目录
在上篇文章我们介绍了图像普通风格迁移方法,但是程序训练时间十分漫长。本节介绍使用PyTorch对固定风格任意内容的快速风格迁移进行建模。该模型根据下图所示的网络及训练过程进行建模,但略有改动,主要对图像转换网络的上采样操作进行相应的调整。在下面建立的网络中,将会使用转置卷积操作进行特征映射的上采样。
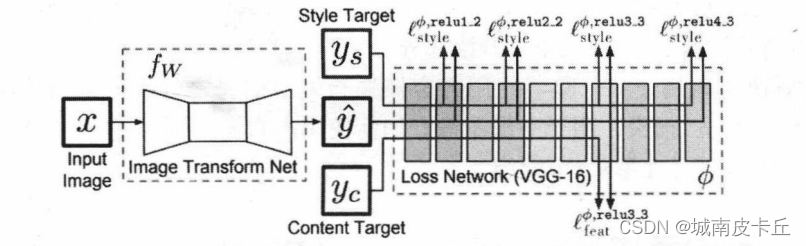
快速风格迁移的网络结构,会通过3个卷积层对图像的特征映射进行降维操作,然后通过5个残差连接层,学习图像的风格,并添加到内容图像上,最后通过3个转置卷积操作,对特征映射进行升维,以重构风格迁移后的图像。下面给出需要图像转换网络的结构,下表所示:

需要注意的是,在转换网络的升维操作中,使用转置卷积来代替原论文中的上采样和卷积层的结合,因为输入的是标准化后的图像,像素值范围在-2.1~2.7之间,所以在网络最后的输出层中,不使用激活函数,网络的输出值大多数会在-2.1~2.7之间,只有少部分不在该区间,故在实际训练网络时,会将输出裁剪到-2.1~2.7之间,即最后一层无须使用激活函数,而且其他层的激活函数均为ReLU函数。在网络中,特征映射的数量逐渐从3增加到128,并且每个残差连接层有128个特征映射,在转置卷积层特征映射的数量会从128减少到3,对应着图像的三个通道。在网络中会适当地使用nn.ReflectionPad2d()层进行边界反射填充,以及使用nn.InstanceNorm2d()层在像素上对图像进行归一化处理。

1.定义残差块结构
针对网络中的残差连接,可以单独定义为一个残差连接类ResidualBlock,以便在搭建转换网络时,可以减少重复性代码,程序如下所示:
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.conv=nn.Sequential(
nn.Conv2d(channels,channels,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(channels,channels,kernel_size=3,stride=1,padding=1)
)
def forward(self,x):
return F.relu(self.conv(x)+x)
在定义残差连接时,其中conv模块包括两个卷积层和一个ReLU()激活函数层,并且在forward()函数中,要使用F.relu()表示ReLU激活函数输出self.conv(x)和输入x的和。
2.定义图像转换网络
图像转换网络ImfwNet主要包括三个模块,分别是下采样模块downsample、5个残差连接模块res_blocks以及上采样模块unsample,定义该网络的程序如下所示:
class ImfwNet(nn.Module):
def __init__(self):
super(ImfwNet, self).__init__()
self.downsample=nn.Sequential(
nn.ReflectionPad2d(padding=4),#使用边界反射填充
nn.Conv2d(3,32,kernel_size=9,stride=1),
nn.InstanceNorm2d(32,affine=True),#在像素上做归一化
nn.ReLU(),#3*256*256->32*256*256
nn.ReflectionPad2d(padding=1),#
nn.Conv2d(32,64,kernel_size=3,stride=2),
nn.InstanceNorm2d(64,affine=True),
nn.ReLU(),#32*256*256->64*128*128
nn.ReflectionPad2d(padding=1),
nn.Conv2d(64,128,kernel_size=3,stride=2),
nn.InstanceNorm2d(128,affine=True),
nn.ReLU()#64*128*128->128*64*64
)
self.res_blocks=nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
)
self.unsample=nn.Sequential(
nn.ConvTranspose2d(128,64,kernel_size=3,stride=2,padding=1,output_padding=1),
nn.InstanceNorm2d(64,affine=True),
nn.ReLU(),#128*64*64->64*128*128
nn.ConvTranspose2d(64,32,kernel_size=3,stride=2,padding=1,output_padding=1),
nn.InstanceNorm2d(32,affine=True),
nn.ReLU(),#64*128*128->32*256*256
nn.ConvTranspose2d(32,3,kernel_size=9,stride=1,padding=4)
#32*256*256->3*256*256
)
def forward(self,x):
x=self.downsample(x),#输入像素值在-2.1~2.7之间
x=self.res_blocks(x),
x=self.unsample(x)#输出像素值在-2.1~2.7之间
return x在上面的程序中主要使用了以下几个层的操作方法:
(1)nn.ReflectionPad2d():使用边界反射填充完成图像的padding操作。
(2)nn.Conv2d():图像的二维卷积操作。
(3)nn.InstanceNorm2d():在图像像素值上做归一化,完成特征映射的归一化。
(4) ResidualBlock():完成残差连接单元所做的操作。
(5)nn.ReLU():完成ReLU激活函数的操作。
(6)nn.ConvTranspose2d():图像的二维转置卷积操作,可对特征映射进行上采样。
在使用ImfwNet()类初始化训练网络时,需要使用“.to(device)”方法,将其设置到相应的GPU计算设备上
device=torch.device("cuda")
fwnet=ImfwNet().to(device)
print(fwnet)
3.快速风格迁移数据准备
COCO数据集是由微软发布的大型图像数据集,专为目标检测、分割、人体关键点检测、语义分割和字幕生成而设计。COCO数据集主页为http://mscoco.org。为了加快训练速度,节省训练所需的时间和空间,此处只使用COCO 2014数据集,该数据集有超过40000张图像。通过实验,经多轮训练后,可以达到较好的图像风格迁移效果(论文Perceptual Losses for Real-Time Style Transfer and Super-Resolution中使用了COCO 2014的训练集、验证集和测试集,共约16万张图像,图像数量巨大,需要耗费大量的空间,此处仅使用一个验证数据集进行训练)。
因为转化网络fwnet需要接受标准化的数据,并且要求图像的尺寸为256×256 ,所以下面将定义对数据集进行转换的过程,程序如下:
data_transform=transforms.Compose(
transforms.Resize(256),
transforms.CenterCrop(256),#每张图像的尺寸为256*256
transforms.ToTensor(),#像素值转化到0-1
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
#像素值转化到-2.1-2.7
)定义好图像的预处理的转换操作后,下面通过ImageFolder()函数从文件夹中读取数据,然后通过Data.DataLoader()函数将数据处理为数据加载器。
dataset=ImageFolder(r"",transform=data_transform)
data_loader=Data.DataLoader(dataset,batch_size=4,
shuffle=True,num_workers=0,pin_memory=True)在上面的程序中,使用数据加载器Data.DataLoader()函数时,使用了参数pin_memory=True,该参数表示创建DataLoader时,生成的Tensor数据最开始是属于内存中的锁页内存(显卡中的显存全部是锁页内存),这样将内存的Tensor转移到GPU的显存就会更快一些,并且针对高性能的GPU运算速度会更快。
在准备好使用的数据后,下面需要读取已经预训练的VGG16网络,针对该网络只需要使用其中的features包含的层,将其设置到已经定义好的GPU设备上。在计算时只需要使用VGG网络提取特定层的特征映射,不需要对其中的参数进行训练,将其格式设置为eval()格式即可,完成这些任务的程序如下所示:
vgg16=models.vgg16(pretarined=True)
vgg=vgg16.features.to(device).eval()为了读取一张用于读取风格图像的图像,并将其转化为Vgg网络可使用的四维张量的形式,需要定义一个load_image()函数:
def load_image(im_path,shape=None):
image=Image.open(im_path),
size=image.size
#如果指定了图像的尺寸,就将图像转化为shape指定的尺寸
if shape is not None:
size=shape
#使用transforms将图像转化为张量,并进行标准化
in_transform=transforms.Compose([
transforms.Resize(size),#图像尺寸变换
transforms.ToTensor(),#数组转换为张量
#图像标准化
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
])
#使用图像的RGB通道,并且添加batch维度
image=in_transform(image)[:3,:,:].unsqueeze(dim=0)
return image
该函数可以用于读取风格图像,并将其转化为需要的尺寸大小。接下来定义一个将load_image()函数读取得到的图像数据转化为方便可视化的函数im_convert(),程序如下所示:
def im_convert(tensor):
"""
将[1,c,h,w]维度的张量转化为[h,w,c]的数组
因为张量进行表转化,所以要进行标准化处理
:param tensor:
:return:
"""
tensor=tensor.cpu()#将数据转化为cpu数据
image=tensor.data.numpy().squeeze()#去除batch维度的数据
image=image.transpose(1,2,0)#置换数组的维度[c,h,w]->[h,w,c]
#进行标准化的逆操作
image=image * np.array((0.229,0.224,0.225))+np.array((0.485,0.456,0.406))
image=image.clip(0,1)
return image在im_convert()函数中需要注意的是,因为其输入张量是基于GPU计算的,所以在将其转化为Numpy数组之前,需要使用tensor.cpu()方法将张量转化为基于CPU计算的张量,然后再转化为数组。
4.网络训练
在训练快速风格迁移网络之前,需要先计算出风格图像经过VGG16网络的相应层后代表图像风格的Gram矩阵。这里定义gram_matrix()函数,用于计算输入张量的Gram矩阵,程序如下所示:
def gram_matrix(tensor):
"""
指定向量的gram matrix,该矩阵表示了图像的风格特征,
tensor是一张图像前向计算后的一层特征映射
:param tensor:
:return:
"""
#获取tensor的batch_size,channel,height,width
b,c,h,w=tensor.size()
#改变矩阵的维度为(深度,高*宽)
tensor=tensor.view(b,c,h*w)
tensor_t=tensor.transpose(1,2)
#计算gram,针对多张图像进行计算
gram=tensor.bmm(tensor_t)/(c*h*w)
return gram在上述程序中需要注意的是,因输入的数据使用一个batch的特征映射,所以在张量乘以其转置时,需要计算每张图像的Gram矩阵,故使用tensor.bmm()方法完成相关的矩阵乘法计算。为了更方便地获取图像数据在指定网络指定层上的特征映射,定义get_features()函数。
def get_features(image,model,layers=None):
"""
将一张图像image在一个网络model中进行前向传播计算,并获取指定层layers中的特征输出
:param image:
:param model:
:param layers:
:return:
"""
#layers参数指定:需要用于图像内容和样式表示的图层
#如果layers没有指定,就用默认的层
if layers is None:
layers={
'3':'relu1_2',
'8':'relu2_2',
'15':'relu3_3',#内容图层的表示
'22':'relu4_3'#经过relu激活后的输出
}
features={}#获取的每层特征保存到字典中
x=image#需要获取特征的图像
for name,layer in model._modules.items():
# 从第一层开始获取图像的特征
x=layer(x)
#如果是layers参数指定的特征,那就保存到features中
if name in layers:
features[layers[name]]=x
return features在使用VGG网络获取图像的内容表示和风格表示时,使用经过ReLU激活函数层后的层输出,即针对描述图像风格的特征映射,分别使用3、8、15、22四个层,分别表示relu1_2、relu2_2、relu3_3和relu4_3层,其中relu3_3层输出的特征映射也用于度量图像的内容相似性。下面计算风格图像的4个指定多层上的Gram矩阵,并使用字典来保存。
#计算图像的风格表示
style_layer={
'3':'relu1_2',
'8':'relu2_2',
'15':'relu3_3',
'22':'relu4_3'
}
content_layer={
'15':'relu3_3'
}
#内容表示的图层,均使用经过relu激活后的输出
style_features=get_features(style,vgg,layers=style_layer)
#为我们的风格表示计算每层的拉格姆矩阵,使用字典保存
style_grams={layer:gram_matrix(style_features[layer]) for layer in style_features}
计算得到的风格图像Gram矩阵保存在style_grams字典中,并且风格图像的Gram矩阵只需计算一次即可。在上述准备工作完毕后,开始使用数据对网络进行训练。在训练过程中定义了三种损失,分别为风格损失、内容损失和全变分(Total Variation)损失,它们的权重为 、1和
,使用的优化器为Adam,且学习率为0.0003。针对4万多张图像数据,每4张图像为一个batch,共训练4个epoch,大约会有40000次迭代,其网络的训练程序如下所示:
#网络训练,定义三种损失的权重
style_weight=1e5
content_weight=1
tv_weight=1e-5
#定义优化器
optimizer=optim.Adam(fwnet.parameters(),lr=1e-3)
fwnet.train()
since=time.time()
for epoch in range(4):
print("Epoch : {}".format(epoch+1))
content_loss_all=[]
style_loss_all=[]
tv_loss_all=[]
all_loss=[]
for step,batch in enumerate(data_loader):
optimizer.zero_grad()
#计算内容图像使用图像转换网络得到的输出
content_images=batch[0].to(device)
transformed_images=fwnet(content_images)
transformed_images=transformed_images.clamp(-2.1,2.7)
#使用VGG16计算特征
content_features=get_features(content_images,vgg,layers=content_layer)
#计算y_hat图像对应的vgg特征
transformed_features=get_features(transformed_images,vgg)
#内容损失,使用F.mse_loss
content_loss=F.mse_loss(transformed_features['relu3_3'],content_features['relu3_3'])
content_loss=content_weight * content_loss
#total varition图像水平和垂直平移一个像素,原图相减
#然后计算绝对值的和
y=transformed_images
tv_loss=(torch.sum(torch.abs(y[:,:,:,:-1]-y[:,:,:,1:]))+torch.sum(torch.abs(y[:,:,:-1,:]-y[:,:,1:,:])))
tv_loss=tv_weight * tv_loss
#风格损失
style_loss=0.
transformed_grams={layer:gram_matrix(transformed_features[layer]) for layer in transformed_features}
for layer in style_grams:
transformed_gram=transformed_grams[layer]
style_gram=style_grams[layer]
style_loss+=F.mse_loss(transformed_gram,style_gram.expand_as(transformed_gram))
style_loss=style_weight*style_loss
#3个损失相加
loss=style_loss+content_loss+tv_loss
loss.backward(retain_graph=True)
optimizer.step()
#统计各损失的变化情况
content_loss_all.append(content_loss.item())
style_loss_all.append(style_loss.item())
tv_loss_all.append(tv_loss.item())
all_loss.append(loss.item())
if step % 5000==0:
print("step:{};content loss:{:.3f};style loss:{:.3f};tv loss:{:.3f};loss:{:.3f}".format(step,content_loss.item(),style_loss.item(),tv_loss.item(),loss.item()))
# print('step:{};content loss:{:.3f}; style loss:{:.3f};tv loss:{:.3f},loss:{:.3f}'.format(step,content_loss.item(),style_loss.item(),tv_loss.item(),loss.item()))
time_use=time.time()-since
print("Train complete in{:.0f}m {:.0f}s".format(time_use//60,time_use%60))
plt.figure()
im=transformed_images[1,...]
plt.imshow(im_convert(im))
plt.show()
torch.save(fwnet.state_dict(),"C:\\Users\\zex\\Desktop\\imfwnet_dict.pkl")
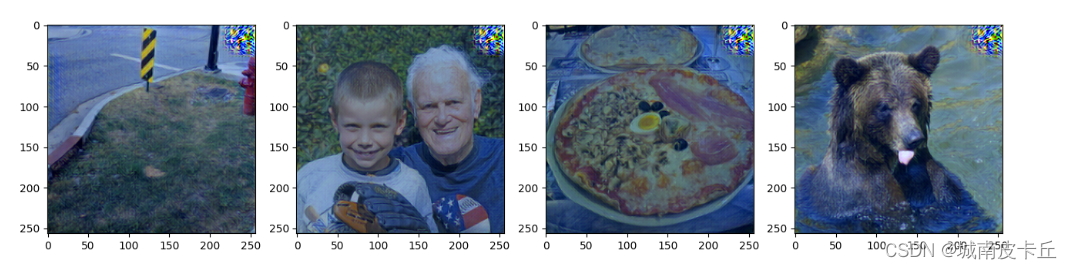
在上面的程序中,总的损失是三种损失的和,并且训练过程中,每经过5000次迭代输出一次当前迭代的内容损失大小、风格损失大小、全变分损失大小以及总的损失大小,并输出当前batch的4张图像,索引为1图像的风格迁移后图像结果用于监督网络的训练效果,训练过程中输出的效果如下所示:
Epoch : 1
step:0;content loss:26.599;style loss:667.969;tv loss:16.453;loss:711.022
Train complete in0m 0s
step:5000;content loss:12.698;style loss:3.671;tv loss:2.062;loss:18.430
Train complete in17m 25s
step:10000;content loss:9.202;style loss:2.275;tv loss:2.009;loss:13.486
Train complete in34m 59s
Epoch : 2
step:0;content loss:9.820;style loss:2.917;tv loss:1.994;loss:14.730
Train complete in35m 25s
step:5000;content loss:5.495;style loss:3.488;tv loss:1.831;loss:10.814
Train complete in52m 33s
step:10000;content loss:5.674;style loss:2.624;tv loss:2.086;loss:10.384
Train complete in69m 40s
Epoch : 3
step:0;content loss:4.837;style loss:3.202;tv loss:1.971;loss:10.011
Train complete in70m 7s
step:5000;content loss:5.104;style loss:3.436;tv loss:1.835;loss:10.375
Train complete in87m 19s
step:10000;content loss:5.221;style loss:3.106;tv loss:1.861;loss:10.188
Train complete in135m 59s
Epoch : 4
step:0;content loss:5.827;style loss:2.899;tv loss:1.831;loss:10.557
Train complete in136m 25s
step:5000;content loss:4.200;style loss:3.144;tv loss:1.892;loss:9.236
Train complete in155m 5s
step:10000;content loss:4.498;style loss:2.887;tv loss:1.797;loss:9.183
Train complete in172m 9s
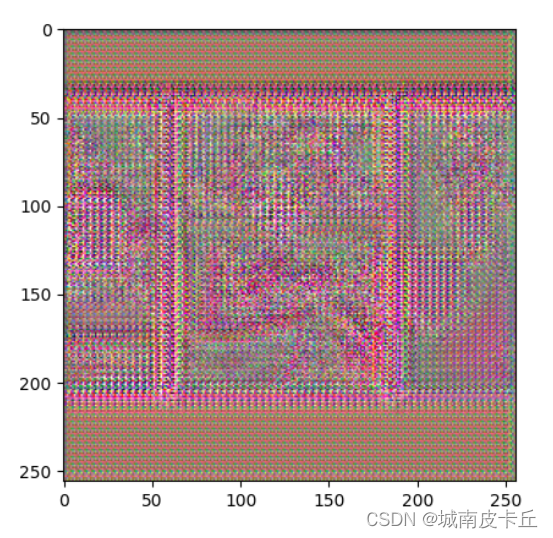
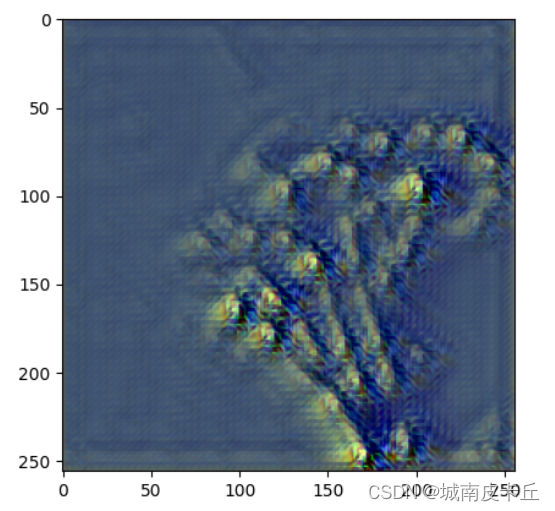

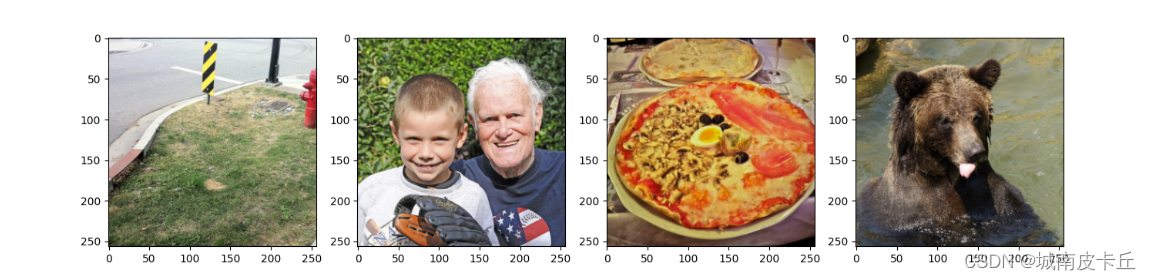
为了测试训练得到的风格迁移网络fwnet,下面随机获取数据集中的一个batch的图像,进行图像风格迁移,程序如下所示:
fwnet.eval()
for step,batch in enumerate(data_loader):
content_images=batch[0].to(device)
if step>0:
break
plt.figure(figsize=(16,4))
for i in range(4):
im=content_images[i,...]
plt.subplot(1,4,i+1)
plt.imshow(im_convert(im))
plt.show()
transformed_images=fwnet(content_images)
transformed_images=transformed_images.clamp(-2.1,2.7)
plt.figure(figsize=(16,4))
for i in range(4):
im=im_convert(transformed_images[i,...])
plt.subplot(1,4,i+1)
plt.imshow(im)
plt.show()
本案例的完整代码
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import time
import torch.utils.data as Data
import torch.optim as optim
from torchvision import models
from torchvision.datasets import ImageFolder
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlock, self).__init__()
self.conv=nn.Sequential(
nn.Conv2d(channels,channels,kernel_size=3,stride=1,padding=1),
nn.ReLU(),
nn.Conv2d(channels,channels,kernel_size=3,stride=1,padding=1)
)
def forward(self,x):
return F.relu(self.conv(x) + x)
# 定义图像转换网络
class ImfwNet(nn.Module):
def __init__(self):
super(ImfwNet, self).__init__()
self.downsample=nn.Sequential(
nn.ReflectionPad2d(padding=4),#使用边界反射填充
nn.Conv2d(3,32,kernel_size=9,stride=1),
nn.InstanceNorm2d(32,affine=True),#在像素上做归一化
nn.ReLU(),#3*256*256->32*256*256
nn.ReflectionPad2d(padding=1),#
nn.Conv2d(32,64,kernel_size=3,stride=2),
nn.InstanceNorm2d(64,affine=True),
nn.ReLU(),#32*256*256->64*128*128
nn.ReflectionPad2d(padding=1),
nn.Conv2d(64,128,kernel_size=3,stride=2),
nn.InstanceNorm2d(128,affine=True),
nn.ReLU(),#64*128*128->128*64*64
)
self.res_blocks=nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
)
self.unsample=nn.Sequential(
nn.ConvTranspose2d(128,64,kernel_size=3,stride=2,padding=1,output_padding=1),
nn.InstanceNorm2d(64,affine=True),
nn.ReLU(),#128*64*64->64*128*128
nn.ConvTranspose2d(64,32,kernel_size=3,stride=2,padding=1,output_padding=1),
nn.InstanceNorm2d(32,affine=True),
nn.ReLU(),#64*128*128->32*256*256
nn.ConvTranspose2d(32,3,kernel_size=9,stride=1,padding=4)
#32*256*256->3*256*256
)
def forward(self,x):
x=self.downsample(x)#输入像素值在-2.1~2.7之间
x=self.res_blocks(x)
x=self.unsample(x)#输出像素值在-2.1~2.7之间
return x
device=torch.device("cuda")
fwnet=ImfwNet().to(device)
data_transform=transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(256),#每张图像的尺寸为256*256
transforms.ToTensor(),#像素值转化到0-1
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
#像素值转化到-2.1-2.7
])
dataset=ImageFolder(r"C:\Users\zex\Downloads\val2014",transform=data_transform)
data_loader=Data.DataLoader(dataset,batch_size=4,shuffle=True,num_workers=0,pin_memory=True)
vgg16=models.vgg16(pretrained=True)
vgg=vgg16.features.to(device).eval()
def load_image(im_path,shape=None):
image=Image.open(im_path)
size=image.size
#如果指定了图像的尺寸,就将图像转化为shape指定的尺寸
if shape is not None:
size=shape
#使用transforms将图像转化为张量,并进行标准化
in_transform=transforms.Compose([
transforms.Resize(size),#图像尺寸变换
transforms.ToTensor(),#数组转换为张量
#图像标准化
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
])
#使用图像的RGB通道,并且添加batch维度
image=in_transform(image)[:3,:,:].unsqueeze(dim=0)
return image
def im_convert(tensor):
"""
将[1,c,h,w]维度的张量转化为[h,w,c]的数组
因为张量进行表转化,所以要进行标准化处理
:param tensor:
:return:
"""
tensor=tensor.cpu()#将数据转化为cpu数据
image=tensor.data.numpy().squeeze()#去除batch维度的数据
image=image.transpose(1,2,0)#置换数组的维度[c,h,w]->[h,w,c]
#进行标准化的逆操作
image=image * np.array((0.229,0.224,0.225))+np.array((0.485,0.456,0.406))
image=image.clip(0,1)
return image
style=load_image(r"C:\Users\zex\Desktop\fangao.png",shape=(256,256)).to(device)
# plt.figure()
# plt.imshow(im_convert(style))
# plt.show()
def gram_matrix(tensor):
"""
指定向量的gram matrix,该矩阵表示了图像的风格特征,
tensor是一张图像前向计算后的一层特征映射
:param tensor:
:return:
"""
#获取tensor的batch_size,channel,height,width
b,c,h,w=tensor.size()
#改变矩阵的维度为(深度,高*宽)
tensor=tensor.view(b,c,h*w)
tensor_t=tensor.transpose(1,2)
#计算gram,针对多张图像进行计算
gram=tensor.bmm(tensor_t)/(c*h*w)
return gram
def get_features(image,model,layers=None):
"""
将一张图像image在一个网络model中进行前向传播计算,并获取指定层layers中的特征输出
:param image:
:param model:
:param layers:
:return:
"""
#layers参数指定:需要用于图像内容和样式表示的图层
#如果layers没有指定,就用默认的层
if layers is None:
layers={
'3':'relu1_2',
'8':'relu2_2',
'15':'relu3_3',#内容图层的表示
'22':'relu4_3'#经过relu激活后的输出
}
features={}#获取的每层特征保存到字典中
x=image#需要获取特征的图像
for name,layer in model._modules.items():
# 从第一层开始获取图像的特征
x=layer(x)
#如果是layers参数指定的特征,那就保存到features中
if name in layers:
features[layers[name]]=x
return features
#计算图像的风格表示
style_layer={
'3':'relu1_2',
'8':'relu2_2',
'15':'relu3_3',
'22':'relu4_3'
}
content_layer={
'15':'relu3_3'
}
#内容表示的图层,均使用经过relu激活后的输出
style_features=get_features(style,vgg,layers=style_layer)
#为我们的风格表示计算每层的拉格姆矩阵,使用字典保存
style_grams={layer:gram_matrix(style_features[layer]) for layer in style_features}
#网络训练,定义三种损失的权重
style_weight=1e5
content_weight=1
tv_weight=1e-5
#定义优化器
optimizer=optim.Adam(fwnet.parameters(),lr=1e-3)
fwnet.train()
since=time.time()
for epoch in range(4):
print("Epoch : {}".format(epoch+1))
content_loss_all=[]
style_loss_all=[]
tv_loss_all=[]
all_loss=[]
for step,batch in enumerate(data_loader):
optimizer.zero_grad()
#计算内容图像使用图像转换网络得到的输出
content_images=batch[0].to(device)
transformed_images=fwnet(content_images)
transformed_images=transformed_images.clamp(-2.1,2.7)
#使用VGG16计算特征
content_features=get_features(content_images,vgg,layers=content_layer)
#计算y_hat图像对应的vgg特征
transformed_features=get_features(transformed_images,vgg)
#内容损失,使用F.mse_loss
content_loss=F.mse_loss(transformed_features['relu3_3'],content_features['relu3_3'])
content_loss=content_weight * content_loss
#total varition图像水平和垂直平移一个像素,原图相减
#然后计算绝对值的和
y=transformed_images
tv_loss=(torch.sum(torch.abs(y[:,:,:,:-1]-y[:,:,:,1:]))+torch.sum(torch.abs(y[:,:,:-1,:]-y[:,:,1:,:])))
tv_loss=tv_weight * tv_loss
#风格损失
style_loss=0.
transformed_grams={layer:gram_matrix(transformed_features[layer]) for layer in transformed_features}
for layer in style_grams:
transformed_gram=transformed_grams[layer]
style_gram=style_grams[layer]
style_loss+=F.mse_loss(transformed_gram,style_gram.expand_as(transformed_gram))
style_loss=style_weight*style_loss
#3个损失相加
loss=style_loss+content_loss+tv_loss
loss.backward(retain_graph=True)
optimizer.step()
#统计各损失的变化情况
content_loss_all.append(content_loss.item())
style_loss_all.append(style_loss.item())
tv_loss_all.append(tv_loss.item())
all_loss.append(loss.item())
if step % 5000==0:
print("step:{};content loss:{:.3f};style loss:{:.3f};tv loss:{:.3f};loss:{:.3f}".format(step,content_loss.item(),style_loss.item(),tv_loss.item(),loss.item()))
# print('step:{};content loss:{:.3f}; style loss:{:.3f};tv loss:{:.3f},loss:{:.3f}'.format(step,content_loss.item(),style_loss.item(),tv_loss.item(),loss.item()))
time_use=time.time()-since
print("Train complete in{:.0f}m {:.0f}s".format(time_use//60,time_use%60))
plt.figure()
im=transformed_images[1,...]
plt.imshow(im_convert(im))
plt.show()
torch.save(fwnet.state_dict(),"C:\\Users\\zex\\Desktop\\imfwnet_dict.pkl")
fwnet.eval()
for step,batch in enumerate(data_loader):
content_images=batch[0].to(device)
if step>0:
break
plt.figure(figsize=(16,4))
for i in range(4):
im=content_images[i,...]
plt.subplot(1,4,i+1)
plt.imshow(im_convert(im))
plt.show()
transformed_images=fwnet(content_images)
transformed_images=transformed_images.clamp(-2.1,2.7)
plt.figure(figsize=(16,4))
for i in range(4):
im=im_convert(transformed_images[i,...])
plt.subplot(1,4,i+1)
plt.imshow(im)
plt.show()
5.CPU上使用预训练好的GPU模型
在上小节训练并保存的图像风格迁移网络是基于GPU模式下的网络参数。下面介绍如何导入训练好的网络参数,并且在CPU上使用该网络进行图像风格迁移。导入GPU模式的网络参数时,首先用device = torch.device('cpu')定义好CPU进行计算的设备,然后定义一个相同的CPU情况下的网络fwnet = ImfwNet(),再使用fwnet.load_state_dict()方法导入网络的参数,并指定参数map_location=device,即将网络的参数映射到基于CPU计算的网络。
content=load_image(r"C:\Users\zex\Desktop\sky.jpg",shape=(256,256))
device=torch.device('cpu')
fwnet=ImfwNet()
fwnet.load_state_dict(torch.load("C:\\Users\\zex\\Desktop\\imfwnet_dict.pkl",map_location=device))
transformed_content=fwnet(content)
plt.figure()
plt.imshow(im_convert(content))
plt.show()
plt.figure()
plt.imshow(im_convert(transformed_content))
plt.show()
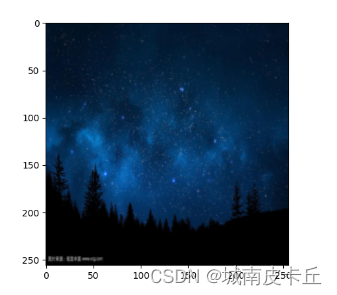
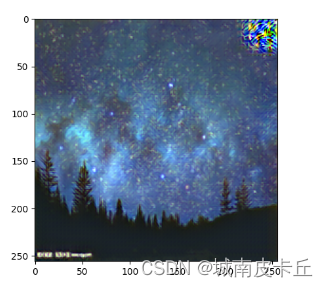
从输出结果可以发现,上一节课介绍的普通风格迁移方法虽然花费的时间长(会花费数个小时甚至几天),但风格迁移效果好;快速风格迁移时间比较短(通常需要两三个小时),但是其风格迁移的效果相对来说并不是很理想。