综述
本文总结了机器学习中经常遇到的概率统计中的一些基础概念,在平时经常遇到写下来供自己以后查阅。
清单
样本均值
数学期望
期望
方差
样本方差
协方差
最大似然与最大后验
共轭先验
偏差和方差
样本均值
现在我们拿到了 个样本,每个样本的观测值为 则样本均值指的是 ,也就是求n个观测值的平均值。
数学期望
数学期望就是样本均值,因为我们不知道拿到多少样本,所以数学期望的值是不确定的。
期望
针对一个事件不管他的样本数量多少,我们认为它的期望是个固定值。可以通过以下方式得到:
方差
方差的计算公式为:
样本方差
首先上样本方差的计算公式:
所以才有了当分母为 的时候,对方差做一个无偏估计;当分母为 时,对方差做一个极大似然估计。
偏差和方差
前文刚刚引入了偏差的概念,趁热打铁,在这里接着把偏差和方差理论写了吧。
同样偏差和方差本来是统计学里面的概念,这里主要用来分析机器学习中的算法。当然更详尽的还是要移步博客:理解机器学习中的偏差与方差。在拜读PRML的书,方差偏差的推导看的不是很明白,但博客已经说的很清楚了咯。
学习算法的泛化误差可以分成三个部分:偏差、方差和噪声。在衡量学习算法性能时主要关注于偏差和方差。因为噪声一直存在不可约减。接下来看一下什么是它们是什么以及怎么影响算法的泛化能力的。
偏差的意思就是偏离真实情况的程度,比如分类任务中真实情况就是这个类别的真实标签。刻画了学习算法本身对数据空间的拟合能力。方差本身描述的就是一种离散程度,在机器学习中表述为随机变量在期望值附近的波动程度。刻画了数据扰动对算法性能造成的影响的大小。通过下面两张图可以很好地阐述清楚两者的关系。
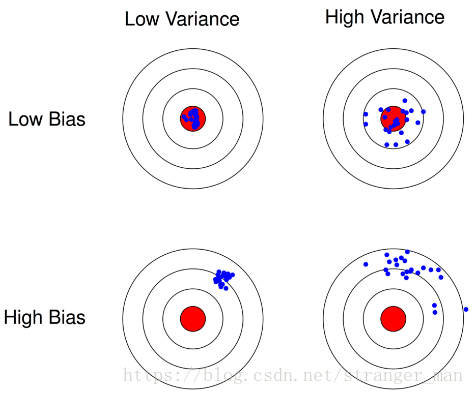
自然希望我们学习的模型偏差方差都要小一点,但是在真实的情况下偏差方差调节是有冲突的。1、给定一个学习任务, 在训练初期, 由于训练不足, 学习器的拟合能力不够强, 偏差比较大, 也是由于拟合能力不强, 数据集的扰动也无法使学习器产生显著变化, 也就是欠拟合的情况;2、随着训练程度的加深, 学习器的拟合能力逐渐增强, 训练数据的扰动也能够渐渐被学习器学到;3、充分训练后, 学习器的拟合能力已非常强, 训练数据的轻微扰动都会导致学习器发生显著变化, 当训练数据自身的、非全局的特性被学习器学到了, 则将发生过拟合.
协方差
前文讲述方差的概念,为什么又要提出协方差呢?前文中所述的方差考察的是数据在平行特征空间轴方向的数据传播。如果我们想要考察其它方向呢?这就需要用到协方差了,同样的协方差的几何解释国外的大神,他的文章特别棒。已经阐述的及其详细了,给出一篇译文。
协方差矩阵可以很好的刻画数据在各个方向上的传播情况,通过矩阵的分解,还可以通过特征值特征向量的方法来将数据传播的方向和力度刻画出来。
最大似然和最大后验
大家学习机器学习第一次接触这个概念就是线性回归的算法吧。自己刚开始的时候一头雾水。PRML中第一次提到似然函数还是刚刚引入贝叶斯定理。提到这里索性一次把这里面的概念都解释清楚吧。
先验概率
从字面解释就是在我们进行这次概率推算活动之前就存在的概率。也就是说我们根据已经发生的一些知识推算出来的一个概率。后验概率
同理,后验概率就是我们已经进行概率推算的结果,拿到这个结果去估计产生这个现象的原因的概率叫做后验概率。
似然估计
一件事情可能有多种可能,通过可能估计结果的方式是可行的。
接下来就要上主菜了贝叶斯公式:
贝叶斯公式对应位置的子项含义分别是:
接下来我们从似然估计这个概念说起。起初对这个问题存在疑点有两个:1、为啥似然函数用来估计参数呢?2、为啥似然函数与似然概率想given的东西是相反的呢?
什么是似然性?在统计学中,概率与似然性有着明确的区分。概率用于在已知一些参数的情况下,预测接下来的观测所得到的结果,而似然性则是用于在已知某些观测所得到的结果时,对有关事物的性质的参数进行估计。所以,在一定程度上可以把似然函数理解成条件概率的逆反。但是观察这两个表达式:
发现其中项颠倒了,似然概率和似然函数有什么不同呢?其实并没有什么不同,想仔细了解的可以查看维基百科的例子。其实简单一想,似然不也是一种概率吗? 我们可以写成 通过条件概率公式: 其中, 表示已经发生的概率为1。 这样计算很容易了。也就是可以得到L=P。所以最大似然概率的含义就是,在已知观测的数据的前提下,找到使得似然函数概率最大的参数值。似然函数关注的不是函数值,而是每次参数更改时产生的变化。引最大后验
说清楚似然估计这个MAP就简单了,就是在似然函数后面乘上个先验,组成贝叶斯即可。共轭先验
这个概念第一次接触于PRML书中,一看“共轭”两个字挺吓人的。轭分布就是先验概率和后验概率具有一样函数形式的分布形式,一样的函数形式的含义举个例子就是假如先验分布函数是形如
的形式(比如二项分布就是这种形式)而后验分布是
这样的形式,两者只是具体参数值不同,或者先验分布和后验分布都是高斯分布等等的情形就可为认为先验分布和后验分布具有同样的形式,这时两者就共轭。因为后验概率正比于先验概率与似然函数的乘积,因此似然函数是有可能改变后验概率的形式的。例如的先验假如乘上的是
形式的似然函数,那么它的后验函数的形式肯定就发生了变化,这时先验和后验就不是共轭的了,而假如
的先验乘上的是
(比如贝塔分布,伽马函数是用来求非整数的阶乘的)的形式,那么最后后验函数的形式就可以和先验函数保持一致了。
那么共轭先验又是什么概念呢?因为在现实建模问题中,往往我们先得到和固定的反而是似然函数(其实也很好理解,客观的实验观察数据才是第一手最solid的材料),这时先验函数(可以理解为先验知识或者是对后验分布的一种假设和猜测)是可以选择的。这时如果我选的先验分布最后乘上这个似然函数,使得后验分布与先验分布共轭,那么我们就称这个先验函数为似然函数的共轭先验。很明显的,后验分布和先验分布共轭的情况下是可以大大简化计算量的。所以在确定似然函数后寻找先验分布时在该似然函数的共轭先验中寻找是比较好的一种选择。