这篇论文是哈工大与科大讯飞联合实验室发表的。被2017ACL收录,之前的《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》这篇文章也是,2016年发表,本篇就是在这篇论文的基础上进行改进的。
1、Motivation
CAS Reader模型[1](Consensus Attention Sum Reader)


- 只考虑了query-document的注意力,然后通过(sum、average)汇总文档中每个单词的分布
- 引入document-query的注意力,并不是query中每个单词都会被用到,其重要性是不一样的
提出Double-Check
- 不是选择一个最好的答案,而是挑出一个候选集,然后再从中寻找最合适的答案
因为阅读理解根据数据集不同,所使用的模型也会略有差别,下面就先介绍一下该论文采用的数据集。
2、Dataset
任务:填空式的阅读理解
美国有线新闻网(CNN)和每日邮报网(Daily Mail)中收集了大约一百万条新闻数据作为机器阅读理解语料库。
- 将一篇文章的主体作为document,新闻的摘要作为query,从query中选择一个entity替换为placeholder,answer即entity(D,Q,A)
- 对文章进行NER,并将实体词替换成匿名词,以防直接通过query获得答案

Children’s Book Test
- 从每一个儿童故事中提取20个连续的句子作为文档(document),第21个句子作为问题(query),并从中剔除一个实体类单词作为答案(answer)
- 因为介词和动词在标准的LSTM语言模型上效果就已经不错了,所以只考虑命名实体和普通名词
- 给定10个候选答案,从中选择一个

3、Model

介绍一个模型,我们从模型的输入输出、参数和运算关系进行介绍,然后我们在介绍训练过程。

-
输入:
文档D和查询Q -
输出:
文档中的每一个词,在query和document条件下对应的概率 -
运算关系:在ppt上画出来了,这里直接附图)


其中最重要的贡献就是AoA这一部分,考虑query和document之间的交互信息,从而获得打分S。
- 训练:
最大化正确答案的Log似然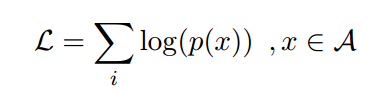
Double check使用N最佳重排序策略
- Global N-gram LM:这是评分句子的基本指标,旨在评估其流利程度
- Local N-gram LM:统计信息是从测试文档中获得的。
- 词类LM:在部分训练数据的文档进行训练,通过使用聚类方法获得该词类。
- 在验证集上自动优化——K-best MIRA algorithm[2]对上述特征计算权重,然后选择候选集中最好的一个
4、Experiments
-
参数设置
Embedding Layer:均匀分布[-0.05, +0.05]
L2-regularization:0.0001
Dropout:0.1
Optimization:Adam initial_lr = 0.001 -
Dimensions of embedding and hidden layer
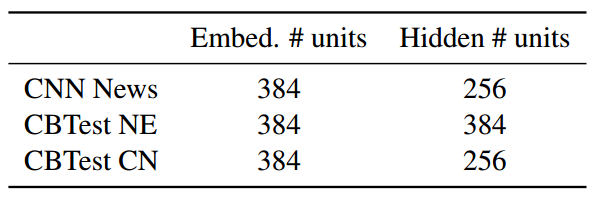
- 总体结果

- Re-ranking 的有效性

增加率:在NE任务上,可以看到Local提升可1.2% ,比CN任务上好;而对于CN任务,G&W分别提高了1.8%&1.4%。这里我的理解是,对于NE任务来说,它更加关注实体信息,而在整个训练集上训练的G&W相比较只在测试集上训练的Local LM捕获到的实体类型的信息显得略欠。对于常识名词来说,从全文获得信息可能更有用处。
5、Discussion
-
Pros
考虑query和document之间的交互信息
采用double-check方法模拟了人的阅读过程 -
Cons
没有涉及到推理,对于现实需要推理的阅读理解存在问题
可以将得到的s和embedding联合,得到query下文档的重新表达,再通过一个分类器得到答案
[1]Yiming Cui, Ting Liu, Zhipeng Chen, Shijin Wang, and Guoping Hu. 2016. Consensus attentionbased neural networks for chinese reading comprehension.
[2] Colin Cherry and George Foster. 2012. Batch tuning strategies for statistical machine translation.