一、概要
通过知识库回答自然语言问题是一个重要的具有挑战性的任务。大多数目前的系统依赖于手工特征和规则。本篇论文,我们介绍了MCCNNs,从三个不同层面(答案路径,答案类型,答案上下文)来理解问题。同时,在知识库中我们共同学习实体和关系的低维词向量。问答对用于训练模型以对候选答案进行排名。我们还利用问题释义以多任务学习方式训练列网络。我们使用Freebase作为知识库,在WebQuestions数据集上进行实验。此外,我们提出了一种计算不同列网络中问题词的显着性得分的方法。结果有助于我们直观地了解MCCNN学到的知识。
二、介绍
自动问答系统返回自然语言问题的直接和正确的答案。目前为止,对于这个任务有两个主流的方法。第一个方法依赖于语义解析,第二个方法依赖于信息抽取。
语义解析器通过将他们转换为逻辑形式来理解自然语言问题。然后,解析结果用于生成结构化查询来查找知识库获得答案。最近的研究工作着重于使用问答对,而不是问题的标注逻辑形式,因为弱训练信号降低标注成本。但是,他们中的一些人仍假设一组固定的和预定义的词汇触发器,这些触发器限制了它们的领域和可扩展性能力。此外,他们需要手动设计语义解析器的特征。
第二个方法使用信息抽取来进行开放域问答。这类方法从知识库中检索候选答案的集合,提取问题和候选答案的特征来对候选答案排名。然而,这类方法依赖于规则和依存分析结果来提取问题的手工特征。
另外,一些方法使用问题词向量的总和来表示问题,这忽略了词序信息并且不同处理复杂的问题。
本篇论文,我们介绍了MCCNNs从不同方面自动分析问题。该模型共享相同的词向量来表示问题单词。MCCNNs从输入问题中使用不同列的网络来提取答案类型,关系和上下文信息。知识库中的实体和关系也都表示为低维向量。然后,评分层根据问题和候选答案的表示对候选答案排名。所提出的基于信息抽取的方法利用问答对自动学习模型,而不依赖于手工注释的形式和手工特征。我们也没用使用任何的词法触发器和规则。此外,问题释义还用于训练网络并以多任务学习方式概况生词。早WebQuestions数据集进行实验,结果优于baseline:
本篇文章有三个贡献:
- 我们介绍了多列的卷积神经网络来理解问题,不依赖于手工特征和规则,并且利用问题释义以多任务学习的方式来训练列网络和词向量。
- 我们共同学习FREEBASE中实体和关系的低维词向量,并将问答对作为监督信号;
- 我们在WEBQUESTIONS数据集上进行了大量实验,并通过开发一种检测不同列网络中显著问题单词的方法,为MCCNN提供了一些直观的解释。
三、相关工作
主要介绍了主流的两个传统方法,上面已经介绍过了,这里不再介绍。
四、建立过程
给定一个自然语言问题q =
…
,我们从FreeBase中检索相关的实体和属性,作为候选答案
。我们的目标是对这些候选答案进行评分并且预测答案。一个问题可能有几个正确答案。为了训练模型,我们使用没有标注逻辑形式的问答对。首先我们先描述一下数据集:
WebQuestions:数据集包括3778训练实例和2032测试实例。将训练实例分为80%训练集和20%验证集。
Freebase:由一般事实组成的大规模知识库,事实格式为 subject-property-object的三元组。保留其中一个实体出现在WebQuestions的训练集 / 验证集或者CLUEWEB的三元组,移除实体次数少于5次的三元组。
WikiAnswers:Fader et al.(2013)在WikiAnswers中提取了相似问题并将他们作为问题释义,用于概括生词和问题模式。
五、方法
我们使用多列卷积神经网络来学习问题的表示,模型共享相同的词向量,这些列描述问题的不同层面。比如答案路径、答案类型、答案上下文。向量表示为
。相应地,我们也学习候选答案的表示,对每一个候选答案a,表示为
。使用问题和答案的表示,我们可以计算问答对的分数。评分函数S(q,a)定义为:
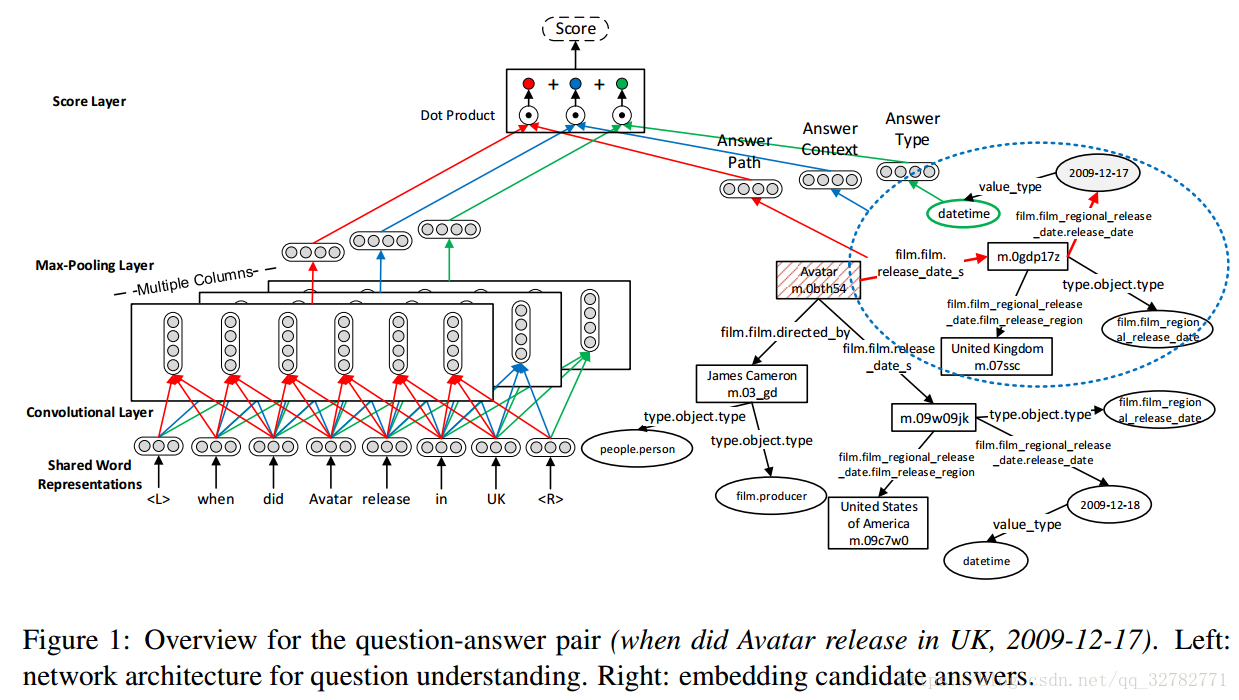
1. 候选答案的生成
给定一个问题,首要步骤就是从Freebase知识库中检索候选答案。问题应该包含一个确定的实体,该实体可以链接到知识库中。我们使用Freebase Search API查询问题中的命名实体。如果没有任何命名实体,那么名词短语代替。我使用排在第一位置的实体。然后链接到该实体的全部2跳之内的节点作为候选答案。对给定问题q,我们用Cq表示候选答案集。
2. 问题理解
MCCNNs使用多列的卷积神经网络从共享词向量中学习问题的不同层面的特征。对于问题q =
,lookup layer将每一个单词转换为一个向量
,其中
是词向量矩阵,
是
的one-hot表示,|V|是词汇大小。词向量在训练过程中更新。
卷积层计算滑动窗口中单词的表示。对第 i 列的MCCNNs,卷积层对问题q计算n个向量,第j个向量表示如下:
其中(2s + 1)是窗口大小,
是卷积层的权重矩阵,
是bias向量,h(·)是非线性函数(softsign,tanh,sigmoid)。填充左右不存在的单词。
最终,经过最大池化层获得问题的固定大小向量表示。在第i列MCCNNs的最大池化层计算问题q的表示通过:
其中 max{·}是向量的元素运算符。
3. 候选答案嵌入
候选答案a的向量表示为
,表示答案a的不同方面的特征。嵌入方法表示如下:
-
答案路径: 答案路径是答案节点与问题中实体之间关系的集合。如Figure1所示,实体Avatar和正确答案节点之间2跳的路径是(film.film.release_date_s,film.film_regional_release_date.release_date). 的向量表示通过 ,其中 是第一范式, 是一个二元向量表示答案路径的每一个关系是否出现, 是参数矩阵,|R|是关系的数目。换句话说,出现在答案路径上的关系的词向量是求了平均的。
-
答案上下文: 连接着答案路径上的1跳的实体和关系被视为答案的上下文。上下文的表示是 ,其中 是参数矩阵, 是一个二元向量表示上下文节点是否存在,|C|是出现在答案上下文中的实体和关系数。
-
答案类型: , 是参数矩阵, 是一个二元向量表示答案类型是否出现,|T|是类型数。
4. 模型训练
对问题q的每个正确答案
,我们随机从候选答案
中采样k个错误答案
,作为负样本来评估参数。使用hinge loss作为损失函数:
目标函数定义为:
5. 预测
测试过程中,我们对问题q检索所有的候选答案
,对每一个候选答案
,我们计算它的分数
。最高分数的候选答案作为预测结果。
一些问题可能不止一个正确答案,我们需要一个标准来决定分数的阈值。
这个公式表明候选答案的分数与最优答案的分数差距小于m时,该候选答案作为预测结果。
6. 多任务学习的问题释义
我们使用问题释义数据集WikiAnswers来概括在问答对的训练集中未出现的单词和问题模式。与模型训练过程差不多,hinge loss为:
其中
是在相同的释义簇P中,
是从另一个簇中随机采样获得。目标函数为:
六、实验
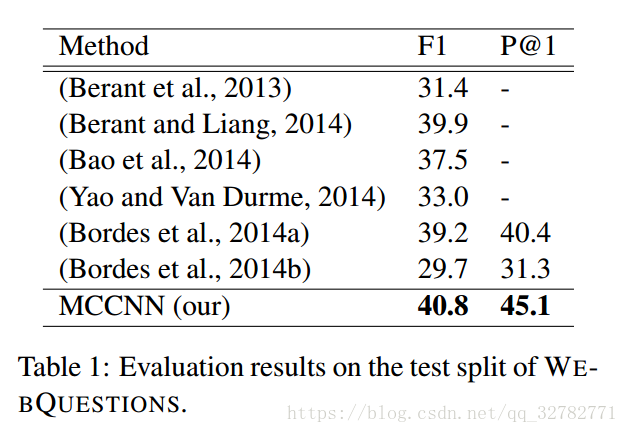
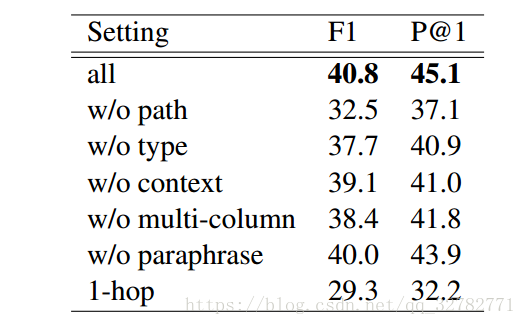
实验过程不作介绍,只贴一下作者与其它方法的对比图以及移除一个模块的对比图:
- 错误分析
- 候选答案的生成。问题提到的一些实体链接错误了,比如缩写,或只提到了实体的一部分
- 时间问题。比如问题:who is johnny cash’s first wife ?答案是提供第一任妻子,而系统给出第二任妻子,因为两者的关系是相同的。
- 模棱两可的问题。“what has anna kendrick been in ”是问她演过的电影。这个问题没有明确的线索词来表示意义,因此很难对候选答案进行排名。
七、总结
本篇论文作者提出了MCCNNs模型在不同层面上提取问题和答案的特征,捕获了更多的信息,从实验结果看也是state-of-the-art的。大量参数都是训练生成的,那么训练调参就比较困难,而且训练时间也比较长。问题和答案的表示都是基于词向量的,可以考虑结合字向量获得更丰富的信息。