看了一段时间吴恩达老师的深度学习微课程,收获较大,这阶段做个总结。
算法开发包含算法框架开发、网络结构开发及改进、算法应用优化及模型训练、网络模型压缩这几个方向。今天主要总结下网络结构开发及改进方面相关的。
模型开发一般包含3方面工作,新网络结构提出、现有网络功能单元增加、现有网络的局部算法优化:
- 解决某一类问题的新的网络结构提出
新的算法模型的开发一般为了解决几个问题:
- 提升某一类问题的精度和准确度
- 减少计算量
- 减少参数数量,降低计算及存储硬件需求
比如用于图片分类的CNN网络以,他们在上述3个方面都表现优异。
我们以经典的AlexNet来看,引入卷积层后比全连接减少的参数学习数量。

我们只对比第一层,当引入卷积层后,他的参数数量是11x11x3x96+96(96个卷积核,每个核大小是11x11),也就是第1个卷积层有34944个参数需要学习,若采用全连接的方式,即使L1的节点数量是4096个,需要学习的参数是227x227x3x4096=633M.
因此引入卷积层后减少的参数数量是惊人的。
- 现有网络结构功能添加及演进
现有网络结构的功能添加以及演进一般为解决以下两类问题:
- 引入更深的网络解决更复杂问题
- 解决深度加深后引起的计算增长以及梯度收敛问题。
比如CNN实际上是指卷积神经网络这一大类,其中还包括多种网络模型,为了解决深度加深后出现的计算问题,结构不断演进:
- LetNet-5
- AlexNet
- VGG-16(16指16个层)
- ResNet(为了解决层数较深时的梯度爆炸和梯度消失,引入了Residual Block,跳跃连接)
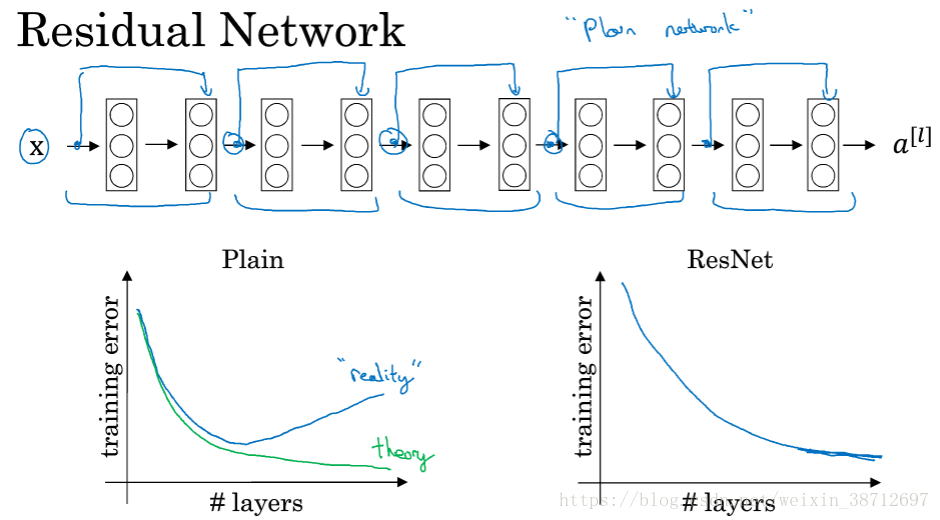
- Inception(同一层采用多种尺寸的卷积核,采用不同大小的卷积核意味着可以获取不同尺度特征的融合)
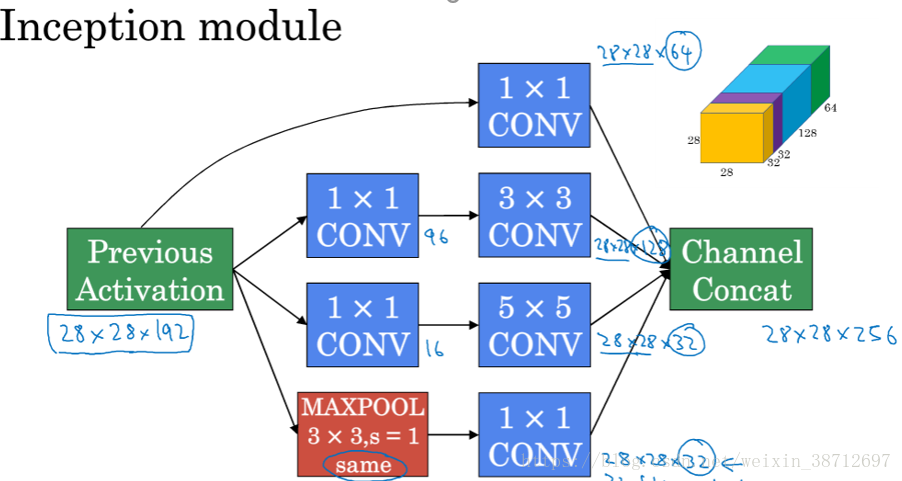
- 现有网络局部算法优化
- 参数初始化
深度神经网络时,由于ReLU这些非线性函数的叠加,weight initialization对模型收敛速度和模型质量有重要影响。主要原因是:
深度很深后,后面几层的每一层输出结果分布在0附近,根据链式法则,输出值是计算gradient中的乘法因子,直接导致gradient很小,使得参数难以被更新。
因此不少研究人员提出一些方法,从参数初始化改善这个问题,比如:
Xavier Glorot et al.在2010年提出Xavier initialization。
Kaiming He et al.在2015年提出He initialization。
Sergey Ioffe et al.在2015年提出Batch Normalization。
这些初始化方法相比随机初始化极大提升了收敛速度。
从编程实践看,似乎He initialization效果最好。
- 反向传播优化算法
好的反向传播算法可以极大提升收敛速度,特别在使用mini-batch的时候。目前的深度学习都是针对大数据,因此每次迭代不会使用全集,而是把数据随机分成很多mini-batch,而mini-batch间的数据分布是存在差异性,因此采用梯度下降更新参数时需要进行平滑操作。梯度下降算法的优化由此而来。
- Momentum算法
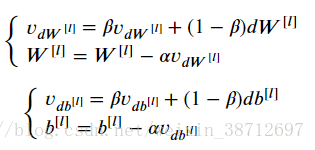

- RMSprop(Root Mean Square Prop(均方根传播))
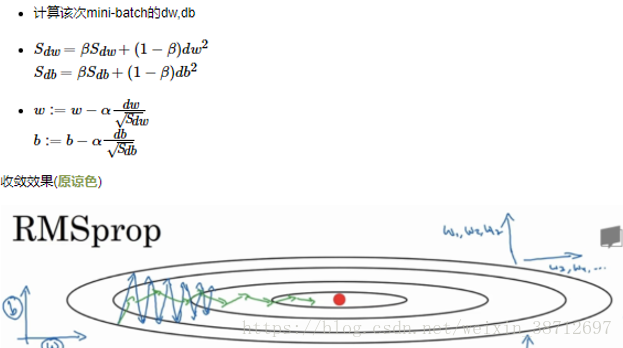
3)ADAM算法
而ADAM算法结合了Momentum和RMSprop,是目前最有效的优化算法之一。
