《ImageNet Classification with Deep Convolutional Neural Networks》
- 2012,Alex Krizhevsky et al,AlexNet
ALexNet可以算是LeNet的一种更深更宽的版本。
AlexNet中包含了几个比较新的技术点,首次在CNN中成功应用了ReLU、Dropout和LRN等trick,同时AlexNet也使用了GPU进行运算加速。
AlexNet拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有三个全连接层。AlexNet以显著的优势赢得了竞争激烈的ILSVRC 2012比赛,top-5的错误率降低至了16.4%,相比第二名的成绩26.2%错误率有了巨大的提升。
网络结构:

AlexNet新的技术点:五个卷积层+三个全连接层
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid函数,成功解决了Sigmoid在网络较深时的梯度弥散(消失)现象。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。在AlexNet中主要是最后的几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。以前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小(eg:size=[3,3], stride=2.),这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性,减少了信息的丢失(最大池化:可以保留最显著的特征)。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大值变得更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算,双卡通信。
(6)数据增强:Data Augmentation
- 方法1:随机裁剪,训练:随机的从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了(256-224)的平方的2倍=2048倍的数据量。
测试:取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对它们进行预测并对10次结果求平均。
- 方法2:对RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
AlexNet输入的图片尺寸为224*224,第一层使用了较大的卷积核尺寸11*11,步长为4,有96个卷积核;紧接着一个LRN层;然后是一个3*3的最大池化层,步长为2。这之后的卷积核都比较小,都是5*5或者3*3的大小,并且步长都为1,即会扫描全图所有像素;而最大池化层依然保持为3*3,并且步长为2,出现在第一个和第二个以及最后一个卷积层之后。
注:卷积层虽然计算量很大,但参数量只占AlexNet总参数量的很小一部分。这就是卷积层有用的地方,可以通过较少的参数量提取有效的特征。
析:Dropout 为什么奏效?
Dropout 背后的原理与模型集成类似。由于 Dropout 层的作用,关闭的不同神经元集呈现一种不同的架构,并行训练所有这些不同架构,赋予每个子集权重,权重的总和为 1。如果 Dropout 连接了 n 个神经元,则子集架构的数量是 2^n。因此,预测是对所有这些模型的集成取平均。Dropout 有用的另一个原因是:由于神经元是随机选择的,因此它们更有可能避免产生共适应(co-adaptation),从而产生独立于其他神经元的有意义的特征。
Dropout率的选择:
(1)经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。
(2)dropout也可以被用作一种添加噪声的方法,直接对input进行操作。输入层设为更接近1的数。使得输入变化不会太大(0.8)。
注:Dropout会增加模型训练的时间,但大大推迟了过拟合。
析:ReLU:使用ReLU时,使Learning Rates尽量小
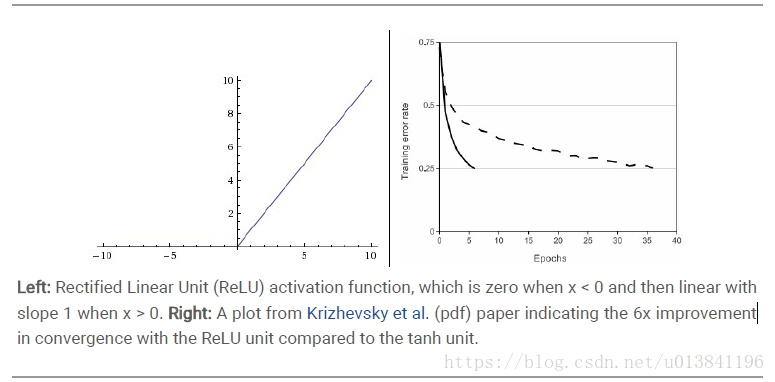
ReLU的数学公式:
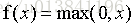
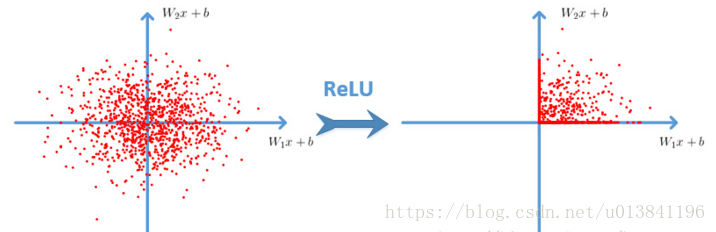
很显然,从图左可以看出,输入信号<0时,输出都是0,输入信号>0 的情况下,输出等于输入。w 是二维的情况下,使用ReLU之后的效果如下:
(1)优点: Krizhevsky et al. 发现使用 ReLU 得到的SGD的收敛速度会比 Sigmoid/tanh 快很多(看右图)。有人说这是因为它是linear,而且 non-saturating ,相比于 Sigmoid/tanh,ReLU 只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。
(2)缺点: 当然 ReLU 也有缺点,就是训练的时候很”脆弱”,很容易就”die”了。
举个例子:一个非常大的梯度流过ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。 如果这个情况发生了,那么这个神经元的梯度就永远都会是0。
注:实际操作中,设置learning rate 很大,那么很有可能你网络中的40%的神经元都”dead”了。 设置一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。