图像风格迁移即把图像A的风格和图像B的内容按照一定比例结合,输出具备图像A风格和图像B内容的图像C.
[github传送门1]https://github.com/anishathalye/neural-style
[github传送门2]https://github.com/Quanfita/Neural-Style/tree/master/examples
1 迁移原理
图像风格迁移包括:
- 图像内容获取;
- 图像风格提取;
- 内容和风格融合;
使用VGGNet神经网络,分别从原始图片A(风格)和原始图片B(内容)直接提取特征,然后使用梯度下降法,计算风格和内容损失值,获取最优的输出结果.
迁移框架:

图1.0 迁移原理图
2 获取图像内容
图形内容获取即图像特征提取,目前较成熟的特征提取非卷积神经网络莫属,图像风格迁移使用VGGNet提取图像特征.原始图像使用VGG处理,图像特征值可从每一层提取VGGNet抽取图像特征,输出内容分类.
看图说话:VGGNet 16层模型为例.
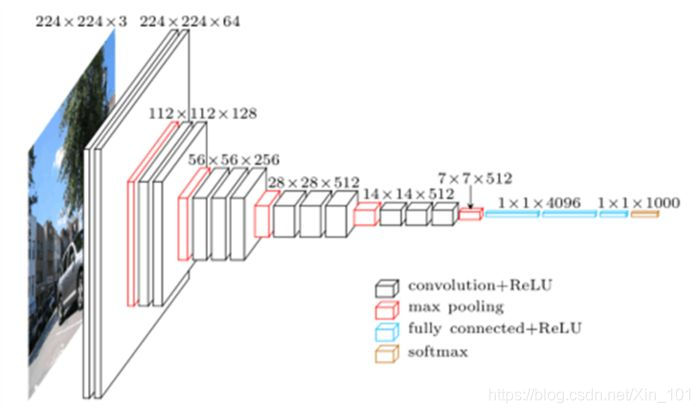 图2.0 VGG16模型
图2.0 VGG16模型
VGGnet浅层网络提取检测点,线,亮度等较简单的特征,还原图像效果较好,特征值基本保留了原始图像内容的形状,位置,颜色和纹理等信息,深层网络提取较为复杂的特征,如物体轮廓,即图像中物体的形状和位置,但是丢失了部分颜色和纹理信息.
因此,提取图像内容使用VGGNet浅层计算的特征值,通过提取的特征值还原内容图.
还原方法:梯度下降法,即利用梯度下降计算内容损失函数.
| 序号 |
变量 |
说明 |
| 1 |
p
|
原始图像 |
| 2 |
x
|
生成图像 |
| 3 |
l |
卷积层数 |
| 4 |
Pijl |
原始图像
p
在第
l层卷积上的"原始"特征值,即每一个卷积层的输入,还未进行卷积计算,
i为卷积的第i个通道,
j表示卷积的第
j个位置,通常卷积的值为三维arrary(height, width, channel),若将图片拉伸成一个向量,则对应
i为channel,
j为height
×width |
| 4 |
Fijl |
原始图像
p
在第
l层卷积上经过卷积核filter计算出的特征值,
i为卷积的第i个通道,
j表示卷积的第
j个位置,通常卷积的值为三维arrary(height, width, channel),若将图片拉伸成一个向量,则对应
i为channel,
j为height
×width |
| 5 |
Lcontent(p
,x
,l) |
内容损失函数 |
内容损失为:
Losscontent(p
,x
,l)=21i,j∑(Fijl−Pijl)2
结果:
-
Losscontent(p
,x
,l)越小,生成图像与原始图像内容越接近;
-
Losscontent(p
,x
,l)越大,生成图像与原始图像内容差别越大;
3 获取图像风格
图形风格使用卷积层特征值的格拉姆(Gram)矩阵表示.
Gram矩阵:
n维欧式空间任意
k(
k≤n)个向量,
α1
,α2
,⋯,αk
内积组成的矩阵:
Δ(α1
,α2
,⋯,αk
)=⎣⎢⎢⎢⎡(α1
,α1
)(α2
,α1
)⋮(αk
,α1
)(α1
,α2
)(α2
,α2
)⋮(αk
,α2
)⋯⋯⋱⋯(α1
,αk
)(α2
,αk
)⋮(αk
,αk
)⎦⎥⎥⎥⎤
即为
k个向量
α1
,α2
,⋯,αk
的格拉姆矩阵.
矩阵内积:行向量乘以列向量,结果是一个数,也称点积,表示为:
(α1
,α2
)=α1
Tα2
| 序号 |
变量 |
说明 |
| 1 |
p
|
原始图像 |
| 2 |
x
|
生成图像 |
| 3 |
l |
卷积层数 |
| 4 |
Aijl |
原始图像
p
在第
l层卷积上的"原始"Gram矩阵,即每一个卷积层的输入,还未进行卷积计算,
i为卷积的第i个通道,
j表示卷积的第
j个位置,通常卷积的值为三维arrary(height, width, channel),若将图片拉伸成一个向量,则对应
i为channel,
j为height
×width |
| 5 |
Gijl |
原始图像
p
在第
l层卷积上经过卷积核filter计算出的Gram矩阵,
i为卷积的第i个通道,
j表示卷积的第
j个位置,通常卷积的值为三维arrary(height, width, channel),若将图片拉伸成一个向量,则对应
i为channel,
j为height
×width |
| 6 |
Lcontent(p
,x
,l) |
内容损失函数 |
| 7 |
Nl |
第
l层卷积通道数,
1≤i≤Nl |
| 8 |
Ml |
第
l层卷积图像尺寸
Ml=height×width,
1≤j≤Ml |
Gram矩阵元素:
Gi,jl=k∑FiklFjkl
其中,
Fil=(Fi1l,Fi2l,⋯,Fijl,⋯,FiMll)
Gram矩阵在一定程度上可以反应原始图像的"风格",风格损失函数为
Lossstyle(p
,x
,l)
内容损失为:
Lossstyle(p
,x
,l)=4Nl2Ml21i,j∑(Aijl−Fijl)2
其中,
4Nl2Ml21是归一化项,防止风格损失比内容损失过大.实际应用,有多层风格损失,加权值作为风格损失,即:
Lossstyle(p
,x
)=l∑wlLossstyle(p
,x
,l)
其中,
wl为第l层卷积的权重.
结果:
-
Lcontent(p
,x
,l)越小,生成图像风格与原始图像风格越接近;
-
Lcontent(p
,x
,l)越大,生成图像风格与原始图像风格差别越大;
3 内容和风格融合
将图像A的内容和图像B的风格相融合,即可获取图像C,C包含A的内容和B的风格.融合损失函数:
Losstotal(p
,a
,x
)=αLosscontent(p
,x
)+βLossstyle(a
,x
)
其中,
α,β是平衡内容损失和风格损失的超参数,如果
α偏大,还原的图像包含的内容较多,
β偏大,还原的图像包含风格较多.
4 结果
迁移结果.
 图4.0 迁移结果
图4.0 迁移结果
- 图A为原始内容图形,图B~F中左下角图为风格图,大图为转换结果,该模型可完成风格迁移;
5 总结
- 该方法效果良好,由于每次进行转换都是从原始图形进行计算,所以转换效率大打折扣.
- 致命缺点是转换速度慢,CPU上训练,生成一张图片需要10分钟至几个小时不等,GPU上训练,输出一张结果也需要几分钟.
- 开山鼻祖,不适合生产使用.
[参考文献]
[1]A Neural Algorithm of Artistic Style
[2]Very Deep Convolutional Networks for Large-Scale Image Recognition
[3]https://blog.csdn.net/czp_374/article/details/81185603
[4]https://blog.csdn.net/juanjuan1314/article/details/79731457