《Learning a Similarity Metric Discriminatively, with Application to Face 》
- CVPR 2005,Sumit Chopra、Raia Hadsell、Yann LeCun. Siamese Network
参考:https://blog.csdn.net/sxf1061926959/article/details/54836696
参考:https://blog.csdn.net/qq1483661204/article/details/79039702/
引言:
Siamese网络是一种相似性度量方法,当类别数多,但每个类别的样本数量少的情况下可用于类别的识别、分类等。传统的用于区分的分类方法是需要确切的知道每个样本属于哪个类,需要针对每个样本有确切的标签。而且相对来说标签的数量是不会太多的。当类别数量过多,每个类别的样本数量又相对较少的情况下,这些方法就不那么适用了。其实也很好理解,对于整个数据集来说,我们的数据量是有的,但是对于每个类别来说,可以只有几个样本,那么用分类算法去做的话,由于每个类别的样本太少,我们根本训练不出什么好的结果,所以只能去找个新的方法来对这种数据集进行训练,从而提出了siamese网络。siamese网络从数据中去学习一个相似性度量,用这个学习出来的度量去比较和匹配新的未知类别的样本。这个方法能被应用于那些类别数多或者整个训练样本无法用于之前方法训练的分类问题。
网络结构:
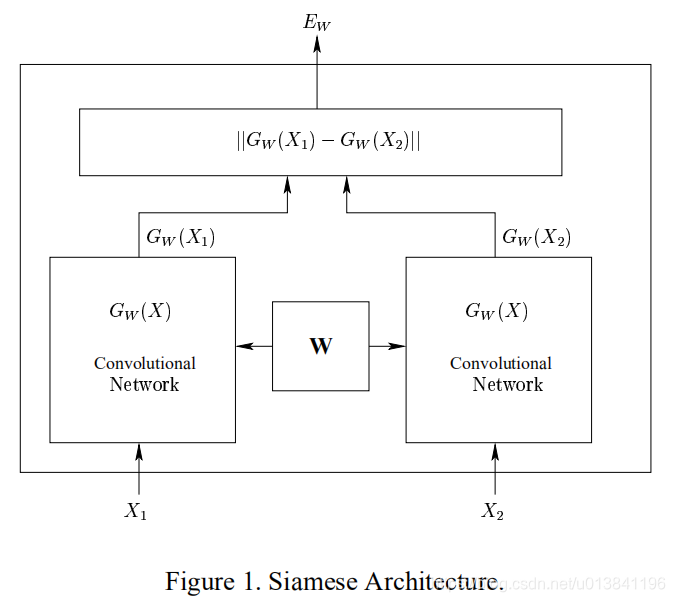
左右两边两个网络是完全相同的网络结构,它们共享相同的权值W,输入数据为一对图片(X1,X2,Y),其中Y=0表示X1和X2属于同一个人的脸,Y=1则表示不为同一个人。即相同对为(X1,X2,0),欺骗对为(X1,X2,1)针对两个不同的输入X1和X2,分别输出低维空间结果分别是Gw(x1)和Gw(x2),这个网络的很好理解,当输入是同一张图片的时候,我们希望它们之间的欧式距离很小,当不是一张图片时,我们的欧式距离很大。有了网路结构,接下来就是定义损失函数,这个很重要,而经过我们的分析,我们可以知道,损失函数的特点应该是这样的,
(1) 当我们输入同一张图片时,他们之间的欧式距离越小,损失是越小的,距离越大,损失越大
(2) 当我们的输入是不同的图片的时候,他们之间的距离越大,损失越大
即:最小化相同类的数据之间距离,最大化不同类之间的距离。
损失函数定义:
首先是定义距离,使用l2范数,公式如下:
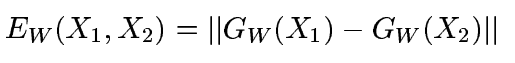
损失函数的形式为:

其中
是第i个样本,是由一对图片和一个标签组成的,其中LG是只计算相同类别对图片的损失函数,LI是只计算不相同类别对图片的损失函数。P是训练的样本数。通过这样分开设计,可以达到当我们要最小化损失函数的时候,可以减少相同类别对的能量,增加不相同对的能量。很简单直观的方法是实现这个的话,我们只要将LG设计成单调增加,让LI单调递减就可以了,但是我们要保证一个前提就是,不相同的图片对距离肯定要比相同图片对的距离小,那么就是要满足:
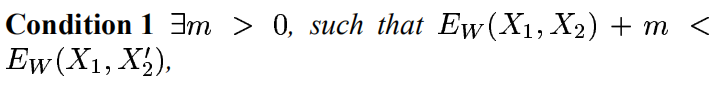
其他条件如下:

然后作者也给出了证明,最终损失函数为:
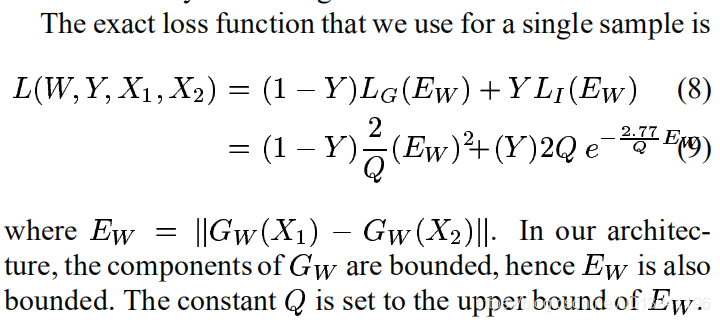
Q是一个常数。
需要强调的是,代码中同一类图片是0,不同类图片是1,使用tensorflow实现的这个损失函数如下:
代码:
def siamese_loss(model1, model2, y):
# L(W,Y,X1,X2) = Y*2/Q*||CNN(p1i)-CNN(p2i)||^2 + (1-Y)*2*Q*exp(-2.77/Q*||CNN(p1i)-CNN(p2i)||
margin = 5.0
Q = tf.constant(margin, name="Q", dtype=tf.float32)
E_w = tf.sqrt(tf.reduce_sum(tf.square(model1 - model2),1))
pos = tf.multiply(tf.multiply(tf.to_float(y), 2/Q), tf.square(E_w))
neg = tf.multiply(tf.multiply(tf.to_float(1-y),2*Q),tf.exp(-2.77/Q*E_w))
loss = pos + neg
loss = tf.reduce_mean(loss, name="loss")
return model1, model2, loss