks内部必须特征图大小一致,每层的输入是concat连接,而不是ResNet的element-wise连接,内部的每一个节点代表BN+ReLU+Conv(参考ResNet V2),每个卷积层都是3*3*k的filter,其中k被称为growth rate。Transition layers中包含的Pooling层会改变特征图的大小。若每个Dense Block有12层,输入到该block的feature map数为16,k=12,则第一个Dense Block所有输出的concat起来的feature map数是16+12*12 =160,transition layer节点由BN-Conv-Pool组成,卷积由1*1构成,num_out数保持和输入一致,第二、三个的输出feature map数量分别是160+12*12 = 304,304+12*12 = 448。
5层的Dense Blocks及growth rate k = 4,如下图所示:
为了进一步较少参数量,作者进行一下改进:
Bottleneck layers:尽管每个网络层只输出 k 个特征图,但是同时仍然有太多的输入个数,通常的做法是降维,在进行3×3卷积之前首先用一个 1×1卷积将输入个数降低到 4*k, 也就是在 H的定义中再加入一个 1×1卷积 ,即BN-ReLU-Conv(1*1)-BN-ReLU-Conv(3*3)的结构,记为DenseNet-B。
Compression(压缩):多过渡层的特征图进行压缩,产生个特征图,其中,为压缩因子,当θ<1时,记为DenseNet-C。
综上,当bottleneck和compression结合起来,模型记为:DenseNet-BC。
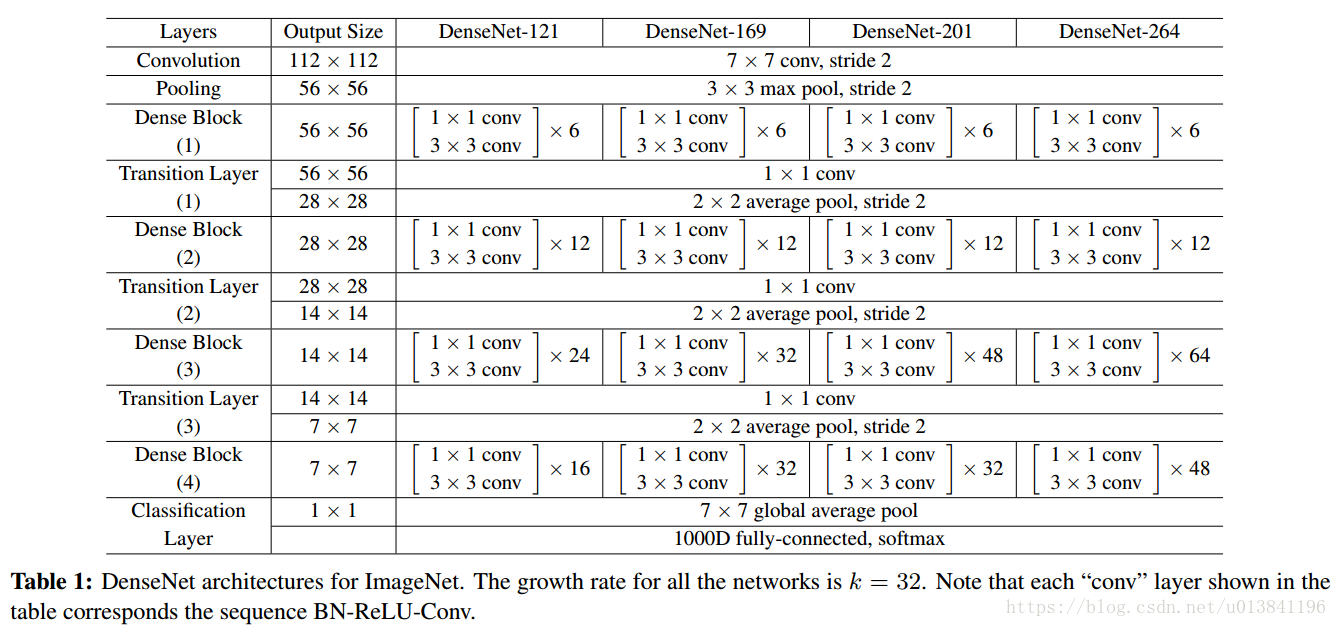
DenseNet结构图:
实验结果:
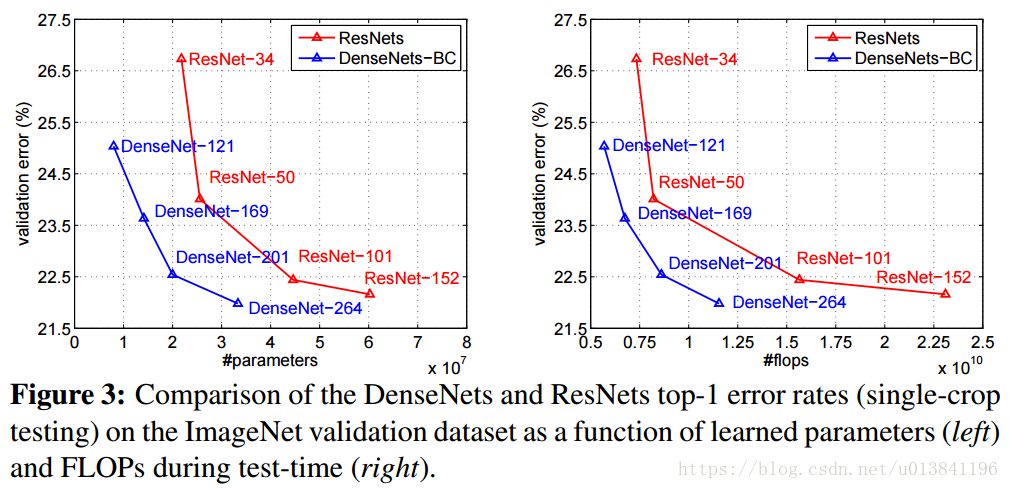

DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Translation layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。DenseNet优点很多,而且在和ResNet的对比中优势还是非常明显的。