1 Introduction
过去的MRC技术的特点:hand-crafted rules or features
缺点
- 不能泛化
- performance may degrade due to large-scale datasets of myriad types of articles ignore long-range dependencies , fail to extract contextual information
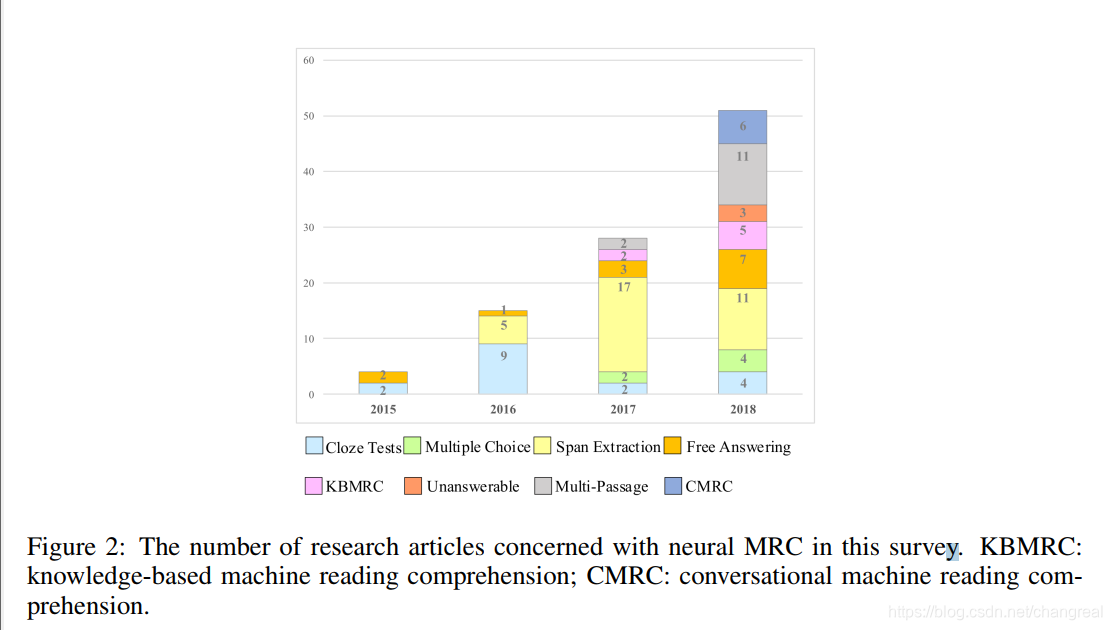
MRC研究的不同内容以及对应数量:
一个好的MRC的介绍论文应该:
- 给不同MRC任务具体的定义
- 深度比较它们
- 介绍新趋势和open issues
探索方法
- 谷歌学术,关键词:machine reading comprehension, machine comprehension, reading comprehension
- 顶会论文:ACL, EMNLP, NAACL, ICLR, AAAI, IJCAI and CoNLL, 时间2015–2018
- http://arxiv.org/ , latest pre-print articles
这篇论文关于MRC的大纲结构
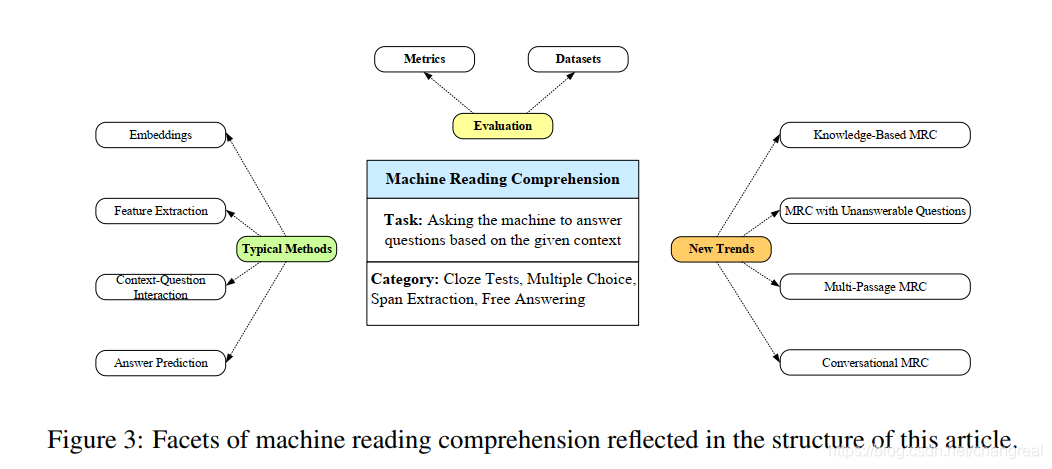
论文结构:
- MRC任务的四种分类
cloze tests, multiple choice, span extraction, and free answering.
comparing these tasks in different dimensions 【2】 - 展现neural MRC systems embeddings的通用结构
feature extraction,context-question interaction and answer prediction. 【3】 - 一些代表性的数据集、根据不同的任务而使用的评估指标【4】
- 一些新的趋势
比如knowledge-based MRC, MRC with unanswerable questions, multi-passage MRC and conversational MRC【5】 - 一些open issue、未来可能的研究方向【6】
2 Tasks
MRC的定义:
写者根据回答形式把MRC分为4种分类:cloze tests, multiple choice, span extraction and free answering.
2.1 Cloze Tests
- answer A is a word or entity in the given context C;
- question Q is generated by removing a word or entity from the given context C such that Q = C − A.

2.2 Multiple Choice

2.3 Span Extraction
完形填空和多选的缺点:
- words or entities不够回答,一些回答需要完整的句子
- 有些问题没有condidate answers

2.4 Free Answering
there are no limitations to its answer forms, and it is more suitable for real application scenarios.

2.5 Comparison of Different Tasks
we evaluated five dimensions: construction, understanding, flexibility, evaluation and application.
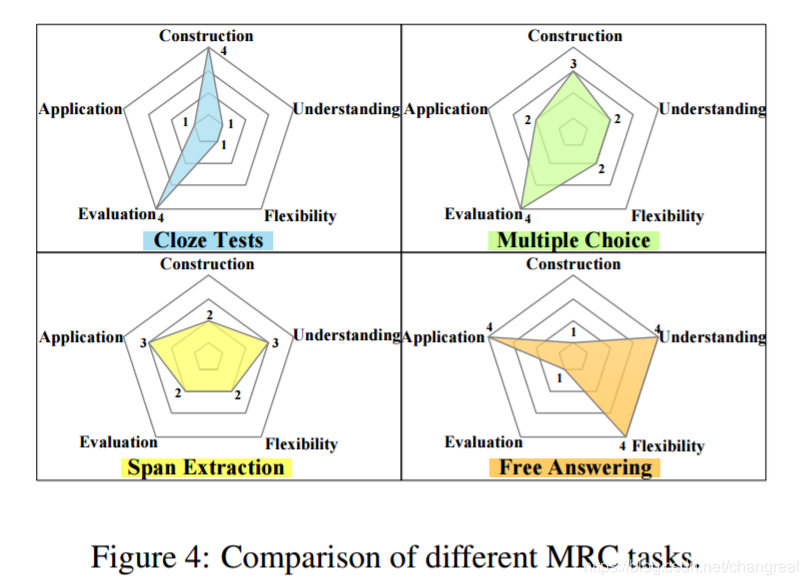
Because of the flexibility of the answer form, it is somewhat hard to build datasets, and how to effectively evaluate performance on these tasks remains a challenge.
3 Deep-Learning-Based Methods
3.1 General Architecture
一个典型的 neural MRC系统
包含4个核心modules: embeddings, feature extraction, context-question interaction and answer prediction.
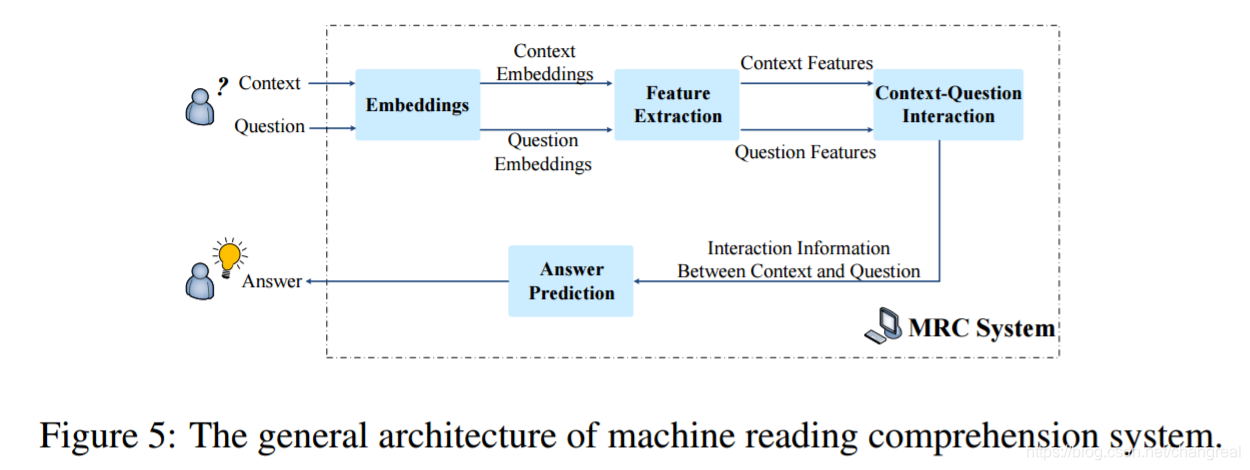
一些语言学特征:比如 part-ofspeech, name entity, and question category,结合词表示(one-hot or word2vec)来表达words中的semantic and syntactic信息。
3.2 Typical Deep-Learning Methods
典型MRC系统的组成以及涉及的深度学习方法:
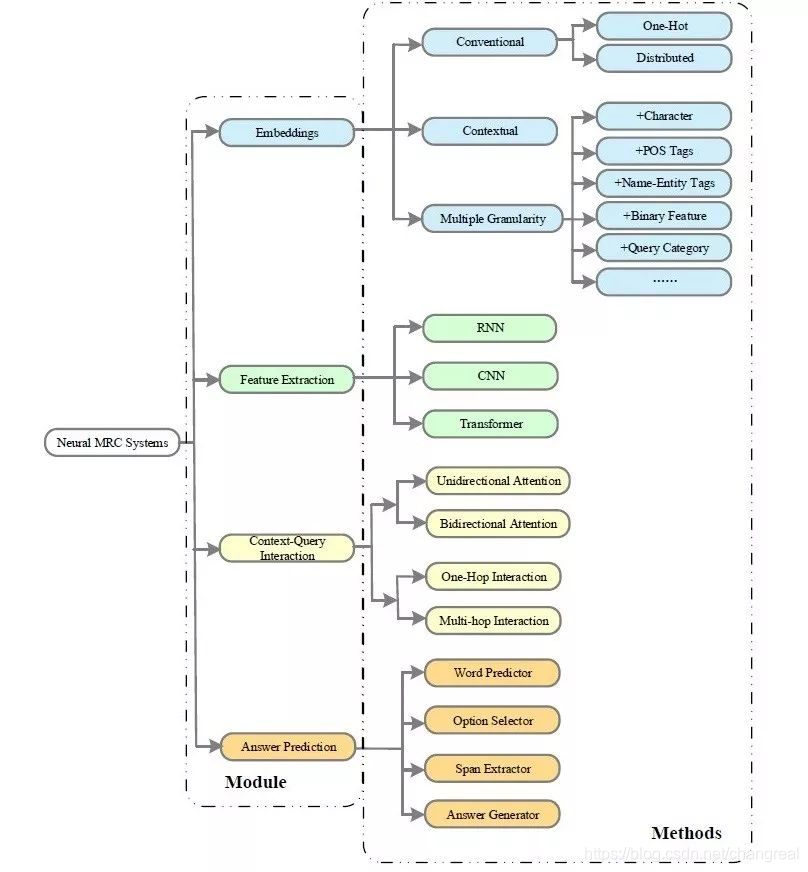
3.2.1 Embeddings
在现有MRC models中,word representation方法可以分为:conventional word representation和pre-trained contextualized representation两种。
为了encode足够的semantic and linguistic信息,multiple granularity (word-level/character-level, 词性,命名实体,词频,问题类别等)也添加进了MRC系统
- Conventional Word Representation 传统词表示
- Pre-trained Contextualized Word Representation 预训练上下文词表示
-
CoVE
CoVE是MT是seq2seq模型+LSTM的encoder
连接MT encoder的输出(encoder的输出被看作CoVE)和用GloVe预训练的word embeddings来表示上下文和question,然后feed them through the coattention and dynamic decoder implemented in a dynamic coattention network (DCN) -
ELMo
如:an improved version of bidirectional attention flow (Bi-DAF) + ELMo
它很容易整合进现有模型中,但是受限于LSTM特征抽取能力不足 -
Generative pre-training (GPT)
a semi-supervised approach combining unsupervised pre-training and supervised fine-tuning.
the transformer architecture used in GPT and GPT-2 is unidirectional (left-to-right),which cannot incorporate context from both directions.
In terms of MRC problems such as multiple choice, concatenate the context and the question with each possible answer and process such sequences with transformer networks. Finally, they produce an output distribution over possible answers to predict correct answers. -
BERT
In particular, for MRC tasks, BERT is so competitive that using it with a simple answer prediction approach shows promise.
缺点:BERT’s pre-training process is time and resource-consuming which makes it nearly impossible to pre-train without abundant computational resources.
- Multiple Granularity 多重粒度
由word2vec 和gloVe预训练的word-level embeddings不能encode足够的syntactic和linguistic信息(比如与part-of-speech, affixes, grammar),为了整合fine-grained(细粒度)的信息到词表示中,用了一下方法来encode the context and the question在不同level上的粒度:
-
Character Embeddings
Seo et al. [75] add character-level embeddings to their Bi-DAF model for the MRC task.
The concatenation of word-level and character-level embeddings are then fed to the next module as input.
(1). CNN的方式:The concatenation of word-level and character-level embeddings are then fed to the next module as input.
(2). character embeddings can be encoded with bidirectional LSTMs. the outputs of the last hidden state are considered to be its character-level representation.
(3). word-level and character-level embeddings can be combined dynamically with a fine-grained gating mechanism rather than simple concatenation to mitigate the imbalance between frequent and infrequent words -
Part-of-Speech Tags
Labeling POS tags in NLP tasks可以说明单词使用的复杂特征并有助于消歧。To translate POS tags into fixed length vectors, they are regarded as variables, randomly initialized in the beginning and updated while training. -
Name-Entity Tags:embedding name-entity tags of context words can improve the accuracy of answer prediction. 方法和POS tags类似。
-
Binary Feature of Exact Match (EM)
which measures whether a context word is in the question. some researchers used it in the Embedding module to enrich word representations. -
Query-Category
The types of questions (what, where, who, when, why, how) can usually provide clues to search for the answer. The query-category embeddings are often added to the query word embeddings.
The embeddings introduced above can be combined freely in the embedding module. 比如word representations里含有:character-level, word-level, POS tags, name-entity tags, EM, query-category embeddings.
3.2.2 Feature Extraction
特征抽取经常放在embeddins layer后面来分别抽取context 和question的特征。它更关注挖sentence-level的contextual info.
-
RNN
许多研究者使用双向rnn来捕获MRC中context和question的embedddings.
在questions的形式中,双向RNN可以分类为word-level和sentence-level,而sentence-level可以编码问题的整个相关句子。
MRC的context通常是long sequence,so use word-level feature extraction to encode sequential information of context.
RNN的处理是费时并且不可平行。 -
CNN
When applied to NLP tasks, 一维CNNs show their superiority in mining local contextual information with sliding windows.
CNN有点:可以平行,并且不收词典大小的限制来抽取局部信息(不需要表示词典中的每个n-gram),但是CNN不能处理long sequence. -
Transformer
能对齐、平行、运行需要更少时间、更关注global dependencies.
比如QANet是使用transformer的代表性的MRC模型。
To accelerate the training process, some researchers substitute RNNs with CNNs or the transformer.
3.2.3 Context-Question Interaction
提取context和question的correlation,模型从而找到evidence来预测answer。
根据模型如何extract correlations,现有工作可以分为one-hop和multi-hop interaction.
重要角色:attention机制。
在MRC上,attention机制可以分为单向和双向attention。
-
Unidirectional Attention
单一attention flow总是从query到context,根据question关注context中最重要和相关的部分。
**相关模型:【Attentive Reader】**这个模型可以了解一下,早期MRC模型用单向attention。
但是单一attention不能关注到question words中同样关键的用于answer prediction的词,因此单一attention对于提取context和query之间的mutual info不够给力。 -
Bidirectional Attention
不仅计算query-to-context attention的信息,也计算context-to-query attention. 这个方法受益于context和query的interaction,能提供补充信息。
主要是通过计算matching scores计算pair-wise matching matrix M,从而列 column-wise softmax是q2c的权重,行row-wise softmax function是c2q的权重。
典型MRC的双向attention模型:AoA Reader, DCN, Bi-DAF -
One-Hop Interaction
One-hop interaction is a shallow architecture, where the interaction between the context and the question is computed only once 。早期的context-query interaction就是这样的one-hop结构,它在许多MRC系统中,比如AR,AS,AoA等等。当问题需要通过上下文的多个句子来推理的时候,one-hop很难预测正确答案。 -
Multi-Hop Interaction
it tries to 模仿 the rereading phenomenon of humans by computing the interaction between the context and the question more than once. 在interaction中,是否可以有效存储先前的隐层状态(已读的context和question),这将直接影响下一次interaction的performance.三种perform multi-hop interaction的方法:
(1). 第一种方法计算基于之前的context的attentive representations的context和question的相似度。
参考模型:Impatient Rreader model 。 每读一个question的token,就动态更新query-aware context representations. 这模仿了人类根据question重复阅读context的过程。(2). 第二种方法introduces external memory slots to 存储previous memories.
代表模型:memory networks.
优点:可以明显存储长期记忆,has easy access to reading memories. MRC模型can have a deeper understanding of the context and the question by multiple turns of interaction.
缺点:难易通过后向传播训练网络。
改善:end-to-end version of memory networks
介绍:explicit memory storage is embedded with continuous representations and the process of reading and updating memories is modeled by neural networks.
优点:can reduce supervision during training and is applicable to more tasks.在memoery networks中 使用Multiple hop更新内存的特性,使此方法在MRC系统中很受欢迎。
典型模型:MEMEN model
介绍:which stores ①question-aware context representations, ②context-aware question representations, ③and candidate answer representations in memory slots and ④updates them dynamically.
典型模型:论文[107]
介绍:使用external memory slots来存储question-aware context representations,并用双向GRUs来更新memories.(3). 第三种方法takes advantage of the recurrence feature of RNNs, using hidden states to store previous interaction information.
[91] 思路:using match-LSTM 结构的RNN。其他MRC模型:R-NET,IA Reader,也用RNNs去更新query-aware context representations来实现multi-hop interaction.
反正,efficient context-query interaction需要着重关注。gete mechanism 也是multi-hop interaction的重要组件。
下面的涉及Gate mechanism的模型:
模型:GA Reader (gated-attention reader),使用gate mechansim来确定更新上下文表示时question info如何影响对上下文单词的关注。gate attention mechanism 是通过query embeddings和上下文的中间表示(intermadiate representations)之间的元素逐次乘法(element-wise multiplication)来执行的。
相比于GA Reader,[78],This mechanism is capable of extracting evidence from the context and the question alternately. 而question根据之前的search states更新,上下文表示随着updated queries而用之前推理的信息refined, 然后使用了feed-forward的gate machanism来决定context和query匹配的程度。
之前的模型都忽视了在回答问题时context words有不同的重要性。因此,R-NET模型引入了gata mechanism来过滤context中不重要的部分,并强调与问题最相关的部分。R-NET可以看作attention-based rnn的变种,相比于match-LSTM,它引入了基于当前context representations和context-aware question表示的gate mechanism。并且尽管它是RNN-based models(insufficient memory), 但是它添加了self-attention to the context itself所以能处理好long documents的问题。
总结:one-hop interaction不能综合性的理解mutual question-context info。相比之下,有着之前contexts和questions记忆的multiple-hop interaction,可以深度地提取correlations,并且整个evidence for answer prediction。
3.2.4 Answer Prediction
The implementation of answer prediction is highly task-specific. 有3中预测回答的方法:word predictor, option selector, span extractor, answer generator.
(1) Wrod predictor
早期的工作中,用query-aware context representation来匹配候选答案。典型代表:Attentive Reader —— 使用query-aware context representations来匹配答案。
这个方法使用了attentive context repreentations来预测,但是它不能保证答案就在context中。
通过预训练的w2v后,february可能成为答案。

为了解决predicted answer可能不在context中的问题,有人提出了AS Reader, 它受pointer networks 的启发。
在AS Reader中,没有计算attentive representations, 反而,它们直接使用attention weight来预测答案。the attention resutls of the same word are added together, 有最大值的就是答案。这种方法很简单,但是对完型问题很有效。
(2) Option Selector
common way是:测量attentive context representations和候选答案的相似度,然后选择相似度最高的做为正确答案;
其他方法:
[4] 使用CNNs来encode question-options tuple和相关context sentences. 然后用余弦相似度来测量相关性,最相关的选项作为答案;
[111] introduce选项的信息,以帮助提取上下文和问题之间的interaction,在答案预测模块,根据attentive info, 使用bilinear function来score每个context,最高score的就是预测答案**;
[8] 所提出的convolutional spatial attention model(卷积空间注意模型),使用dot product来抽取context, question, options之间的correlations,从而计算了question-aware condidate 表示、context-aware表示、self-attended question的几个相似度。 然后这些不同的相似度被连接起来,fed to 不同kernel sizes的CNNs。CNNs被当做特征向量,然后fed to 全连接层来计算每个condidate的score。
(3) Span Extractor
可以看作完形填空任务的拓展,需要抽取的是subsequence而不是一个词。
同样受到pointer networks [89] 的影响,**[91]**提出了2种模型:the sequence model 和 the boundary model。
the sequence model输出的是answer token在original context中的的出现位置。答案预测的过程类似于seq2seq的decoding过程。通过这种方法获得的答案可能不是连续范围,并且不能确保是原始上下文的子序列。
应用
the boundary model可以解决以上问题,它只预测start and end potisions of the answer。它更简单并且在SQuAD上表现良好。广泛应用在MRC模型中。
但是the boundary model可能由于local maxima抽取到incorrect answer, [100] 提出了dynamic pointing decoder来解决。它通过多轮iterations来选择answer span. 此方法使用了LSTM基于答案预测last state相关表示来估计起始位置,使用了HMN(highway maxout networks——[21] + [79]) 来计算context tokens起始位置的score。
(4) Answer Generator
综合(synthesize)了context和question. 答案的表达形式可能与context中的不一样,或者答案来自于不同passages的多个片段。这个任务对答案预测模块有高要求,下面是几种生成fleible answers的方法:
S-NET:有"extraction and then synthesis" process. the extraction module 是R-NET的变种,the generation module是seq2seq结构。
encoder:
现有方法成生成的答案有着:语法错误(syntax errors)和逻辑问题。因此,generation和extraction methods总是同时使用来provide complementary info。
比如:S-NET的extraction module首先labels the approximiate boundary of the answer span, 然后generation module生成不限制于的原始context的答案。
应用 :
generation approaches在现在MRC系统中非常普遍,extraction methods在许多cases中已经表现得足够好。
再看一次这章节的图:general MRC architecture,以及用到的深度学习方法。
3.3 Additional Tricks
一些典型的深度学习tricks,这些不在general MRC architecture的范围里,但是这些技巧也很重要很有效。如:强化学习、anwer randker、sentence selector。
3.3.1 强化学习
reinforcement learning can be regarded as an improved approach in MRC systems that is capable of not only reducing the gap between optimization objectives and evaluation metrics(如:[101],[28]) but also determining whether to stop reasoning dynamically.(如:ReasonNets) With reinforcement learning, the model can be trained and refine better answers even if some states are discrete.
3.3.2 Answer Ranker
用ranker module, 答案预测的精度又可以提升一定程度。从而启发研究者去探索不可回答的问题。
[87] 结合了 pointer methods 的方法来ranker。用类似于[33]AS Reader的方法,用最高的attention sum score来选择一些answer span。然后把这些候选送入reasoner component,从而这些会送入question序列的placeholder, 通过计算probability来选择答案。
[108 用可变的长度抽取extract提出了2个方法。第一种方法是在验证集上捕捉到答案的POS 然后选择能最好匹配这些词性的子序列;第二种方法是context固定长度范围内enumerate所有可能的answer span。获得到这些答案候选以后,计算他们和question similarity的相似度从而选出最相似的作为答案。
3.3.3 Sentence Selector
尤其是在long document中,提前找到与questions最相关的sentences可以加速训练过程。因此 [51] 提出一个sentence selector来找到所需要回答question的句子的minimal set。sentence selector的结构是seq2seq,decoder会计算每个句子与question的相似度,如果后来decoder的score高于predefined threshold, 这个句子会be fed to the MRC systems.
此方法是一种降低training and inference时间的方式。
4 datasets and evaluation metrics
4.1 Datasets
In this part, we introduce several representative datasets of each MRC task, highlighting how to construct large-scale datasets according to task requirements, and how to reduce lexical overlap between questions and context.
4.1.1 Cloze Tests Datasets
CNN & Daily Mail :consisting of 93,000 articles from the CNN and 220,000 articles from the Daily Maile.all entities in documents are anonymized. missing items are named entities.
CBT : the Children’s Book Test (CBT): any word in the target sentence may be targeted; entities in the CBT dataset are not anonymized, so models can use background knowledge from wider contexts; missing items are named entites, nouns, verbs, prepositions.
LAMBADA : 也用books作为source,the word that needs to be predicted in LAMBADA is the last word in the target sentence. compared with CBT, LAMBADA requires more understanding of the wider context.
Who-did-What : in who-did-what, each sample is formed from two independent articles; one serves as the context and questions are generated from the other. (reduce the syntactic similarity).
CLOTH: 人造的,collected from English exams for Chinese students.
CliCR:based on clinical case reports for healthcare and medicine. 类似于CNN&Daliy Mail.
4.1.2 Multiple-Choice Datasets
MCTest : It consists of 500 fictional stories. Choosing fictional stories avoids introducing external knowledge, and questions can be answered according to the stories themselves. 用故事的语料库启发了其他数据集,比如CBT, LAMBADA. 但是就500个故事,太小了。
RACE: collected from English exams for middleschool and high-school Chinese students. almost all kinds of passages can be found in RACE。 large-scale,支持深度学习模型训练,需要更多的推理,有挑战性。
4.1.3 Span Extraction Datasets
SQuAD :MRC里程碑,启发了MRC多种技术的发展。不仅large还高质量,有563篇维基百科的文章,10w+人类设计的问题和对应span的回答。SQuAD定义了一种新的MRC task。
NewsQA :类似于SQuAD,另一种span extraction数据集。问题也是人类设计的,但是和SQuAD不同的是文章来源是CNN。一些问题根据给定context是无法回答的,这让questions更接近于现实,从而启发了SQuAD2.0. unanswerable quesions 会在5.2节详细介绍。
TriviaQA:之前的工作导致依赖quesions和evidence回答问题。现实中人们通常是寻找有用的resources来回答问题的。因此这个数据集收集了从trivia 和 quiz-league websites的question-anser pairs,然后在网页和维基百科搜索evidence来回答问题。最后build more than 650,00 question-answer-evidence triples for the MRC task.
DuoRC : reduce lexical overlap between questions and contexts. questions and answers in DuoRC are created from two different versions of documents corresponding to the same movie, one from Wikipedia and one from IMDb. requires more understanding and reasoning. unanswerable questions in DuoRC.
4.1.4 Free Answering Datasets
bAbI: It consists of 20 tasks. all data in bAbI is synthetic因此不是很接近于真实世界. 每个任务独立并且能反映文字理解的一个方面,比如识别2或3个论点关系. Answers are limited to a single word or a list of words and may not be directly found from the original context.
MS MARCO :可以看作MRC在SQuAD后的又一里程碑。有4个特征:①所有的问题来自于real user queries;②每个问题有bing搜索上的10篇相关文档作为context; ③这些问题的labeled answers是由人类生成的,所以他们不限制于context的一段话,会需要更多推理和总结;④每个问题有多重回答,有时这些回答甚至相互矛盾,这让系统选择出正确的答案变得更有挑战性。MS MARCO让MRC数据集更加贴近现实世界。
SearchQA:like TriviaQA. 作者collect question-answer pairs from the J!Archive and then search for snippets related to questions(大约每个pari有49.6个相关snippets,Trivia只有1篇document) from Google.
NarrativeQA:Based on book stories and movie scripts, they search related summaries from Wikipedia and ask co-workers to generate question-answer pairs according to those summaries. 要回答问题需要理解整个narrative,而不是表面的matching info.
DuReader:类似于MS MARCO。另一个现实世界使用的large-scale MRC数据集。问题和documents收集于百度搜索和百度知道。答案和人类生成的,而不是spans of original context.并且它有一些新的问题形式比如yes/no 和opinion. questions有事需要summary over multiple parts of documents.
4.2 Evaluation Metrics
cloze tests 和 multiple-choice tasks, 最常用的metric是accuracy.
span extraction:exact match(EM) (accuracy的变形),和 F1 score
free answers : ROUGE-L, BLEU 被广泛使用。
Accuracy :Q={Q1,Q2,…Qm}共m个问题,这样计算精度:
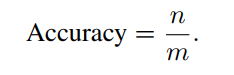
Exact match:评估了一个预测的答案范围是否准备匹配ground-truth sequence. 如果预测的答案等于the gold answer, 则EM是1,否则是0。它也可以用上面的公式计算。
F1 Score:是分类任务中的common metric. 在MRC中,condicate和参考答案(reference answers)被当做bags of tokens和 TP,FP,TN,FN(true positive, false positive, true negative and false negative),如下表:

precision和recall这样计算:

F1是presicion 和recall的谐波平均值:F1 = 2PR / (P+R), P是precision,R是recall
和EM比起来,F1松散地测量预测值与真实答案之间的平均重叠。
ROUGE-L:ROUGE原来是自动生成里的评估指标。它通过计算生成的模型摘要与真实摘要之间的重叠量来评估摘要的质量。ROUGE有ROUGE-N, ROUGE-L, ROUGE-W, and ROUGE-S的方式,其中ROUGE-L在MRC的free answering中广泛使用。-L更灵活,L代表: longest common subsequence (LCS). 计算方式如图:
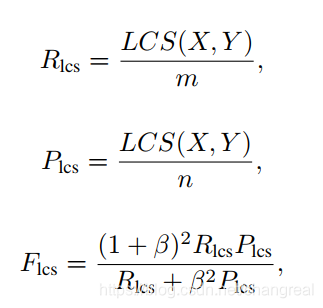
ROUGE-L来评估不需要预测的答案是ground truth的连续序列,尽管更多的重叠有助于更高的分数。
BLEU:Bilingual Evaluation Understudy,广泛适用于评估翻译系统。在MRC中,BLEU score can not only evaluate the similarity between candidate answers and ground-truth answers but also test the readability of candidates.(太复杂了,具体的计算看论文8)
5 New Trends
基于知识的MRC;
不可回答问题的MRC;
多文档的MRC;
会话的MRC
Knowledge-Based Machine Reading Comprehension 基于知识的MRC
MRC requires answering questions with knowledge implicit in the given context. knowledge-based machine reading comprehension (KBMRC) . KBMRC的输入就是添加了从knowladge bases抽取的相关知识,这在KBMRC很关键。KBMRC可以看作用external knowledge K扩充MRC,公式化后如下:

KBMRC的数据集有MCScripts ,它关于人类的daily activities. 其中有些问题在context里无法回答,会需要不在context里的common sense知识。
KBMRC的挑战如下:
- 知识检索:从存储了各种不同知识的knowledge bases里抽取出相关context和question的知识。
- 知识整合:knowledge有它自己的结构,如何把他们encode并且整合进context和question的表示里,这是一个仍在研究的问题。
解决以上KBMRC的问题
[44] 提出的类似于完型填空的方式,rare entity prediction,区别是仅仅依赖original context是无法回答问题的。这个任务需要添加从知识库里抽取的entity description来帮助预测entity。在整合这些external knowledge,使用的方法有:
- [102],[48] 设计了 有哨兵的attention机制 来考虑知识与context, question的相关性,并且要避免不相关的知识进来误导预测(要不要和要哪些知识);
- [82] 使用了 key-value的memory network 来决定相关信息:所有相关知识存储在memory slot里作为key-value pairs. 然后key匹配query也计算values权重和得到相关知识表示
- [90] 提出了一种数据增强方式,用WordNet的semantic relations,然后找出passage words中和context和question每个词有对应语义关系的position information,这些位置信息被当做external knowledge,然后fed to MRC model.
5.2 Machine Reading Comprehension with Unanswerable Questions
有些问题是不可回答的,这才更接近于真实世界。一个成熟的MRC系统要能辨别出不可回答的问题。因此MRC处理过程包含2个子任务:answerability detection 和 reading comprehension, (辨别出不可回答的问题,并仅给可回答的问题给出正确答案),定义如下:

总体来说,对于不可回答的问题,要实现3点:不可回答问题检测、回答问题、答案检验;
不可回答问题有2个挑战:
-
Unanswerable Question Detection
模型需要知道它不知道的东西,然后mark them不可回答 -
Plausible Answer Discrimination
MRC模型为了避免给出fake answer, 需要检查预测的答案,并且从中tell plausible answers. 方法可以分为以下2类:
第一种:indicate no-answer cases :
法1:使用share-normalization + 添加额外的trainable bias + softmax来获得distributions of no answer的概率,如果概率大于the best span的概率,这意味着问题不可回答;
法2:设置一个global confidence threshold,如果predicted answer confidence低于这个阈值,意味着不可回答;这种方法不能保证答案是正确的。
法3:padding。[85] 为原始passage添加了一个padding position,来决定问题是否是可回答的。
2种loss,对于不可回答的问题检测,提出了两种辅助loss:independent span loss 和 sequential architecture。见论文
第二种:ledigtimacy of answer
法1:sequence architecture。 把question, answer, 包含备选答案的context当做一整个sequence,然后输入fine-tune的transformer model来预测没有答案的概率
法2:interactive architecture。计算context里的question和answer的correlation来分类问题是否可回答。
法3:整合以上2种,连接两种方法的outputs作为joint representations。
除了以上的pipeline structure, [81] 使用了多任务学习 来联合训练answer prediction, no-answer detection, answer validation。用一个联合通用节点来区分这些,这些fused representations可以用来判断问题是否可以回答。
5.3 Multi-Passage Machine Reading Comprehension
This extension can be applied to tackle open-domain question-answering tasks based on a large corpus of
unstructured text.
基于大规模无结构文本语料,可以用于处理开放领域的问答任务。MRC multi-passage具体任务数据集: MS MARCO , TriviaQA, SearchQA , DuReader , and QUASAR.
定义:

多任务MRC比其他MRC任务更有挑战性,它有以下几个特征,而检索的效率是关键:
- massive document corpus
- noisy document retrival
- no answer
- multiple answer
- evidence aggregation
pipeline
为了解决多文档MRC问题,一种pipeline的方法是"retrieve then read",也就是retrieve component先返回几个相关文档,然后送入reader,来给出正确的答案。
比如陈丹琦的 DrQA,就是典型的pipeline-based multi-passage MRC model. 它的检索组件是使用TF-IDF来为SQuAD上的每个问题选择5篇相关维基百科文章来缩小搜索空间,然后reader module,使用rich word representation 可以改善模型,然后pointer module来预测答案的起始位置。
但是陈丹琦的模型检索和reading是各自分来的,这有一个问题就是在检索阶段的errors很容易传播到reader module里,这导致了表现大大降低。为了减轻poor document retrieve引起的 error propagation,一个方法是ranker component,另一个是jointly train the retrieve and reading process,具体如下:
对于reader component里,[27] 提到两种ranker,InferSent 和 Relation-Networks Ranker,分别使用了feed-forward network 和 relation-network。而**[37]**使用了Paragraph Ranker mechanism——使用了双向LSTMs+点乘。
对于joint traning, [92] 的 Reinforced Ranker-Reader (R3) 是代表性的模型。R3用match-LSTM来计算问题和每个passage的相似度从而获取文档表示,然后表示fed to ranker和reader。在ranker模型里强化学习 用来选出最相关的passage,
检索方面
以上的检索组件都太低效了, 比如DrQA仅仅使用传统的IR方法,R3使用question-dependent passage representations来rank,他们的计算复杂度会随着文档语料的增加而变大。为了加速过程,[15] 提出了一种快速和高效的检 索方法,该方法表示独立于问题,并离线存储输出(见论文)。
多个候选答案方面
在选择答案方面,[58]提出了三种启发式的方法:RAND, MAX, SUM。而[41]引入了fast paragraph selector 来过滤掉有错误answer labels的passages。
evidence aggregation方面
[93] 认为整合evidence很重要。他们认为:正确的答案有更多evidence,这些evidence在不同passage里。并且一些问题需要不同层面的eevidence来回答。 为了充分利用multiple pieces of evidence, 他们提出了strength-based 和coverage-based re-ranker。前者里候选者中出现次数最多的答案被选中,后者里concanate所有包含候选答案的passages,作为一个新的context然后feed to the reader,这样之后获取的答案有不同层面的evidence.
总结
multi-passage MRC很接近于真实世界的应用。预测答案需要更多evidence,related document retrieval很重要,从众多documents里evidence aggragation可能补充or矛盾。因此,自由形式的回答在multi-passage任务里很普遍。多文档MRC有很长的路要走!
5.4 Conversational Machine Reading Comprehension
基于之前的回答,a related question需要deeper understanding. Conversational machine reading comprehension ( CMRC ) has become the research hot spot.
定义 :
会话历史H,conversation history H 作为context的一部分。

相关数据集:
CoQA, QuAC, [46]基于完形填空的拓展——multiparty dialog。
CMRC给MRC带来了一些新的挑战,如:
- Conversational History
dialogue pairs as conversational history are fed to CMRC systems as inputs. - Coreference Resolution共指解析
有两种共指解析:explicit 和 implicit。implicit coreference更难解决。
会话MRC的一些模型和方法
[69] 的混合模型:DrQA + PGNet ,结合了seq2seq + MRC模型来抽取和生成答案,他们把之前的question-answer paris作为一个sequence然后添加进context。
[105] 使用了一个改善的MRC model,Bi-DAF++ + ELMo 来基于context和history回答。
[30] 不仅仅简单concatenate之前的问答对作为inputs,还引入了flow mechanism来深度理解会话历史,在处理回答先前问题的过程中encode hidden context representations.
[110] 相似于[69],把之前的问答对添加到现在的questions里,为了找到历史会话的相关性,他们还对questions添加了self-attention。
在coreference resolution 上鲜有所成,如果共指解析不能被正确解决,会导致performance degradation。
6 Open Issues
一些open issues还没解决,比如machine inference, open-domain QA。现在最重要的问题是,neural MRC并不真的理解given text, 现存的模型大多数主要依赖 semantic matching to answer question . 在以下方面MRC和人类阅读理解有巨大的gap:
- 给定上下文的限制 Limitation of Given Context
- MRC系统的鲁棒性
- 拓展知识的整合 Incorporation of External Knowledge
- 缺少推理能力
- 解释困难 Difficulty of Interpretation
展开来说:
-
Limitation of Given Context
context在MRC任务里很必要,但是在现实世界里有限制。multi-passage MRC的研究一定程度上打破了given context的限制。相关resources决定了回答问题的准确度,如何有效地为MRC系统找到最相关的资源,这还有很长的路要走。这需要把信息检索和机器阅读理解进行深度结合! -
MRC系统的鲁棒性
现存的大多数MRC系统还是基于word overlap,他们面对对抗性(adversarial)的问答对表现很弱。这也反映了机器并不是真的理解自然语言,尽管answer verification component 可以减轻side-effect of plausible answers,MRC系统的鲁棒性需要加强! -
Incorporation of External Knowledge
问题在于有效的引入和利用外界知识。一方面,知识库里的知识存储结构不同于text from context and questions,因此很难整合;另一方面,知识库的质量很重要,但是构建知识库很费时间。此外,知识库里的知识是分散的,相关external knowledge不能直接找到。因此,有效地 融合知识图谱和MRC 需要进一步研究。 -
Lack of Inference Ability
现存大多数MRC系统基于semantic matching这导致MRC系统推理能力不足。比如:2个人躺在地上,5个人躺在床上,答案不能推理出7个人躺着。 -
Difficulty of Interpretation
MRC系统有多种任务,但是他们的工作仍是以黑盒的方式进行。缺乏解释性是MRC应用方面的主要缺点,比如在healthcare上面,是否能给出一个理性的outputs,这是trust的必要条件。这时就要提一下HotpotQA数据集,它的问题需要从多个支持文档、有用的labels sentecnes里推理,因此MRC系统可以用这些信息来解释预测。再提一下 XAI (explainable artificial interlligence)。
总之,为了更多实际应用,MRC系统需要更加值得信赖和透明。
7 总结
本文对MRC的发展过程做了深度的调研,
- 基于最近的工作的彻底分析,作者给出了具体的MRC任务并且深度地比较了他们;
- MRC模型的通用结构分为了四个模块,并详细介绍了每个模块的主要方法;
- 根据不同MRC任务介绍了代表性的数据集和Metrics
- 介绍了一些新的发展趋势和open issues
8 论文里提到的一些术语