请大家先思考:
- 1.什么是回归分析?
- 2.什么是线性回归?
- 3.线性回归可以用来解决什么问题?
1. 首先我们先了解下什么是回归分析
客观现象之间总是普遍联系与相互依存,反映这些联系的数量关系可分为两类,一类是确定性关系,另一类是不确定关系。
对于确定性关系,可用函数来描述它们,例如出租车费用与行驶里程之间的关系。此情形下,当行驶里程的值确定了,相应的出租车费用也就确定了。
对于不确定性关系,若一个变量或几个变量的值确定了,相应的另一个变量不能完全确定,而是在一定范围内变化,无法用准确的函数来描述。例如,人的身高与体重之间的关系。
对于不确定性关系的变量,当我们认识了它们内部的关联关系和变化规律后,不确定性关系有可能转化成确定性关系。
回归分析便是研究不确定性关系的一种常用的统计方法。回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
回归分析是建模和分析数据的重要工具。在这里,我们使用曲线/线来拟合这些数据点,在这种方式下,从曲线或线到数据点的距离差异最小。
2. 回归分析的用处
上面我们介绍了回归分析,它可以估计两个或者多个变量之间的关系。下面我们举一个简单的例子来进一步理解它:
比如说,在当前的经济条件下,你要估计一家公司的销售额增长情况。现在,你有公司最新的数据,这些数据显示出销售额增长大约是经济增长的2.5倍。那么使用回归分析,我们就可以根据当前和过去的信息来预测未来公司的销售情况。
使用回归分析的好处良多。具体如下:
1. 它表明自变量和因变量之间的显著关系;
2. 它表明多个自变量对一个因变量的影响强度。
回归分析也允许我们去比较那些衡量不同尺度的变量之间的相互影响,如价格变动与促销活动数量之间联系。这些有利于帮助市场研究人员,数据分析人员以及数据科学家排除并估计出一组最佳的变量,用来构建预测模型。
3. Linear Regression 线性回归
线性回归通常用于根据连续变量估计实际数值(房价、呼叫次数、总销售额等)。我们通过拟合最佳直线来建立自变量和因变量的关系。这条最佳直线叫做回归线,并且用 Y= a *X + b 这条线性等式来表示(即一元线性回归),此外还有多元线性回归。

假设特征和结果满足线性关系,即满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就是要预测的目标值。这一计算公式称为回归方程,得到这个方程的过程就称为回归。
线性回归就是假设这个方式是一个线性方程,即假设这个方程是一个多元一次方程。
先看一个例子
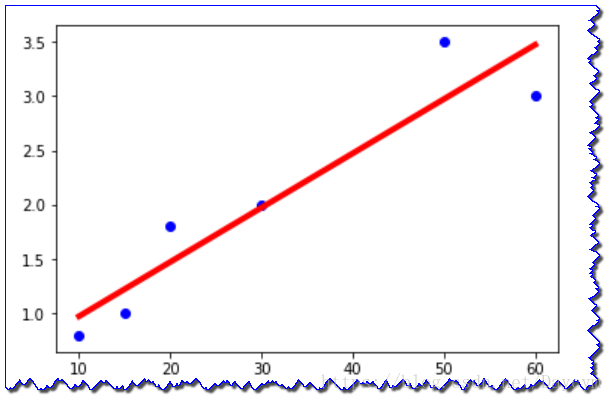
假设我们有一个房屋租赁交易的数据集。已知房屋面积和租赁价格,如下表:
| 房屋面积(m^2) | 租赁价格(1000¥) |
|---|---|
| 10 | 0.8 |
| 15 | 1 |
| 20 | 1.8 |
| 30 | 2 |
| 50 | 3.5 |
| 60 | 3 |
| … | … |
假如我们想租赁一个房屋,我们希望通过以上表中的数据估算个房子的价格。这个问题就是典型的一元线性回归问题。
- y:因变量
- a:斜率
- x:自变量
- b:截距
进一步,我们加入房间数量的信息,即满足了多元线性回归,如下表:
| 房屋面积(m^2) | 房间数量 | 租赁价格(1000¥) |
|---|---|---|
| 10 | 1 | 0.8 |
| 15 | 1 | 1.8 |
| 20 | 1 | 2.2 |
| 30 | 2 | 2.5 |
| 50 | 3 | 5.5 |
| 60 | 2 | 5.2 |
| … | … | … |
由以上的例子:假设房子的房屋面积和卧室数量为自变量x,用x1表示房屋面积,x2表示房间数量;房屋的租赁价格为因变量y,我们用h(x)来表示y。假设房屋面积、卧室数量与房屋的交易价格是线性关系。
他们满足公式:
上述公式中的θ为参数,也称为权重,可以理解为x1和x2对h(x)的影响度。对这个公式稍作变化就是
公式中θ和x是向量,n是样本数(最终要求是计算出θ的值,并选择最优的θ值构成算法公式)。
假如我们依据这个公式来预测h(x),公式中的x是我们已知的,然而θ的取值却不知道,只要我们把θ的取值求解出来,我们就可以依据这个公式来做预测了。
那么如何依据训练数据求解θ的最优取值呢?这就牵扯到另外一个概念:损失函数(Loss Function)。
线性回归的损失函数(Loss Function)
我们要做的是依据我们的训练集,选取最优的θ,在我们的训练集中让h(x)尽可能接近真实的值。
h(x)和真实的值之间的差距,我们定义了一个函数来描述这个差距,这个函数称为损失函数,表达式如下:
这里的这个损失函数就是著名的最小二乘损失函数,这里还涉及一个概念叫最小二乘法,这里不再展开了。
我们要选择最优的θ,使得h(x)最近进真实值。这个问题就转化为求解最优的θ,使损失函数J(θ)取最小值。
损失函数如何得到?
其中 (1<=i<=n)为误差, 表示第i个样本,每个样本有n个属性。
实际问题中,很多随机现象可以看做众多因素的独立影响的综合反应,往往服从正态分布。
似然函数
对数似然函数
定义: 为损失函数。
那么如何解决转化后的问题,求解最优的θ,使损失函数J(θ)取最小值。涉及到:梯度下降,将会在以后博客中解决。
要点:
- 自变量与因变量之间必须有线性关系
- 多元回归存在多重共线性,自相关性和异方差性。
- 线性回归对异常值非常敏感。它会严重影响回归线,最终影响预测值。
- 多重共线性会增加系数估计值的方差,使得在模型轻微变化下,估计非常敏感。结果就是系数估计值不稳定
- 在多个自变量的情况下,我们可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量。
总结
线性回归是回归问题中的一种,线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。使用最小二乘法构建损失函数,用梯度下降来求解损失函数最小时的θ值。
代码
import pandas as pd
from io import StringIO
from sklearn import linear_model
import matplotlib.pyplot as plt
# 房屋面积与价格历史数据(csv文件)
csv_data = 'square_feet,price\n10,0.8\n15,1\n20,1.8\n30,2\n50,3.5\n60,3\n'
# 读入dataframe
df = pd.read_csv(StringIO(csv_data))
print(df)
# 建立线性回归模型
regr = linear_model.LinearRegression()
# 拟合
regr.fit(df['square_feet'].reshape(-1, 1), df['price']) # 注意此处.reshape(-1, 1),因为X是一维的!
# 不难得到直线的斜率、截距
a, b = regr.coef_, regr.intercept_
# 给出待预测面积
area = 55
# 方式1:根据直线方程计算的价格
print(a * area + b)
# 方式2:根据predict方法预测的价格
print(regr.predict(area))
# 画图
# 1.真实的点
plt.scatter(df['square_feet'], df['price'], color='blue')
# 2.拟合的直线
plt.plot(df['square_feet'], regr.predict(df['square_feet'].reshape(-1,1)), color='red', linewidth=4)
plt.show()