ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
改进版通道注意力
from CVPR2020
期末结束,开始投入论文和实验的海洋
摘要:
通道注意力有效提升了CNN的性能,但是随着一系列复杂注意力模块的提出不可避免增加了计算成本。为了平衡性能和复杂度,本文设计了一种超轻量级的注意力模块-ECA Module(Efficient Channel Attention)来提升大型CNN的性能。ECA Module只包含k个参数(k<=9)。
在SE-Net中我们发现避免降维、有适当的通道交互是十分重要的,因此本文使用了一种局部的跨通道交互策略,通过一维卷积就可快速实现。此外,本文还设计了一种自适应的一维卷积函数加速训练收敛。
ECA-Module可方便的集成到现有CNN的框架中,本文将ECA-Net在分类、物体检测、实力分割实验中进行了测试,选用的backbone是ResNet系列和MobileNetV2.目前代码已开源:
ECA-Net
Section I Introduction
深度卷积神经网络被广泛用于AI领域,已成功应用于图像分类、物体检测、语义分割等领域。近期在卷积模块中引入注意力机制这一思路成为很多人关注的焦点,其中代表性的工作是SE-Net,巧妙地学习了每一个卷积模块的通道注意力用于CNN性能的提升。基于此,其他学者做了一系列改进,如提取更复杂的通道依赖关系,或者将通道注意力与空间注意力结合。尽管以上策略都有效提升各精度,但不可避免的增加了模型复杂度和对算力的要求。
与前人研究相比,本文致力于解决这样一个问题:是否可以以一种更高效的方式来学习通道注意力?
为了回答这一问题,本文首先回顾了SE-Net,在SE-Net中输入特征首先会逐通道经过全局均值池化,随后经过两层全连接层,最后经过Sigmoid非线性激活后产生每一通道的权重。这两层FC的作用就是捕获跨通道之间的非线性交互,这样可以有效降低维度。虽然这一策略被广泛应用于其他任务,但经验告诉我们降维不可避免会带来副作用,而且不利于捕获通道之间的依赖关系。
基于以上分析,如何减少维度损失同时高效捕获通道之间的交互变得十分重要。本文的ECA-Module如Fig2所示,在经过SE的全局均值池化后,ECA-Module会考虑每个通道及其k个近邻,通过一维卷积快速完成通道权重的计算。K就代表了在一个通道权重的计算过程中参与的近邻数目,k的数目很明显会影响ECA计算的效率和有效性。为此,我们提出了自适应计算k的函数。
可以看到,在嵌入各种注意力模块的对比中,ECA-Net在参量较少的情况下取得了更高精度。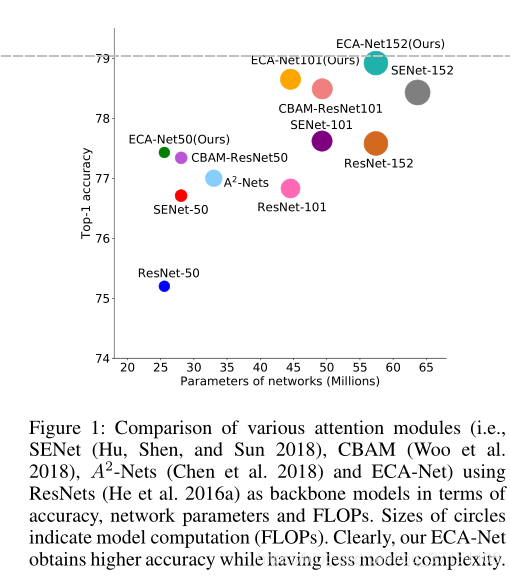
Section II Related Work
自从2018年SE-Net的提出,注意力机制广泛用于提升CNN的性能,施加注意力的策略可大致分为两类:
(1)增强特征聚合程度;
(2)结合空间注意力与通道注意力。
比如CBAM使用均值池化和最大池化来聚合特征,GSop引入二阶池化更高效的完成特征聚合,GE使用的是深度可分离卷积来局和特征。
类似的注意力思想还体现在DA-Net,CC-Net中。但这些局部注意力模块仅适用于部分卷积模块中因为会增加模型的复杂度。而ECA旨在较低复杂度的基础上高效学习注意力,通过捕获通道间的交互作用这种思想适合于高效轻量级CNN的设计。在这一方面前人比较突出的工作有群卷积(group convolution)和深度可分离卷积(depthwise separable convolution),但ECA Module中将FC层用1D卷积代替了,和群卷积、深度可分离卷积相比,ECA的这种实现效果更佳。
Section III Proposed Method
本文首先回顾了SE-Net中的通道注意力模块,随后基于经验分析对比了降维和通道间的交互作用。在ECA Module中引入了adaptive kernel size selection自适应核选取。
Part A Channel Attention
SE Block中通道注意力通过以下方式计算:
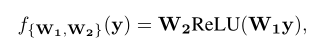
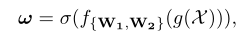
对比分析
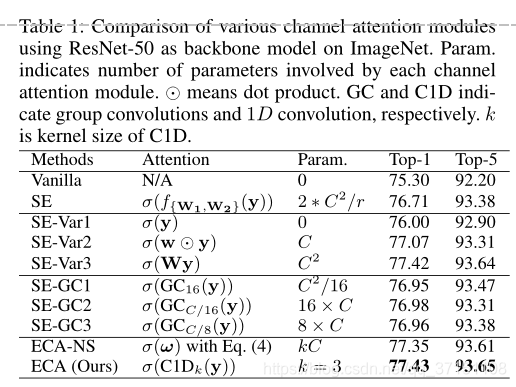
Dimensionality Reduction:降维会使得通道和权重的对应关系不再直接。比如在Table I中对比了SE block的三种变体SE-Var1,SE-Var2,SE-Var3,(其中SE-Var1没有引入任何参数,SE-Var2分别独立的学习每个通道的权重,SE-Var3采用了一层FC层)这三种均未进行维度压缩,可以看到这三种变体都比原始结构效果好,说明通道注意力确实对CNN有提升效果。
Part B 局部通道间交互
SE-Var3比SE-Var2效果更佳的原因在于,SE-Var3捕捉了通道间的交互关系,而SE-Var2没有。但代价就是SE-Var3使得参量大大增加,SE-Var2可被看作采用的是深度可分离卷积,而另一种群卷积也可作为捕捉通道间交互作用的高效方式。
群卷积会把一个全连接层分成不同的组,每一组单独进行线性变换,如SE-Block经群卷积操作后:

参数量为C2/G,G就是分组的组数。但从Table I中可以看到,SE-GC没有明显的提醒,而且过多的群卷积还会增加内存开销。
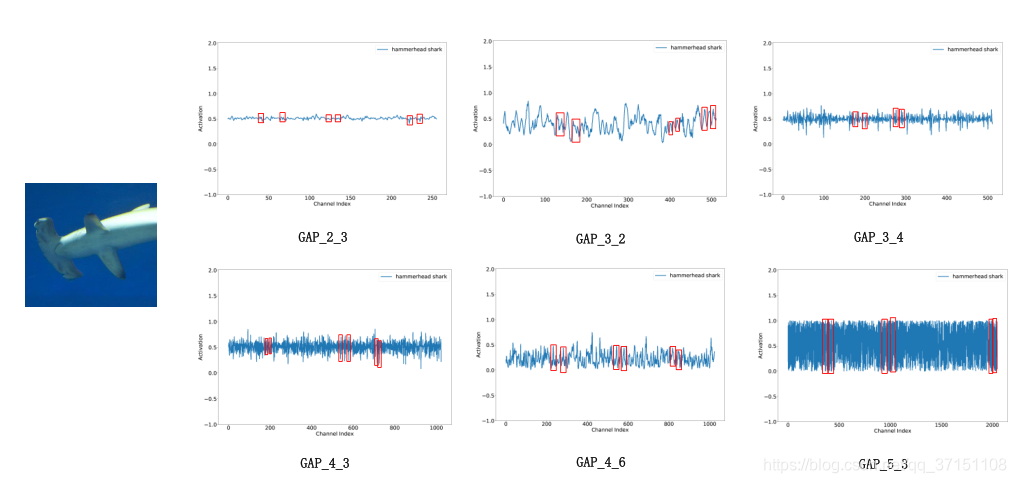
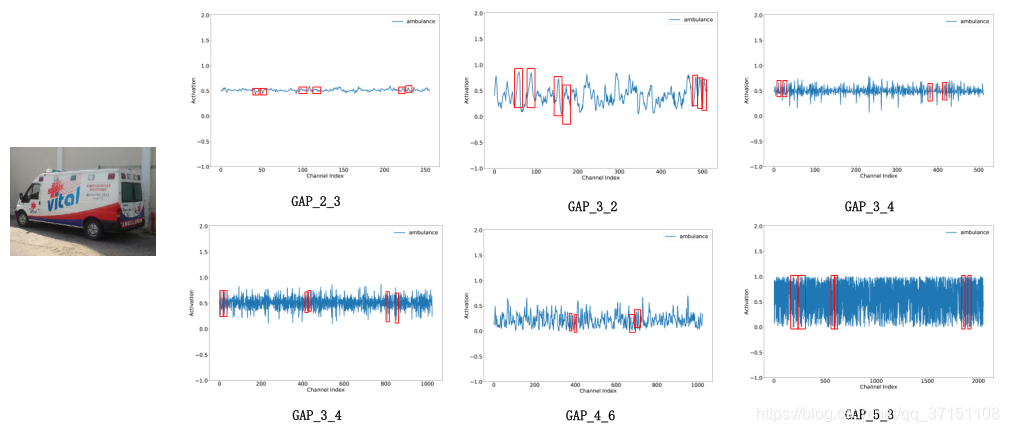
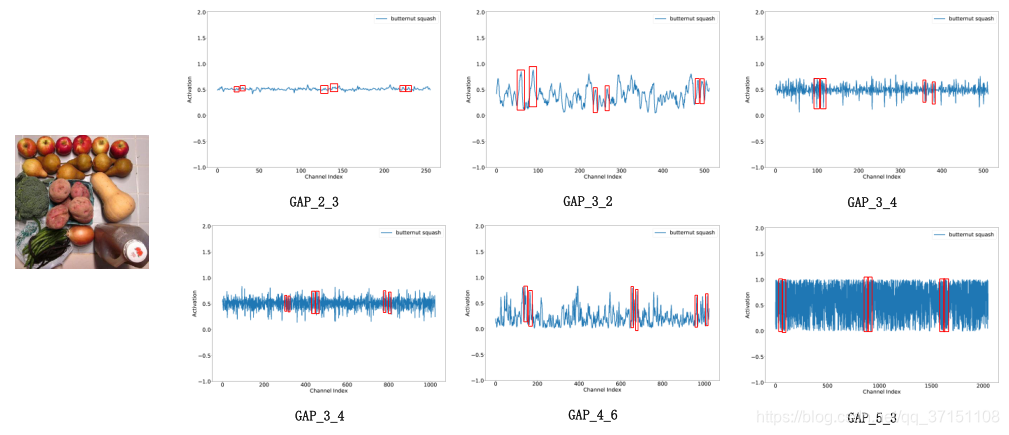
通过可视化一些输出的特征图谱,如可视化GAP后的激活值,本文发现不同图像在同层的结果展现出一种“局部周期性(local periodicity),因此本文力图捕获这种通道间的交互关系,只考虑某通道和它的k个临近,因此权重矩阵计算如下:
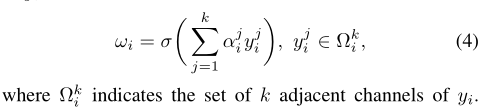 这种局部性的计算避免了在所有通道上的计算,参数量为C*k,计算更高效;为了提高效率还在所有通道上共享权重信息。
这种局部性的计算避免了在所有通道上的计算,参数量为C*k,计算更高效;为了提高效率还在所有通道上共享权重信息。
此外,这种高效的通道注意力计算方式可快速通过1D卷积(C1D)实现。比如Tavle I中采用k=3,在模型精简的前提下取得了和SE-Var3近似的效果。

Part C Adaptive Kernel Selection
在ECA Block中,k是一个关键参数,它决定了局部交互的范围、收敛,不同CNN结构或者不同通道数的情况下k的选取可能不同,虽然可以慢慢微调但这比较费计算资源。
很明显k和通道C的规模有关,通常情况下大尺寸便于捕捉长程依赖关系,小尺寸倾向于捕捉短程交互,换言之,k和C之间存在一种映射关系,本文以指数函数来描绘这种非线性映射关系。
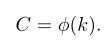
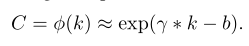 由于通道数!通常为2的指数被,因此,k最终可由下式决定:
由于通道数!通常为2的指数被,因此,k最终可由下式决定:
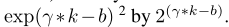
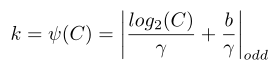
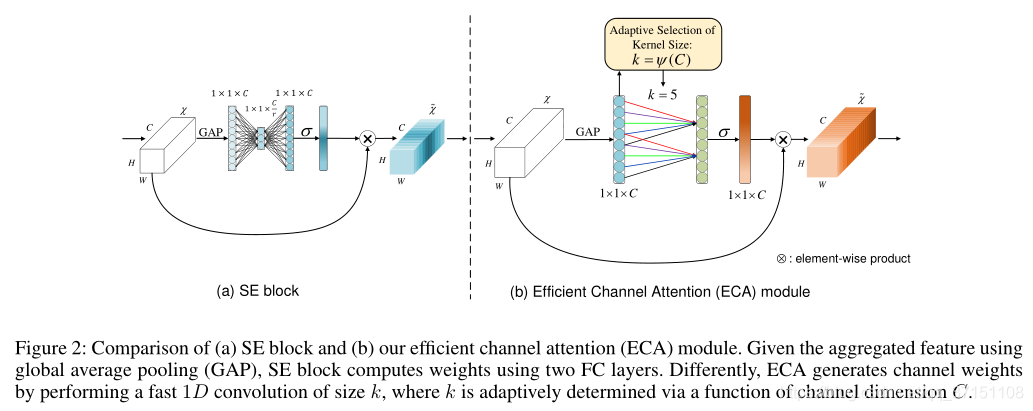 SE Block v.s. ECA Module
SE Block v.s. ECA Module
可以看到,SE的注意力是经过两层FC计算得到,而ECA是通过k=5个临近通道计算得到的。
Part IV Experiments
实验测试了ECA Module在分类和检测任务上的效果,首先探究的是k的选取对ECA Module的作用,在ImageNet与其他网络进行了比较;随后基于Faster R-CNN和Mask R-CNN进行了物体检测。
Part A Classification
实验设置细节
Backbone:ResNet系列:ResNet-50,ResNet-101,ResNet-152;MobileNet
前面经过了数据增强、超参设置。输入图像随机裁剪至224*224大小,使用SGD优化,权重衰减
训练了100epochs,权重每隔30epoch衰减
在MobileNet-V2中
1.k的选取
首先测试了k从3-9对ECA效果的影响。在所有卷积模块中使用同一个设置的k,实验结果显示k=9(ResNet50)和k=5(ResNet101)时效果最佳.可以看到101中间层数更多,,所以更青睐于小的k
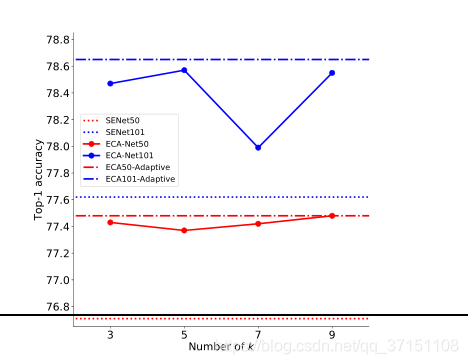 2.ResNet-50
2.ResNet-50
Table II展示了基于ResNet系列ECA与其他注意力模块的对比结果,分别比较了网络参量、FLOPs、推断时间及准确率。可以看到ECA-Net在和原始ResNet50相近规模的前提下达到了更好的准确性。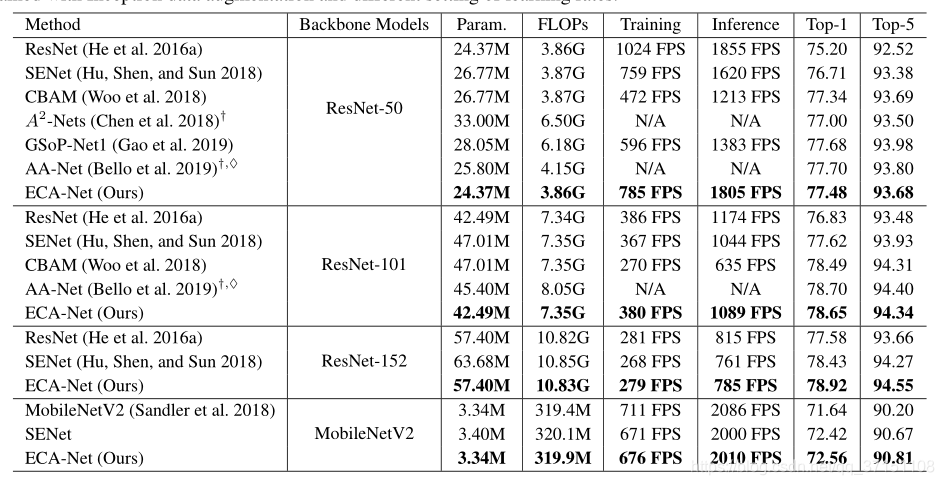 3.MobileNet
3.MobileNet
在MobileNetv2中,在残差连接前使用了SE block和ECA Module,从Table II中可以看出ECA-Net比原始网络提高了0.9%,而且比SE-Net网络规模更小,效率更高。
Part B Object Detection
物体检测基于MS COCO数据集,backbone为Faster R-CNN和Mask R-CNN
优化:SGD,权重衰减
1.Faster R-CNN
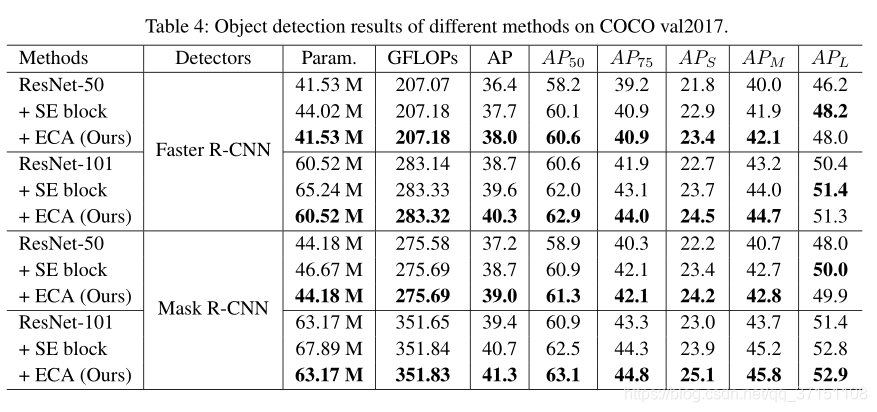
Table IV展示了用Faster R-CNN做检测器的效果,可以看到使用CA带来了0.3%和0.7%的提升,而且实验结果显示出ECA对小型物体的检测效果更佳。
 2.Mask R-CNN
2.Mask R-CNN
使用Mask R-CNN显示出相似的提升,分别在ResNet50和ResNet101中提升了1.8%和1.9%,比SE-block提升了0.3%和0.6%,对小型物体检测效果。
Part C Instance Segmentation
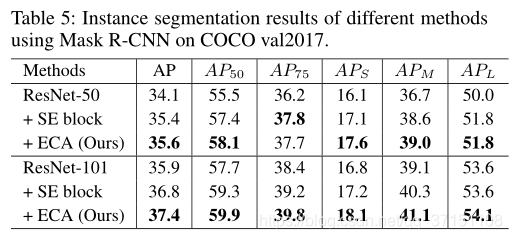
本文最终还测试了ECA Module在实例分割中的提升效果。参见Table V.
Section V Conclusion
本文聚焦于在不增加网络复杂度的前提下有效学习通道注意力,基于此提出了使用快速一维卷积就可实现的ECA Module,可自适应选取合适的k近邻通道完成通道注意力的计算。
实验结果显示ECA是一种超轻量级的注意力提取模块,可方便的插入各种网络框架中提升性能,具有很好的泛化性。
未来,本文预计将ECA Module用于更多网络结构,以及探索与空间注意力模块交互的作用。
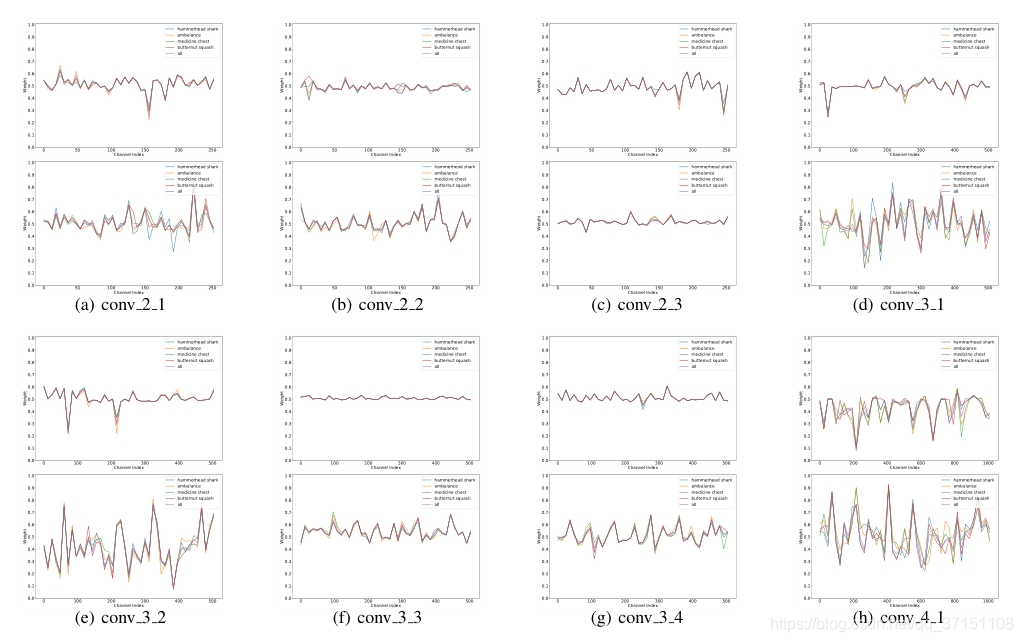
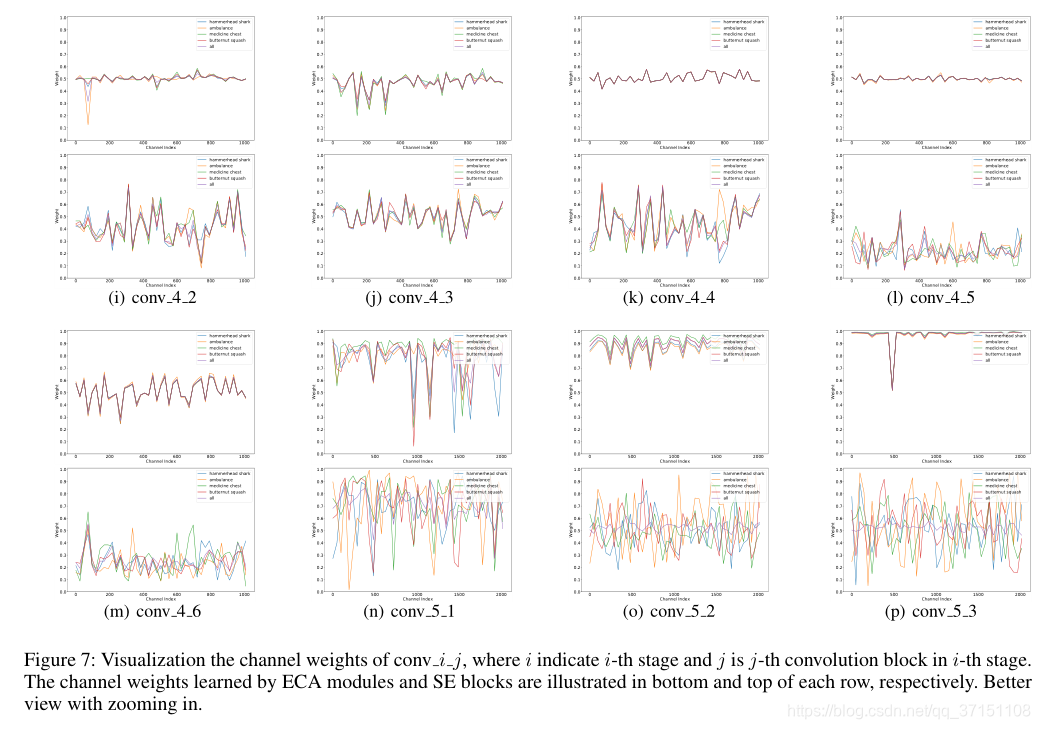
本文还可视化了ECA Module和SE Block不同层的特征提取结果,有以下发现:
(1)在前面的层中,无论ECA还是SE的权重分布都比较相近,可以理解为捕捉的都是基础特征,在所有种类中都比较相近;
(2)SE Block中不同通道之间学到的特征有的比较类似,比如conv4_2-conv4_5;但ECA module可视化的结果显示出几乎不同通道学到的都是不同的特征
(3)越到后面提取的越是高级的语义特征,用于决定类别的,ECA提取的结果比SE 提取的结果,更有助于分类,也就是ECA的区分能力更佳。
这部分是神经网络可解释性的说明。