吴恩达机器学习笔记(1)——使用梯度下降做单、多变量的线性回归
机器学习个人笔记,学习中水平有限,内容如有缺漏还请多多包涵
序言
这里主要是吴恩达机器学习课程第二章(简单线性回归)、第五章(多变量线性回归)的代码实现,实际上课程还讲了正规方程(第五章)、多项式回归(第五章),但这里尚未实现。
单变量线性回归的python代码实现
import numpy as np
import matplotlib.pyplot as plt
def h(x,pram):#假设函数,这里等价于y=ax+b
#x:自变量
#pram:方程参数
return x*pram[1]+pram[0]
def gradientDescent(a,itertimes,datax,datay):#单变量梯度下降的线性回归
#a:学习率
#itertimes:迭代次数
#datax:数据集中的自变量部分
#datay:数据集中的结果部分
m=len(datax)#训练集长度m
pram=np.zeros(2)#参数,初始化为0
temppram=np.zeros(2)#临时存储本次迭代的参数
for i in range(0,itertimes):#迭代过程,执行itertimes次
temppram[0]=pram[0]-a*np.sum(h(datax,pram)-datay)/m
temppram[1]=pram[1]-a*np.sum((h(datax,pram)-datay)*datax)/m
if i%10==0:#每10代输出参数及误差的情况
print("迭代",i)
print( "参数:",pram)
print("平方根误差:",np.sqrt(np.sum((h(datax,pram)-datay)**2)))
pram=temppram
return pram
x=np.random.rand(10,1)
y=x*5+4+np.random.rand(10,1)#生成数据集
plt.figure()
plt.scatter(x, y)#绘制数据集的散点图
d=gradientDescent(1, 100, x, y)#执行梯度下降算法,返回预测参数
plt.plot(x, h(x,d),color='red')#绘制预测值的散点图
plt.show()
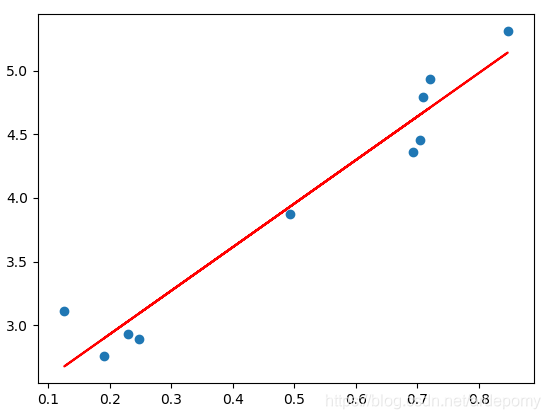
可视化的单变量梯度下降(数据集:y=3x+2+random(0~1),取10个点)
多变量线性回归的python代码实现
多变量的函数图像无法直观显示,因此不使用matlibplot
import numpy as np
def h(x,pram):#假设函数,这里等价于y=P*X+b ,其中P代表参数向量,X代表自变量向量
pramt=np.array(pram[1:])
return np.matmul(x,pramt.reshape(len(pram)-1,1))+pram[0]
def gradientDescent(a,itertimes,datax,datay):#单变量梯度下降的线性回归
#a:学习率
#itertimes:迭代次数
#datax:数据集中的自变量部分
#datay:数据集中的结果部分
m=datax.shape[0]#训练集长度
pram=np.zeros(datax.shape[1]+1)#参数,初始化为0
temppram=np.zeros(datax.shape[1]+1)#临时存储本次迭代的参数
for i in range(0,itertimes):#迭代过程,执行itertimes次
temppram[0]=pram[0]-a*np.sum(h(datax,pram)-datay)/m#对参数theta0进行迭代
for j in range(1,datax.shape[1]+1):#对剩余参数进行迭代
temppram[j]=pram[j]-a*np.sum((h(datax,pram)-datay).reshape(1,m)*datax[...,j-1])/m
if i%10==0:#每10代输出一次误差
print("迭代",i)
print( "参数:",pram)
print("平方根误差:",np.sqrt(np.sum((h(datax,pram)-datay)**2)))#没十代
pram=temppram
pass
return pram
x=np.random.rand(10,4)
pram=np.array([1,2,3,4,5])#参数
y=np.matmul(x,pram[1:].reshape(len(pram)-1,1))+pram[0]+np.random.rand(10,1)#生成数据集
gradientDescent(1, 500, x, y)#执行梯度下降算法,返回预测参数
这里的数据集是y=2*x1+3*x2+4*x3+5*x4+1+random(0~1),取十个点
损失函数的值:
实现过程中的一些坑
1.迭代过程中参数更新计算h(x)必须使用上次迭代的参数pram
temppram[1]=pram[1]-a*np.sum((h(datax,pram)-datay)*datax)/m
2.numpy中数组的X*Y得到的结果和np.matmul(X,Y)的结果是不同的
X*Y中X,Y的前后顺序不影响结果
x=np.array([[1,2,3],[2,3,4],[3,4,5]])
y=np.array([[1,2,3]])
pram=np.array([2,3,4])
print(y*pram)
print(y.T*pram)
print(x*pram)
print(x*pram.T)
print(pram*x)
=======================结果
[[ 2 6 12]]
[[ 2 3 4]
[ 4 6 8]
[ 6 9 12]]
[[ 2 6 12]
[ 4 9 16]
[ 6 12 20]]
[[ 2 6 12]
[ 4 9 16]
[ 6 12 20]]
[[ 2 6 12]
[ 4 9 16]
[ 6 12 20]]
np.matmul(X,Y)是真正的矩阵相乘,两个矩阵的shape必须符合矩阵相乘的要求,否则会报错
3.pram[0]代表假设函数Y=P*X+b中的常数b,datax中第1个变量(datax[0])对应的参数是pram[1],因此pram长度为datax中变量个数+1
公式部分
梯度下降做的是对损失函数求导,并沿着导数下降的方向移动,不仅仅被用于线性回归。
线性回归的损失函数定义为:
损失函数对xi求导,得到(此处省略部分微积分知识):
梯度下降for单变量线性回归的迭代公式:
注:xi代表数据集中自变量矩阵中第i行,即第i个训练数据
梯度下降for多变量线性回归的迭代公式:
注:xij代表数据集中自变量矩阵中第i行第j列,即第i个训练数据的第j个变量
学习视频:
其他笔记
- 机器学习入门
- 目录