通常情况下,存在以下两种情况:
1、分类完全正确的超平面不一定是最好的;
2、样本数据不是线性可分的;
如图1所示,如果按照完全分对这个准则来划分时,L1为最优分割超平面,但是实际情况如果按照L2来进行划分,效果可能会更好,分类结果会更加鲁棒。
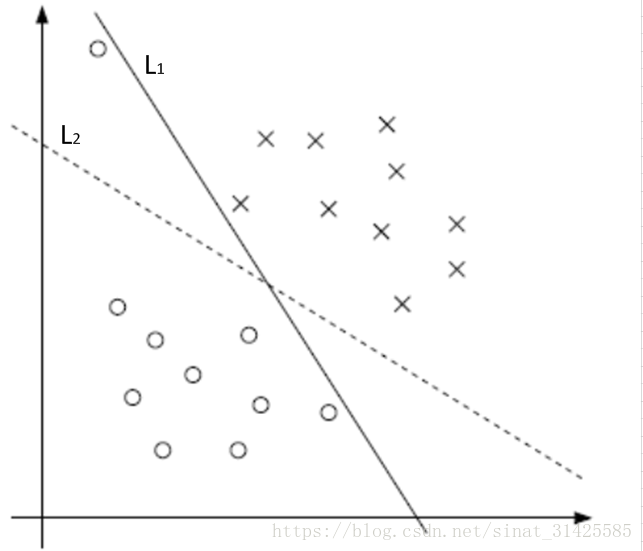
图1 样本分布示意图
通过引入松弛因子,放宽对于离群点的约束
,注意,如果
任意大,任意超平面都会符合条件,因此我们需要对
做一定限制,目标函数就变成了:
引入拉格朗日乘子有:
将L分别对求偏导有:
将三个条件回代到L有:
目标函数和约束条件为:
第二个约束条件是因为,即
,得
这里C需要预先设定参数,C越大,容许的就越小,对于离群点偏离群体的位置容忍度就越小,SVM对应排空区域(过渡带)就越小,分类器容易发生过拟合;C越小,容许的
就越大,对于离群点偏离群体的位置容忍度就越大,SVM对应排空区域(过渡带)就越大,C如果过小,分类器的性能就会较差。
直观来看,如图1所示。

图1 随着C增大,排空区域大小示意图
参考资料:
2016小象学院-机器学习升级版II(邹博)
支持向量机通俗导论(理解SVM的三层境界)
周志华. 机器学习 : = Machine learning[M]. 清华大学出版社, 2016.