一、发展历史
卷积神经网络(Convolutional Neural Network)是一种常见的用于图像分类的深度学习框架,它可以看作是一种对输入信号逐层加工,最后将联系并不密切的输入和输出信息连接起来的分类网络。CNN的网络结构的起源是LaNet5(包含了卷积、池化和非线性的激活函数以及多层感知机模型),之后在2012年Alex Krizhevsky提出了一种AlexNet网络结构在当年获得了图像识别大赛的冠军。AlexNet主要在三个方面做出了改进:
1.使用Relu激活函数替代了传统的Sigmod(优点下文会详细描述)
2.使用两块GPU训练(目前的神经网络已经全部由GPU进行模型训练,GPU在矩阵运算和数值运算上速度更有优势)
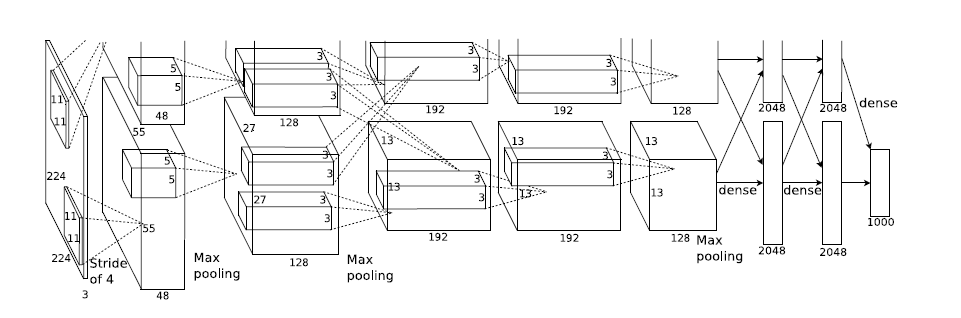
3.DropOut的提出,即随机选择一部分神经元不参加前向传播和反向传播,可以有效防止过拟合的现象同时大大降低训练时间 至此,传统的CNN网络结构趋于成熟,后续的卷积神经网络向各个方向发展,功能也更加丰富,如加深传统网络结构的VGG16,由单纯的分类到定位分类的RCNN等,如下图(图像引用于【1】)

二、概念理解
1.卷积(convolution)
顾名思义,卷积神经网络最重要的概念就是卷积,首先卷积用于很多方面,比如:统计学中,加权的滑动平均是一种卷积;概率论中,两个统计独立变量X与Y的和的概率密度函数是X与Y的概率密度函数的卷积;物理学中,任何一个线性系统(符合叠加原理)都存在卷积等等。最常用的是在数字信号处理上面,引用知乎作者【张俊博】的解释,卷积在信号处理上的意义就是加权叠加,对于线性时不变系统,如果知道该系统的单位响应,那么将单位响应和输入信号求卷积,就相当于把输入信号的各个时间点的单位响应加权叠加,就直接得到了输出信号,作者解释的很通俗,卷积就是通过输入信号的单位响应得到输出信号的过程。根据作者的解释我大概理解是,一个时间点的输入信号并不是只对这一瞬间的输出信号有影响的,而是在一段时间中它的影响会衰减,但连续的信号又会不停的输入进来,已经知道一个时间点的单位信号量产生的的响应,那卷积就是去求这个连续时间段的输出响应。
对于我没有太多数学基础可以不去深究卷积的数学意义,只用知道它是一种数学运算,而应用到深度学习中,卷积同样是信息的加权叠加,它的物理意义就更好理解,形象的讲卷积是将两种信息进行混合而得到一种新的信息,而在CNN中混合这两种信息分别是图像和卷积核(convolution kernel)。图像是一个由多个数字组成的矩阵,而卷积核同样是一个用户自定义的数字矩阵,通过这个混合过程会得到我们所说的特征图(feature map)。为什么需要卷积这么一个过程呢?其实卷积操作在图像分类中起到的作用就是以一定的卷积核对图像进行特征提取,而这个卷积核也称滤波器,就是用来提取特征的一个工具。例如我们判断衣服的颜色,那衣服的形状就不重要了,刚刚将到这个衣服的图像由矩阵构成,如果这个区域对衣服的颜色区分很有作用,那经过卷积核提取的特征值就很大,如果作用小,特征值就小,当然在这个过程中由于做了加权叠加的过程也可以过滤掉这个区域的一些噪声点(如低通滤波可以过滤掉高频噪声点:在一个3×3的矩阵中,有一个数据特别高,做一次卷积之后,得到的数据就是这对这个区域进行平滑操作之后的值)。那这个卷积核如何知道这块区域的数据的作用大小呢?这我们需要机器训练的原因,最开始有许许多多的随机初始化的卷积核在训练开始之时,它们不认识任何特征,在每次的训练过程(反向传播的机制)中去修改这个卷积核即权重(具体过程下文会介绍),最后得到的卷积核是不是就认识这个特征了呢(特征值更高)?它提取的特征图用于分类的效果自然也会很好,如下图就是一个提取特征图过程,当然不管是原图还是特征图在算法中都是以矩阵的形式出现,在这里形象化的显示了出来。

2.池化(poling)
相比于卷积池化就很好理解,池化分为最大池化、平均池化、滑动平均池化、L2范数池化等,最常见的是Average_pooling、Max_pooling也就是在一个规定的区域中进行求均值、求最大值的操作,实际上是对特征进行下采样,目的是特征矩阵稀疏化,降低后续运算量以及增强分类效果。(具体操作下文会介绍)
三、网络结构
1.输入层
网络的输入层是图像矩阵,图像是由一个个像素点构成,在计算机中图像的每一个像素点是0到255数字代表的,为了保持图像平面结构的信息,通常选择用矩阵表示图像,比如minist数据集中的图像就是由784个像素点(数值)组成,那我们用28x28的矩阵表示它。普遍的图片是RGB模型,即红(Red)、绿(Green)、蓝(Blue)三原色的色光以不同的比例相加,以产生多种多样的色光,这样一幅图像就分成了三个矩阵,相当于每个像素点有三个通道,分别对应三个矩阵中的数字,其中每个矩阵代表图像的一个channel,如图所示:(图像引用于【2】)
2.卷积层
上文我们已经介绍了卷积的目的和原理,接下来我们就要介绍卷积的过程,卷积的输入是上一节提到的图像矩阵,输出是一个特征矩阵(FM),卷积核同样是一个矩阵,特征矩阵是由图像矩阵和卷积核做线性运算得到的,卷积核最初我们自己初始化的,那它的大小应该为多大呢?比图像矩阵大明显不对,和图像矩阵一样大和全连接的操作一样,这样就相当于把整张图片当作一个特征去学习,但一张图象并不是所有的区域的特征都有助于我们进行分类,同时这样会需要训练大量的卷积核,时间耗费也是十分巨大的,所以CNN中的卷积核的大小设置为小于输入图像的大小,这样的一个卷积核矩阵就是我们的滤波器filter,矩阵的大小就是感受视野(local receptive fields)。
如图中显示了一张图片的三个通道的7×7的矩阵,感受视野是3×3,图像矩阵取左上角中的3×3大小的区域和filter进行如下计算得到Output Volume:

由公式可以看出,三通道的图像矩阵得到的特征图矩阵的深度是1,决定它最终深度的是fileter的个数,图片中filter的个数为2,所以的到特征图矩阵为3×3×2,如果我们在CNN的第一个卷积层定义训练12个滤波器,那就这一层的输出便是3X3X12.这里filter为什么是很多个呢?不同的filter可能有不同的作用,比如一个权值组合可能用来提取边缘(edge)信息,另一个可能是用来提取一个特定颜色,下一个就可能就是对不需要的噪点进行模糊化。当然filter作用的区域是在不停的移动的,它会对图像矩阵的每一个区域都进行一次特征提取才能得到我们的特征图,移动的步长被称为stride,如上图到下图的移动步长就是2。
从上面两幅图片我们还能看出在原始的图像矩阵周围有一圈0,这是怎么回事呢?其实这本来不是图片的原始信息,是我们认为加上去的,目的有两点:一点是因为平衡边缘区域和中心区域的特征提取偏好(自己理解一下),第二种是为了在大步长的情况下保持图像矩阵原有的大小,这种方法被称为填充边界(padding),这里用到的是零填充(zero padding)。
卷积的输入和输出矩阵大小可以由下面公式得到,推导很简单:

至此,卷积的过程和涉及到了几个概念filter、stride和padding已经介绍完了,我也简单说一说卷积在这里涉及到了三种思想:
(1).局部感知:局部感知简单来说就是上文提到的filter大小为什么比图像大小小的时候效果更高?一般来说图像局部像素关系紧密,较远像素相关性弱,因此只需要局部感知,在更高层将局部的信息综合起来就得到了全局的信息,这也是省时间的第一步。
(2).共享权重:就是我们整幅图像的所有区域用同一个filter去提取特征(图像上面不断滑动窗口去做线性运算),通俗来讲,就是这个滤波器能在这里认识狗的爪子,在其他区域的爪子它也应该能认识,这也是省时间的第二步。
(3).多卷积核:上文说到了,你要学习不同的特征,或者说你要过滤不同的信息就去训练不一样的filter。
3.激活层(activation)
激活层在卷积层之后,是对特征图进行一次非线性运算,为什么要这么做呢?个人理解可以类比于SVM中的kernel function,因为卷积本身是一种线性运算,要对通过线性运算的到的特征数据在低纬度下进行分类在有些情况下是比较麻烦的,但映射到高纬度就不一样了,比如下图在二维空间中不能很容易的进行分类,但是在三维空间中就很容易进行分类了。(图引用于【3】)
所以在卷积层之后加激活层的意义就很明显了,那一般的激活函数是什么呢?目前主流的激活函数是Relu,当然还有很多其他的激活函数,我这里不一一介绍,提供一个参考网站【4】。
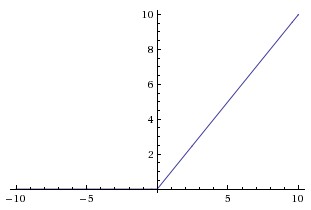
由Relu函数的图像可以看到,特征值小于零就是未激活状态,大于零就是激活状态,相比于之前用的sigmod函数有两个好处,第一时解决了由于网络层数加深时导数过小产生的梯度消失问题,第二是更多的神经元被抑制之后矩阵稀疏性更强,更容易进行分类。
4.池化层(pouling )
当我们得到的特征图太大,我们需要减少训练参数的数量,同时防止过拟合的发生,在卷积层之间周期性地引进池化层,这样在后续的卷积层中需要的参数量就会降低,池化在每一个图像通道的矩阵上独自完成,因此图像的纵深保持不变,池化层的最常见形式是最大池化和平均池化,同时池化层也是有池化区域尺寸(filter)和步长(stride)的,如下图是一个最大池化的过程:

5.全连接层
全连接层主要起特征加强(卷积就是弱化的全连接)和分类的作用,因为之前的卷积和池化操作说到底就是在提取特征和压缩特征,这样十分容易造成特征丢失,减少特征信息的丢失,使用全连接进一步加强的特征。同时的CNN都是End-to-End的模型,所以最后需要通过将全连接层送入softmax来进行分类,给出分类结果。
6.输出层
输出层主要准备做最后目标结果的输出。
总结:以上就介绍了CNN的基础网络结构,当然真实训练模型不可能只有一层卷积和池化,是通过多层的特征提取加分类组成了完整的网络结构,如上文提到的AlexNet有5个卷积层和3个全连接层。
写文章是为了加深对自己学过知识的记忆,后续还会有CNN的训练过程和代码解析,以及用于物体检测的衍生算法。水平有限,如果有问题,欢迎前辈指出。
【1】https://blog.csdn.net/lg1259156776/article/details/52551158
【2】https://www.zhihu.com/people/YJango/activities
【3】https://mp.csdn.net/postedit/80420107
【4】http://www.cnblogs.com/rgvb178/p/6055213.html