声明:文中的图来自于可汗学院公开课,若有侵权,联系我删除。
均值:一组数相加后除以这一组数的个数。
中位数:一组数从小到大排列,最中间的那个数,如果是偶数个,两个相加后除以2,得到中位数。
众数:这一组数中出现多的一个数字。
极差:指一组数中最大数和最小数的差值,它描述这些数字分开的有多远, 差值越小,数据分布得越紧密。
中程数:指数据集中最大数和最小数的平均值,是考虑集中趋势的又一种方式,是考虑中间值的有一种方法。
象形统计图的目的主要是为了使统计数据更为直观、通俗易懂。如下图一滴血表示8个人,来统计各种血型的人数。

条形图(利用条形分类来表述数据的一种方式)。下图是五个人的期中、期末成绩,比较谁进步最大。由每个人的前后条形差值中可以得出结论。

线形图适合用来表示随时间变化的事物,展示变化趋势,如下图是股价随着每一个月的变化趋势。

但是要注意
观察线形图趋势,特别是相互比较的时候,要注意刻度,避免被误导,最好是在同一图中画出比较。如下图,不看刻度的话,还以为右图的变化趋势更大。

饼图非常适合用来标志各个部分所占的比例,即部分与整体的关系。例如下图的旅行社每个月份销售额,一眼能看出哪个月份是销售最高的。

茎叶图Stem-and-Leaf plot:将数组中的数按位数进行比较,数的大小基本不变或变化不大的位作为一个主干(茎),将变化大的位的数作为分枝叶),列在主干的后面,这样就可以清楚地看到每个主干后面的几个数,每个数具体是多少。如下图是每个球员的得分。
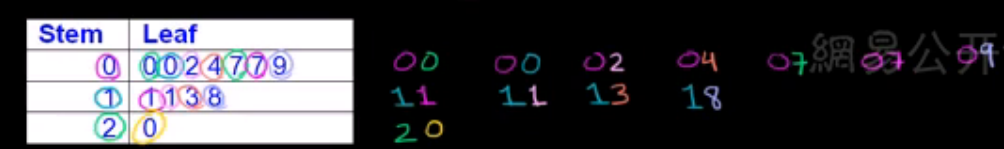
盒须图(box and whiskers):又称为箱形图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。
1.将数组中的数据升序排序
2.求出中位数(Xm),上四分位数(Q1),下四分位数(Q3)
3.画数轴,度量单位大小和数组的单位一致,起点比最小值稍小,长度比该数组的全距稍长
4.画一个矩形盒,两端边的位置分别对应数据批的上下四分位数(Q1和Q3)。在矩形盒内部中位数(Xm)位置画一条线段为中位线。
如下图是箱线图的一个具体示例。

outlier--离群值:与其它数不一样的数,有此数时,中位数和众数比算术平均数更能体现该组数的集中趋势。 如下图100就是离群值。

sample(样本),population(总体)
μ = population mean (总体均值)
X(上面带一条横线)= sample mean(样本均值)

总体方差:知道了集中趋势(平均值),但我们不知道数据是接近集中趋势还是远离集中趋势,所以可以用方差去衡量。如下图是总体方差的计算公式。

样本方差:如果按照总体方差计算的话,当选择的样本偏离总体均值是,样本方差会低估总体方差。如下图所示

故用下图,也就是分母换成(n-1),也称为总体方差的无偏估计

标准差:方差的平方根,平均离中趋势用标准差表示时单位一致。是对数离均值平均远近程度的一种衡量。
方差和期望的关系

随机变量:它并非传统意义上的变量,而更像是从随即过程映射到数值的函数。例如仍骰子的出现点数。

概率密度函数:
1离散随机变量中每个变量概率有值且有意义
2连续随机变量中某个具体变量概率值为0,而一个变量范围内的概率有值且有意义,概率密度是一个函数,用于计算连续变量某一范围空间内的概率。
离散分布:伯努力分布,二项分布,possion分布

1,伯努力分布
import matplotlib.pyplot as plt
from scipy import stats
#执硬币
x_arr=np.array([0,1])
#x为1的概率
p=0.7
#0 1分布
#由PMF生成对应的概率 离散事件
pr_arr=stats.bernoulli.pmf(x_arr,p)
plt.plot(x_arr,pr_arr,marker='o',linestyle='None')
plt.vlines(x_arr,0,pr_arr)
plt.xlabel('Events')
plt.ylabel('Bernoulli distribution(p=0.7)')
plt.show()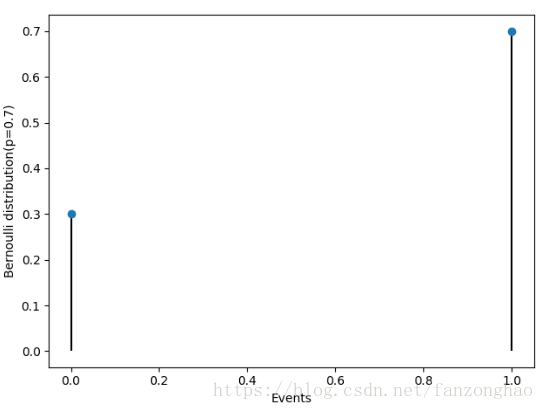
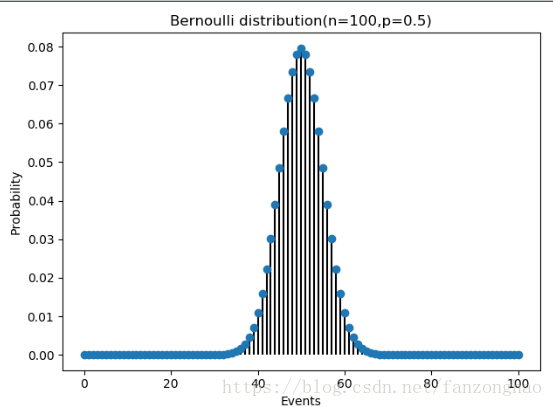
2,二项分布
#二项分布 数量多时:像正态分布
n=100 #实验次数
p=0.5
x_arr=np.arange(0,n+1,1)
pr_arr=stats.binom.pmf(x_arr,n,p)
print(pr_arr)
plt.plot(x_arr,pr_arr,marker='o',linestyle='None')
plt.vlines(x_arr,0,pr_arr)
plt.xlabel('Events')
plt.ylabel('Probability')
plt.title('Bernoulli distribution(n={},p={})'.format(n,p))
plt.show()次数到达100次就像正态分布,可以看出连续情况下可得到正态分布。
期望:随机变量的期望值是总体的均值,但因是无穷,所以采取每个结果可能出现的概率作为权重后计算。
对于二项分布的期望,E(X)=np,其中n是试验次数,p是每次成功的概率。
推导E(X)=np:

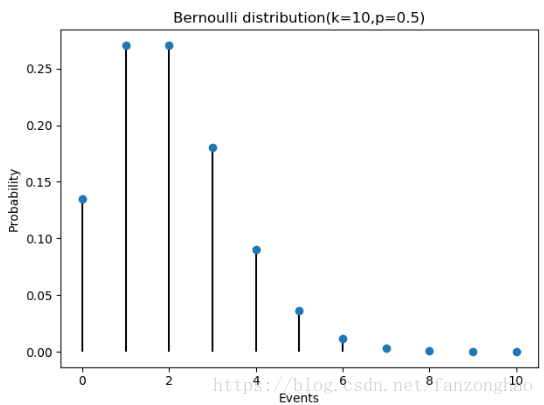
3,poisson分布
假设知道期望值E(X),即一个小时内通过多少辆车,先假设满足二项分布,E(X)=np,p=E(X)/n(n分钟数) 再求k分钟出现车的概率C(n,k)p^k(1-p)^(n-k).不断扩大n到无穷大则是泊松分布,其推导过程如下:

#poisson分布
#求某路口每小时发生k次交通事故的概率,已知每小时平均发生的次数为2
mu=2
k=10
p = 0.5
x_arr=np.arange(0,k+1,1)
pr_arr=stats.poisson.pmf(x_arr,mu)
print(pr_arr)
plt.plot(x_arr,pr_arr,marker='o',linestyle='None')
plt.vlines(x_arr,0,pr_arr)
plt.xlabel('Events')
plt.ylabel('Probability')
plt.title('Bernoulli distribution(k={},p={})'.format(k,p))
plt.show()
#
4,高斯(正态分布)
mu=0#平均值
sigma=1#标准差
x_arr=np.arange(-5,5,0.1)
#概率分布函数
y_arr=stats.norm.pdf(x_arr,mu,sigma)
plt.plot(x_arr,y_arr)
plt.xlabel('x')
plt.ylabel('y')
plt.title('Gaussion distribution(mu={},sigma={})'.format(mu,sigma))
plt.show()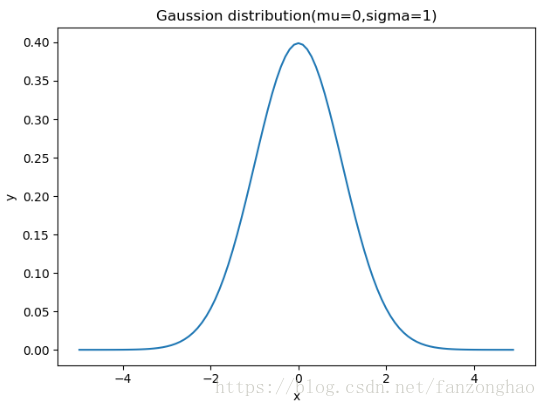
正态曲线下,横轴区间(μ-σ,μ+σ)内的面积为68.268949%。
横轴区间(μ-1.96σ,μ+1.96σ)内的面积为95.449974%。
横轴区间(μ-2.58σ,μ+2.58σ)内的面积为99.730020%。
由于“小概率事件”和“假设检验”的基本思想 “小概率事件”通常指发生的概率小于5%的事件,认为在一次试验中该事件是几乎不可能发生的。由此可见X落在(μ-3σ,μ+3σ)以外的概率小于千分之三,在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。
大数定理:如果样本量足够大,那么样本均值将趋近于期望值。