=======================================================================
Machine Learning notebook
Python机器学习基础教程(introduction to Machine Learning with Python)
=======================================================================
监督学习模型中的核支持向量机模型(简称SVM)
SVM是可以推广到更复杂模型的扩展,这些模型无法被输入空间的超平面定义。
支持向量机可以同时用于分类和回归,分类在SVC中实现,回归在SVR中实现。
1、线性模型与非线性特征
线性模型在低维空间中可能非常受限,因为线和平面的灵活性有限。有一种方法可以让线性模型更加灵活,就是添加更多的特征——举个例子,添加输入特征的交互项或多项式。
用于分类的线性模型只能用一条直线来划分数据点,对这个数据集无法给出较好的结果。

现在对输入特征进行扩展,建立3D视图。
在数据的新表示中,现在可以用线性模型(三维空间中的平面)将这两个类别分开。
如果将线性SVM模型看做原始特征的函数,那么它实际上已经不是线性的了。它不是一条直线,而是一个椭圆。
2、核技巧
这里需要记住的是,向数据表示中添加非线性特征,可以让线性模型变得更强大。但是,通常来说我们并不知道要添加哪些特征,而且添加许多特征(比如100维特征空间所有可能的交互项)的计算开销可能会很大。幸运的是,有一种巧妙的数学技巧,让我们可以在更高维空间中学习分类器,而不用实际计算可能非常大的新的数据表示。这种技巧叫做核技巧(kernel trick),它的原理是直接计算扩展特征表示中数据点之间的距离(更准确地说是内积),而不用实际对扩展进行计算。
对于支持向量机,将数据映射到更高维空间中有两种常用的方法:
一种是多项式核,在一定阶数内计算原始特征所有可能的多项式(比如feature1 ** 2 * feature ** 5)。
另一种是径向基函数(radial basis function,RBF)核,也叫高斯核。高斯核有点难以解释,因为它对应无限维的特征空间。一种对高斯核的解释是它考虑所有阶数的所有可能的多项式,但阶数越高,特征的重要性越小(遵循指数映射的泰勒展开)。
3、理解SVM
在训练过程中,SVM学习每个训练数据点对于表示两个类别之间的决策边界的重要性。通常只有一部分训练数据点对于定义决策边界来说很重要:位于类别之间边界上的那些点。这些点叫做支持向量(support vector),支持向量机正是由此得名。
想要对新样本点进行预测,需要测量它与每个支持向量之间的距离。分类决策是基于它与支持向量之间的距离以及在训练过程中学到的支持向量重要性(保存在SVC的dul_coef_属性中)来做出的。
数据点之间的距离由高斯核给出:
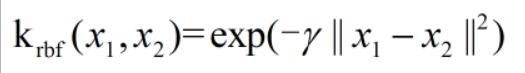
这里x1、x2是数据点,||x1-x2||表示欧式距离,γ(gamma)是控制高斯核宽度的参数。
4、SVM调参
gamma参数用于控制高斯核的宽度。它决定了点与点之间“靠近”是指多大的距离。C参数是正则化参数,与线性模型中用到的类似。它限制每个点的重要性(或者更确切的说,每个点的dual_coef_)。
gamma较小,说明高斯核的半径较大,许多点都被看做比较靠近。小的gamma值表示决策边界变化很慢,生成的是复杂度较低的模型,而大的gamma值则会生成更为复杂的模型。
与线性模型相同,C值很小,说明模型非常受限,每个数据点的影响范围都有限。
虽然SVM的表现通常都很好,但它对参数的设定和数据的缩放非常敏感。特别的,它要求所有特征有相似的变化范围。
若数据集的特征具有完全不同的数量级。这对其他模型来说(比如线性模型)可能是小问题,但对SVM却有极大影响。
5、为SVM预处理数据
解决这个问题的一种方法就是对每个特征进行缩放,使其大致都位于统一范围。核SVM常用的缩放方法就是将所有特征缩放的0和1之间。可以使用MinMaxScaler预处理方法做到这一点。
可以尝试增大C或gamma来拟合更为复杂的模型。
6、优点、缺点和参数
SVM允许决策边界很复杂,即使数据只有几个特征。它在低维数据和高维数据(即很少特征和很多特征)上的表现都很好,但对于样本个数的缩放表现不好。在有多达10000个样本的数据上运行SVM可能表现良好,但如果数据量达到100000甚至更大,在运行时间和内存使用方面可能面临挑战。
SVM的另一个缺点是,预处理数据和调参都需要非常小心。这也是为什么如今很多应用中用的都是基于树的模型,比如随机森林或梯度提升(需要很少的预处理,甚至不需要预处理)。此外,SVM模型很难检查,可能很难理解为什么会这么预测,而且也难以将模型向非专家解释。
不过SVM仍然是值得尝试的,特别是所有特征的测量单位相似(比如都是像素密度)而且范围也差不多时。
核SVM的重要参数是正则化参数、核的选择以及核相关的参数。