系列文章目录
神经网络学习笔记1——ResNet残差网络、Batch Normalization理解与代码
前言
VGGNet是牛津大学视觉几何组(Visual Geometry Group)提出的模型,该模型在2014ImageNet图像分类与定位挑战赛 ILSVRC-2014中取得在分类任务第二,定位任务第一的优异成绩。VGGNet突出的贡献是证明了很小的卷积,通过增加网络深度可以有效提高性能。VGG很好的继承了Alexnet的衣钵同时拥有着鲜明的特点,即网络层次较深。
VGGNet模型有A-E五种结构网络,深度分别为11,11,13,16,19。其中较为典型的网络结构主要有vgg16和vgg19,两者并没有本质上的区别,只是网络深度不一样。
一、结构展示
1、VGG16图形化

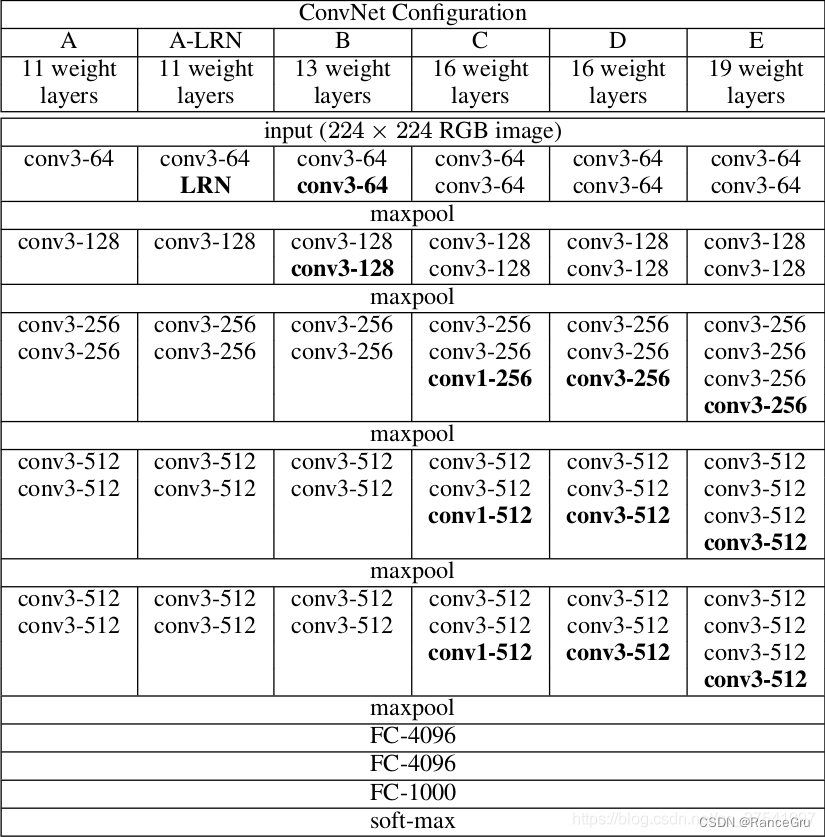
2、VGG表格化
二、结构学习
1、特点
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5x5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3x(9xC^2) ,如果直接使用7x7卷积核,其参数总量为 49x(C^2) ,这里 C指的是输入和输出的通道数。很明显,27x(C^2)小于 49x(C^2),即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
3x3与7x7的参数数量对比:

2、VGG16模型详解


conv(卷积处理)的stride为1,padding为1
maxpool(最大化池化)的size为2,stride为2
input(224x224x3)——>softmax:
Conv1:
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核64,使得高宽不变,卷积核从3个更改为64个,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核64,使得高宽不变,卷积核从3个更改为64个,并调用激活函数ReLU。
max pooling:
通过设置步长stride=2、池化尺寸size=2x2(效果为图像尺寸减半),池化后使得高宽从224缩减一半到112,卷积核个数不变。
Conv2:
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核128,使得高宽不变,卷积核从64个更改为128个,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核128,使得高宽不变,卷积核从64个更改为128个,并调用激活函数ReLU。
max pooling:
通过设置步长stride=2、池化尺寸size=2x2(效果为图像尺寸减半),池化后使得高宽从112缩减一半到56,卷积核个数不变。
Conv3:
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核256,使得高宽不变,卷积核从128个更改为256个,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核256,使得高宽不变,卷积核从128个更改为256个,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核256,使得高宽不变,卷积核从128个更改为256个,并调用激活函数ReLU。
max pooling:
通过设置步长stride=2、池化尺寸size=2x2(效果为图像尺寸减半),池化后使得高宽从56缩减一半到28,卷积核个数不变。
Conv4:
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核512,使得高宽不变,卷积核从256个更改为512个,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核512,使得高宽不变,卷积核从256个更改为512个,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核512,使得高宽不变,卷积核从256个更改为512个,并调用激活函数ReLU。
max pooling:
通过设置步长stride=2、池化尺寸size=2x2(效果为图像尺寸减半),池化后使得高宽从28缩减一半到14,卷积核个数不变。
Conv4:
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核512,使得高宽不变,卷积核个数不变,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核512,使得高宽不变,卷积核个数不变,并调用激活函数ReLU。
- 通过设置步长stride=1、卷积尺寸size=3x3和卷积核512,使得高宽不变,卷积核个数不变,并调用激活函数ReLU。
max pooling:
通过设置步长stride=2、池化尺寸size=2x2(效果为图像尺寸减半),池化后使得高宽从14缩减一半到7,卷积核个数不变。
FC1:
接受输出为7x7x512,设置输出为4096节点进行全连接计算,并调用激活函数ReLU。
FC2:
接受输出为1x1x4096,设置输出为4096节点进行全连接计算,并调用激活函数ReLU。
FC3:
接受输出为1x1x4096,设置输出为1000节点进行全连接计算,并调用线性函数Linear。
softmax:
调用归一化指数函数,进行自定义概率分布分类。

三、感受野

感受野(receptive field)这一概念来自于生物神经科学,是指感觉系统中的任一神经元,其所受到的感受器神经元的支配范围。感受器神经元就是指接收感觉信号的最初级神经元。比如视觉的产生来自于光在个体感受器上的投射,将客观世界的物理信息转换为人能感知的神经脉冲信号。
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域。它是可以存在于网络中任意某层,输出仅由输入部分决定,就是指输出feature map上某个元素受输入图像上影响的区域。


四、python代码
结合VGGNet和感受野理论制作一个pytorch版本的网络模型
import torch.nn as nn
import torch
cfgs = {
'vgg11':[64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13':[64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16':[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19':[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
def make_features(cfg:list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2,stride=2)]
else:
conv2d = nn.Conv2d(in_channels,v,kernel_size=3,padding=1)
layers += [conv2d,nn.ReLU(True)]
in_channels = v
# 通过非关键字传入进去
return nn.Sequential(*layers)
class VGG(nn.Module):
def __init__(self,features,class_num=1000,init_weights=False):
super(VGG,self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(2048,4096),
nn.ReLU(True),
nn.Linear(4096,class_num)
)
if init_weights:
self._initialize_weights()
def forward(self,x):
x = self.features(x)
x = torch.flatten(x,start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias,0)
def vgg(modul_name="vgg16",**kwargs):
try:
cfg = cfgs[modul_name]
except:
print("{} not in cfgs".format(modul_name))
exit(-1)
modul = VGG(make_features(cfg),**kwargs)
return modul
vgg_model = vgg(modul_name='vgg16')