综述:文中描述当前阅读理解任务中受限于监督学习设置,以及可用的数据集。这篇论文主要提出关于阅读理解任务中的对抗学习以及self-play.它用一个名为reader network来找到关于text和query的答案,还用一个名为narrator network的网络来混淆text的内容,来降低reader network网络成功的可能性。然后取得了较好的效果。
文章的贡献:
1,提出了一个新的基于对抗学习的机器阅读理解的范例。
2,这种方式克服了要求监督信息的要求,以及在query-answer中提供稳健的噪音。
3,可视化了模型在query推理过程中的注意力转变。
模型的主题流程如下:
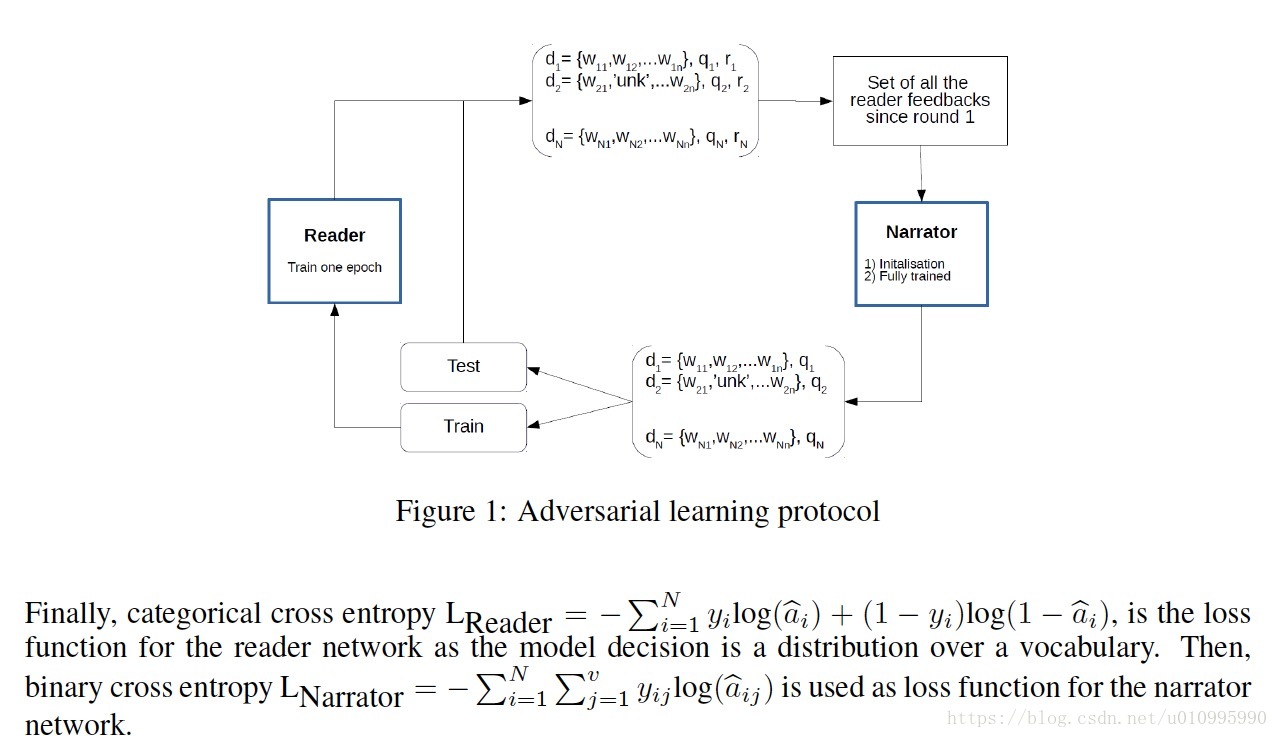
1,在每轮训练开始前,narrator 会混淆数据中的一些story中的单词(用UNK替代),固定这个混淆比例。ratio=corrupted_data/clear_data。记住训练集和测试集中都包含有混淆数据。
2,然后narrator从reader network获得一个反馈值,这个值得具体计算方式为,如果reader network在没混淆的d上回答正确,而在混淆的dobf上回答错误,那么r=1,否则为0。如图
3,所有以前收集的r值都会被存储下来和运用于整个训练过程中,并且narrator network的网络参数在每次迭代之前都会被重新初始化。
4,每次epoch中,narrator混淆数据是为了80%来期望最大化它的reward,剩下的20%用来确保探索。
5,最终,reader network在每次迭代中保持提升,并且一些灾难性的遗忘会在下一轮中的narrator network中得到补偿,通过聚焦于这些缺陷。

Reader network
它采用的是Gated end-to-end network 简称GMemN2N,具体实现过程和我上篇笔记类似,这里不再赘述。GMemN2N,也是使用两个emb矩阵表示doc,第三个emb举证来表示query,然后通过query与其中的一个点积、softmax算Attention,然后与doc矩阵dot运算得到结果。它的最后一层使用的是softmax层,因为有多个候选答案。
Narrator Network
这个模型的目的是为了预测reader network成功回答一个有混淆词的doc的概率。这里的模型结构也是使用的一个类似于reader network的GMemN2N网络结构。但是他在最后一层使用的是sigmoid层,来预测reader network回答失败的概率。
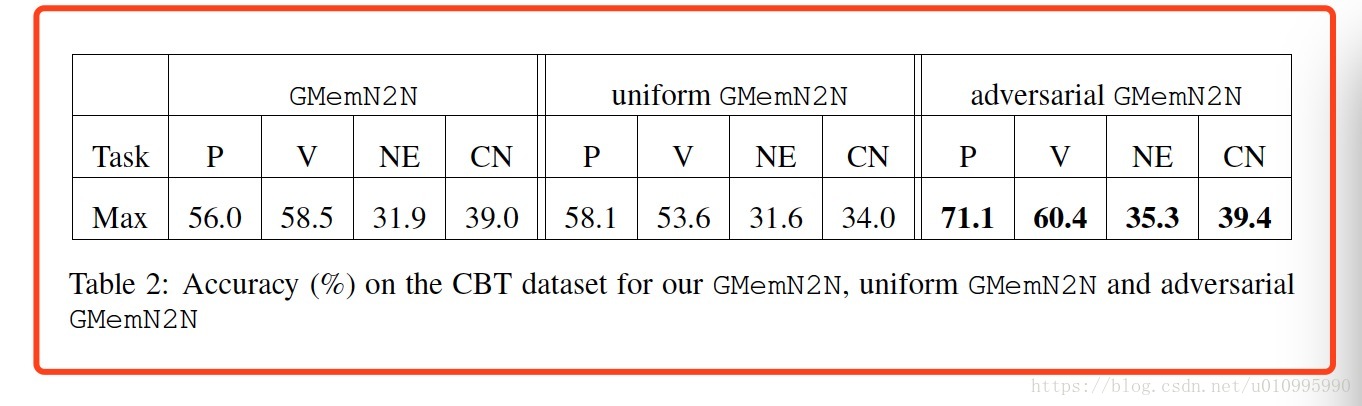
实验结果如下: