关键点:多分支网络结构->各个分支间的权重共享->sale aware training
Abstract
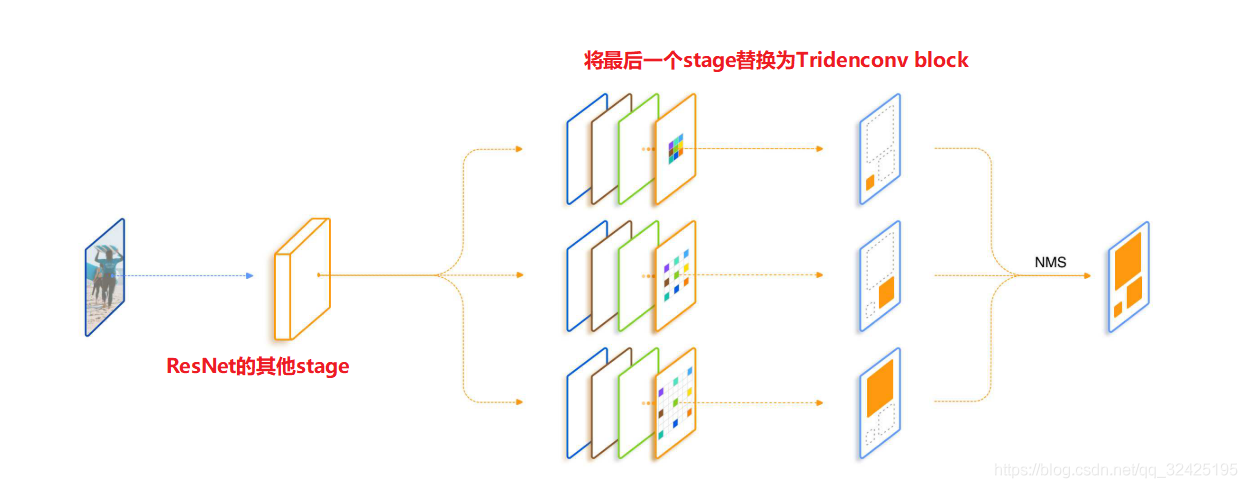
我们构造了一个并行的多分支结构,各个分支间共享参数,但是感受野不同。指定每个分支只采样对应的感受野进行训练。
1. Introduction
尺度问题的集中解决办法:
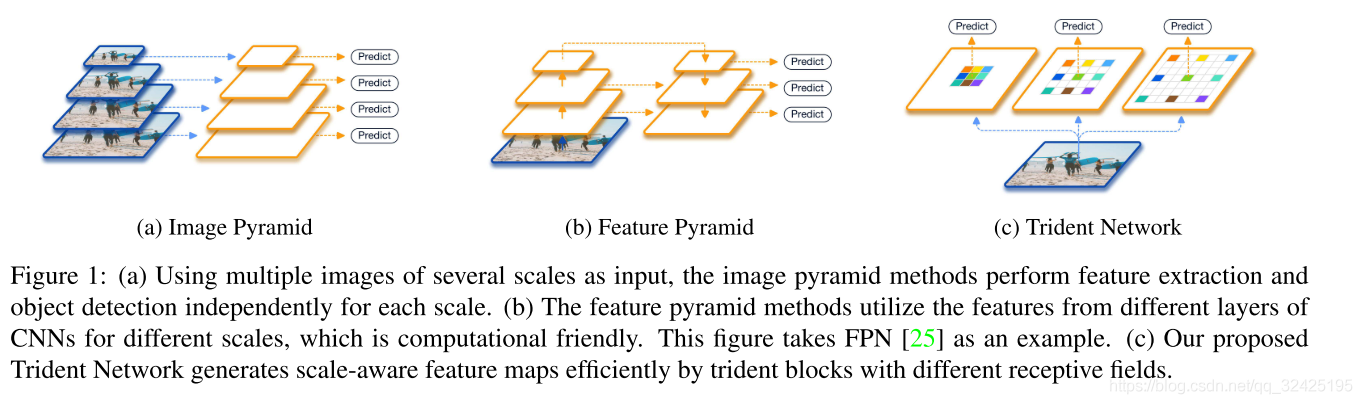 我们的方法:
我们的方法:
通过空洞卷积,不同barnch共享相同的网络结构和网络参数,但每个分支有不同的感受野。为了避免极端大小的图片送入分类回归器,我们从感受野角度,让每个分支检测某一范围的尺度的目标。
我们从感受野角度,探究尺度鲁邦性的方法。卷积神经网络不具有尺度不变性,强行增大训练数据让网络学习尺度会浪费很多capalicity,所以我们需要额外的措施增加尺度不变性。
2. Related Work
SNIP和SNIPER:由于测试时需要采用不同分辨率的图片测试后结果融合,所以推理时间较长。
我们的结构并不是获得多个尺度的特征,而是通过多个分支产生尺度相关的特征,从而对不同尺度目标的表达能力都较好
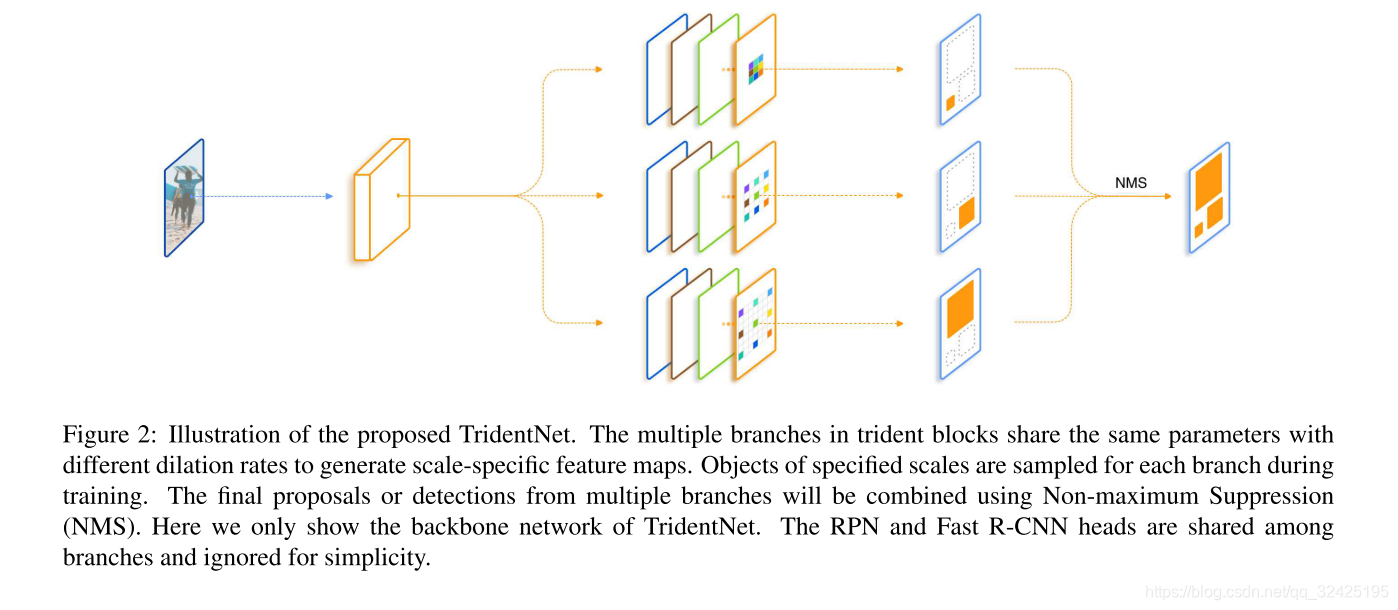
4. Trident Network
(1)模型结构
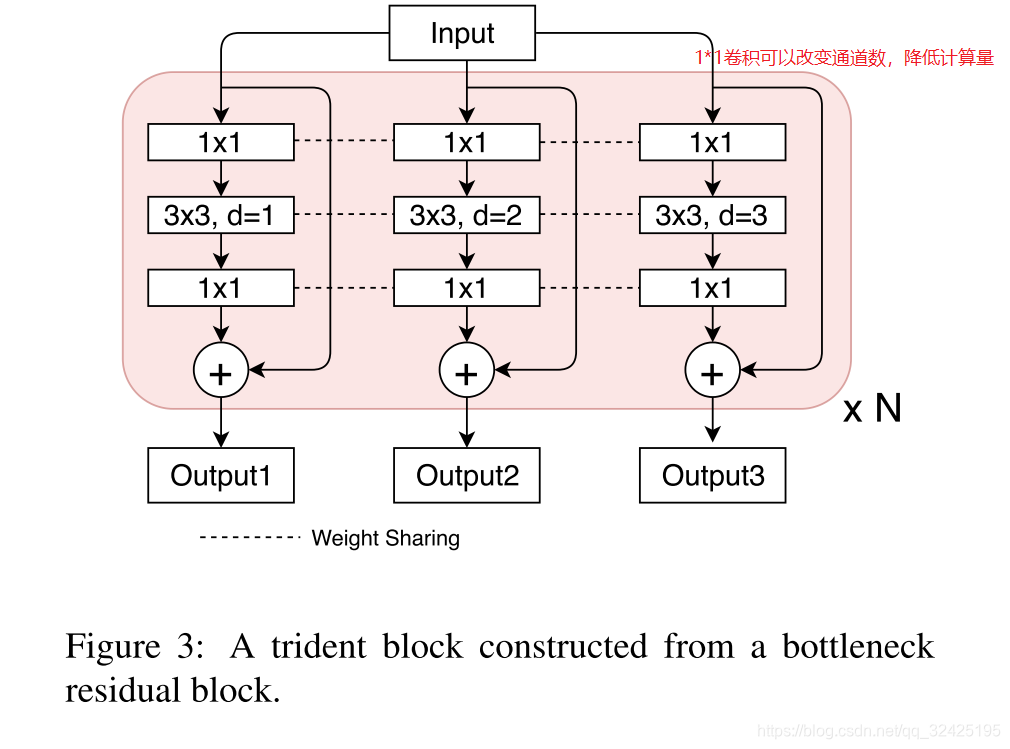
多个分支,各个分支间的权重共享;
4.2 Scale-aware training schedume 尺度感知的训练策略
训练时,每个分支有一个尺度范围[L,u],只选择落在该区域内的proposals来训练检测器
4.3. Inference and Approximation
推理过程:各个分支的检测结果做nms。
为了加速推理过程,我们构造了Fast Inference Approximation。使用3个分支训练,预测时只保留第二个分支。
5.实验结果
5.2 Ablation study
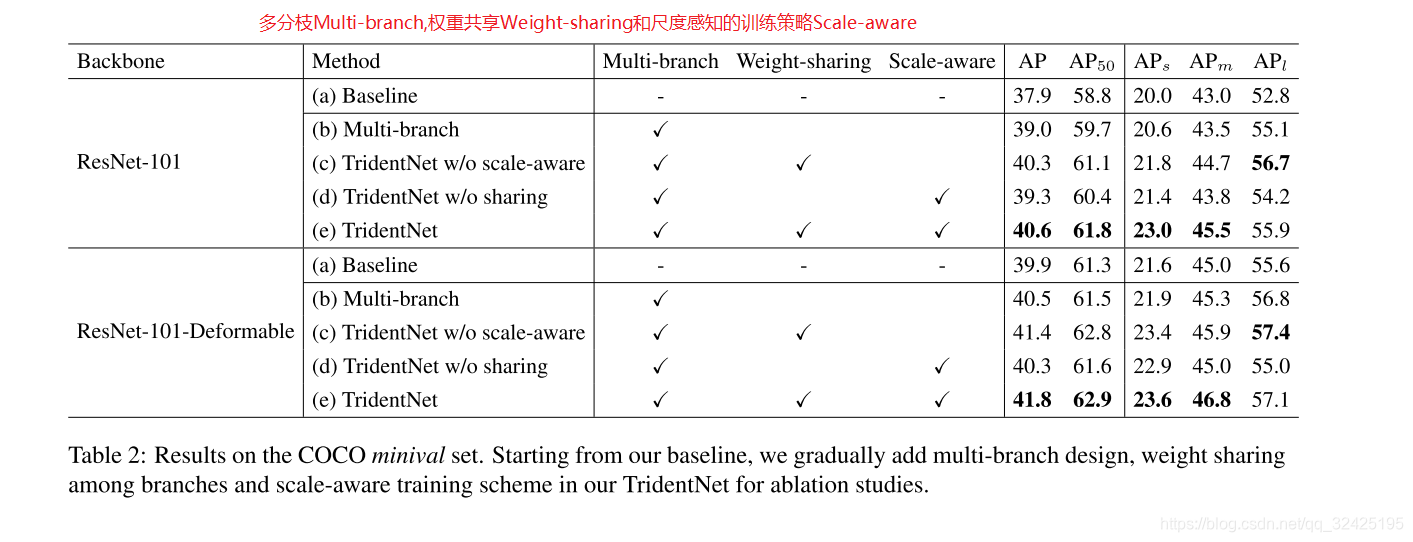
5.3 分支个数的选择
3个分支时结果最好,4个分支时效果反而下降(猜测原因:)
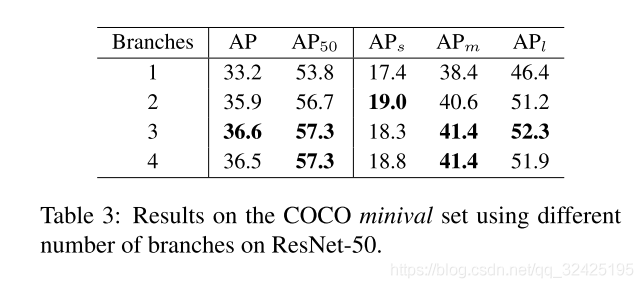
3个分支中每个分支的表现:
我们让各个分支单独做检测,并且不去掉超过该分支检测范围内的检测结果。可见,各个分支对自己对应尺度内的目标的检测结果最好。
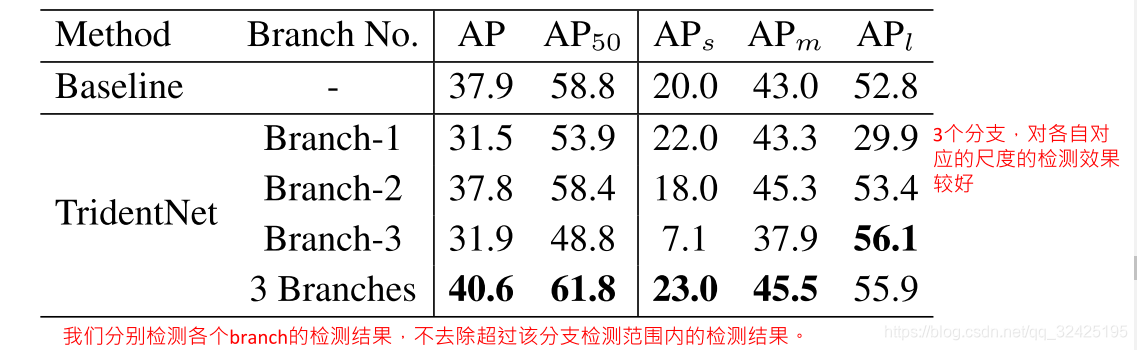
当只用第二个分支做推理时,如何设置训练时3个分支的目标检测的尺度范围:
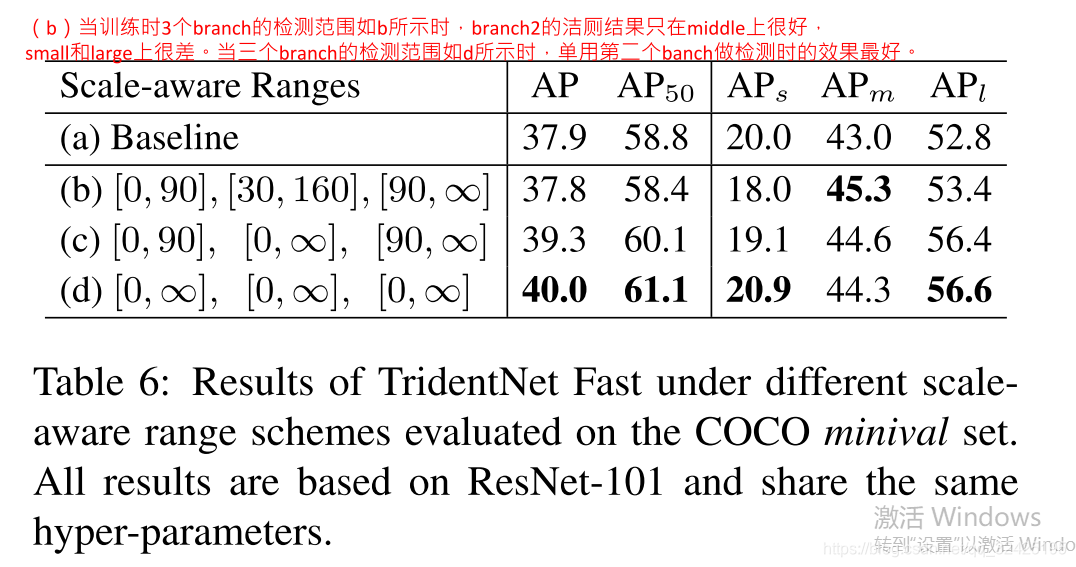
代码:
(1)tridentNet部分的代码:
https://github.com/facebookresearch/detectron2/tree/master/projects/TridentNet/
conv1,conv2,conv3的权重在3个branch是共享的。其中conv2的weights和bias只有一个,但是在卷积过程中使用不同dilations的卷积进行卷积操作
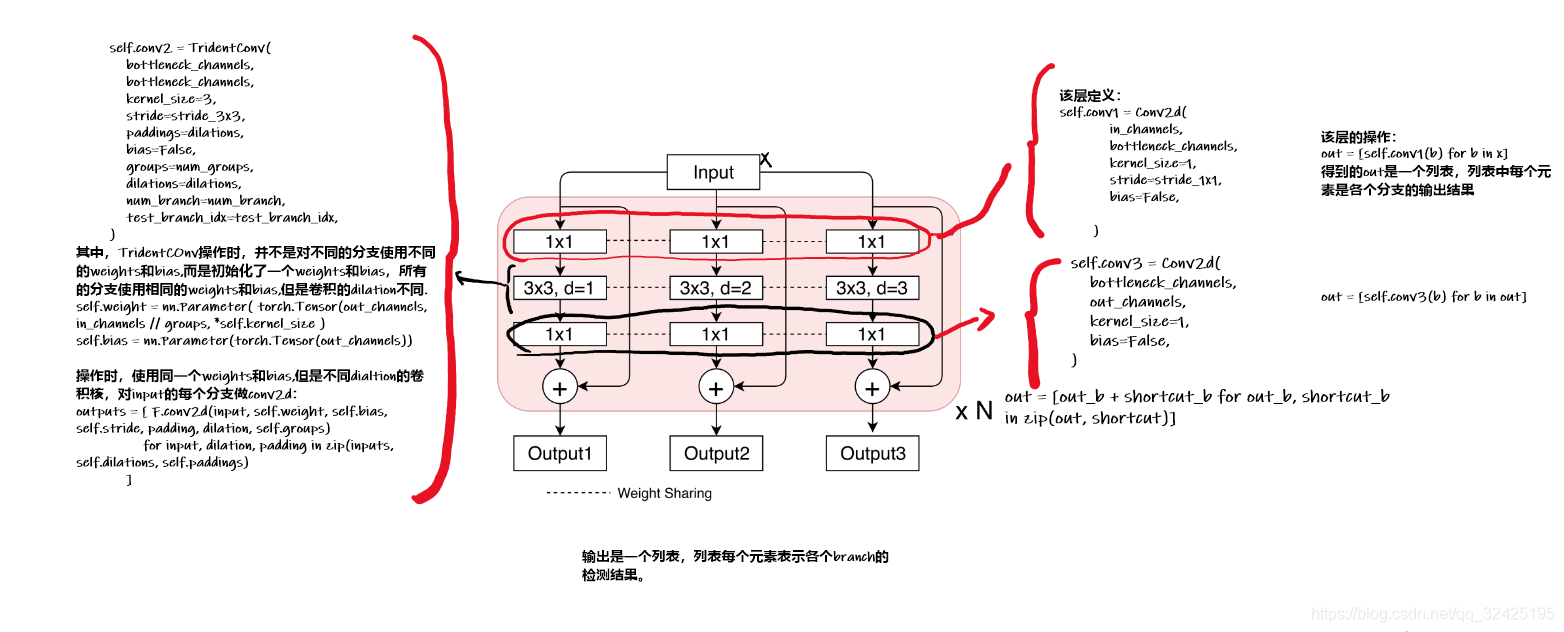
class TridentConv(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
paddings=0,
dilations=1,
groups=1,
num_branch=1,
test_branch_idx=-1,
bias=False,
norm=None,
activation=None,
):
super(TridentConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = _pair(kernel_size)
self.num_branch = num_branch
self.stride = _pair(stride)
self.groups = groups
self.with_bias = bias
if isinstance(paddings, int):
paddings = [paddings] * self.num_branch
if isinstance(dilations, int):
dilations = [dilations] * self.num_branch
self.paddings = [_pair(padding) for padding in paddings]
self.dilations = [_pair(dilation) for dilation in dilations]
self.test_branch_idx = test_branch_idx
self.norm = norm
self.activation = activation
assert len({self.num_branch, len(self.paddings), len(self.dilations)}) == 1
self.weight = nn.Parameter(
torch.Tensor(out_channels, in_channels // groups, *self.kernel_size)
)
if bias:
self.bias = nn.Parameter(torch.Tensor(out_channels))
else:
self.bias = None
def forward(self, inputs):
num_branch = self.num_branch if self.training or self.test_branch_idx == -1 else 1
assert len(inputs) == num_branch
if inputs[0].numel() == 0:
output_shape = [
(i + 2 * p - (di * (k - 1) + 1)) // s + 1
for i, p, di, k, s in zip(
inputs[0].shapTridentBottleneckBlocke[-2:], self.padding, self.dilation, self.kernel_size, self.stride
)
]
output_shape = [input[0].shape[0], self.weight.shape[0]] + output_shape
# return [_NewEmptyTensorOp.apply(input, output_shape) for input in inputs]
return inputs
if self.training or self.test_branch_idx == -1:
outputs = [
F.conv2d(input, self.weight, self.bias, self.stride, padding, dilation, self.groups)
for input, dilation, padding in zip(inputs, self.dilations, self.paddings)
]
else:
outputs = [
F.conv2d(
inputs[0],
self.weight,
self.bias,
self.stride,
self.paddings[self.test_branch_idx],
self.dilations[self.test_branch_idx],
self.groups,
)
]
if self.norm is not None:
outputs = [self.norm(x) for x in outputs]
if self.activation is not None:
outputs = [self.activation(x) for x in outputs]
return outputs
class TridentBottleneckBlock(nn.Module):
def __init__(
self,
in_channels,
out_channels,
bottleneck_channels,
stride=1,
num_groups=1,
norm="BN",
stride_in_1x1=False,
num_branch=3,
dilations=(1, 2, 3),
concat_output=False,
test_branch_idx=-1,
):
"""
Args:
num_branch (int): the number of branches in TridentNet.
dilations (tuple): the dilations of multiple branches in TridentNet.
concat_output (bool): if concatenate outputs of multiple branches in TridentNet.
Use 'True' for the last trident block.
"""
super().__init__()
assert num_branch == len(dilations)
self.num_branch = num_branch
self.concat_output = concat_output
self.test_branch_idx = test_branch_idx
if in_channels != out_channels:
self.shortcut = Conv2d(
in_channels,
out_channels,
kernel_size=1,
stride=stride,
bias=False,
)
else:
self.shortcut = None
stride_1x1, stride_3x3 = (stride, 1) if stride_in_1x1 else (1, stride)
self.conv1 = Conv2d(
in_channels,
bottleneck_channels,
kernel_size=1,
stride=stride_1x1,
bias=False,
)
self.conv2 = TridentConv(
bottleneck_channels,
bottleneck_channels,
kernel_size=3,
stride=stride_3x3,
paddings=dilations,
bias=False,
groups=num_groups,
dilations=dilations,
num_branch=num_branch,
test_branch_idx=test_branch_idx,
)
self.conv3 = Conv2d(
bottleneck_channels,
out_channels,
kernel_size=1,
bias=False,
)
def forward(self, x):
num_branch = self.num_branch if self.training or self.test_branch_idx == -1 else 1
if not isinstance(x, list):
x = [x] * num_branch #通过复制分成3个分支,每个分支都一样
out = [self.conv1(b) for b in x]
out = [F.relu_(b) for b in out]
out = self.conv2(out)
out = [F.relu_(b) for b in out]
out = [self.conv3(b) for b in out]
if self.shortcut is not None:
shortcut = [self.shortcut(b) for b in x]
else:
shortcut = x
out = [out_b + shortcut_b for out_b, shortcut_b in zip(out, shortcut)]
out = [F.relu_(b) for b in out]
if self.concat_output:
out = torch.cat(out)
return out
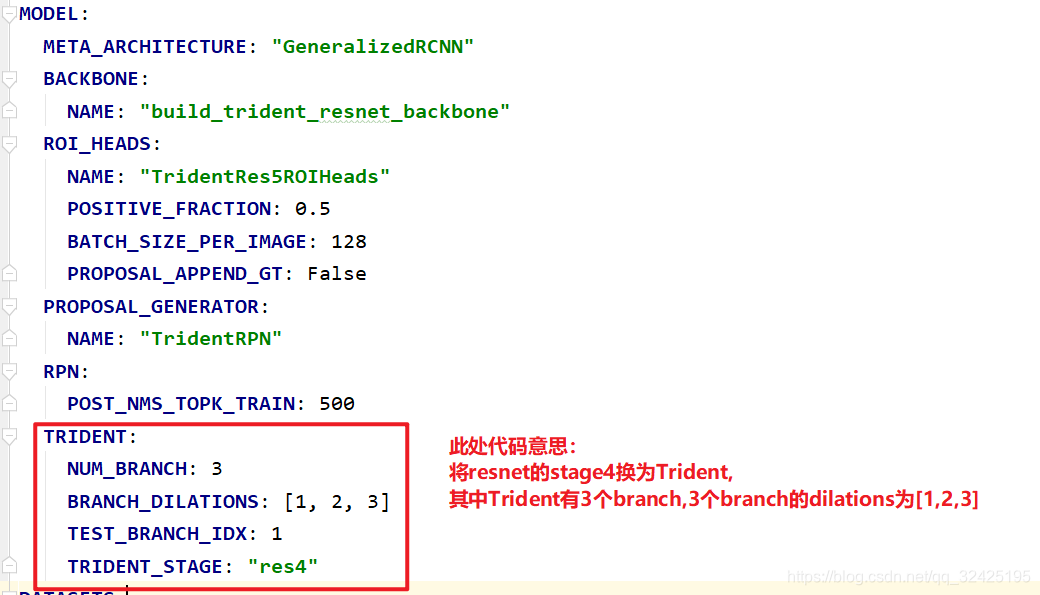
将TridenNet放入ResNet中:
代码:
代码:
对于resnet中的每个stage,如果指定 stage是tridentNetconv,则调用make_trident_stage,否则调用make_stage,构造正常的ResNet:
def build_trident_resnet_backbone(cfg, input_shape):
for idx, stage_idx in enumerate(range(2, max_stage_idx + 1)):#对于每个stage
#根据是否指定该stage为trident,嗲用不同的stage的构造函数
blocks = (
make_trident_stage(**stage_kargs)
if stage_idx == trident_stage_idx
else make_stage(**stage_kargs)
)trident嵌入到一阶段和二阶段的网络中:
对于tridenet的每个branch,分别做预测,然后将预测结果融合。类比FPN
