所谓图像风格迁移,是指利用算法学习著名画作的风格,然后再把这种风格应用到另外一张图片上的技术。
1 图像风格迁移的原理
在学习原始的图像风格迁移之前,可以先回忆一下ImageNet图像识别模型VGGNet。
事实上,可以这样理解VGGNet的结构:前面的卷积层是从图像中提取“特征”,而后面的全连接层是把特征转换为类别概率。其中VGGNet中的浅层(如conv1_1,conv1_2),提取的特征往往是比较简单的(如检测点、线、亮度),VGGNet中的深层(如conv5_1、conv5_2),提取的特征往往是比较复杂(如有无人脸或某种特定物体)。
VGGNet的本意是输入图像,提取特征,并输出图像类别。图像风格迁移正好与其相反,输入特征,输出对应这种特征的图片,如图7-1所示。
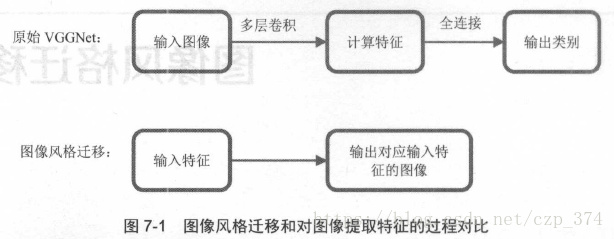
具体来说,风格迁移使用卷积层的中间特征还原出对应这种特征的原始图像(类似于谷歌的Deep Dream模型,不过Deep Dream模型是使用最后一层的类别概率还原出对应的原始图像,使用训练好的模型,权重参数都变,假设你要还原香蕉的原始图像,随机初始化输入图像,使得输入图像经过卷积池化全连接等模型的一系列操作后,最后一层对应香蕉的概率最大,不断优化使其接近于1,此时就还原出了香蕉的图像)。
如图7-2a所示,先选取一幅原始图像,经过VGGNet计算后得到各种卷积层特征。接下来,根据这些卷积层的特征,还原出对应这种特征的原始图像。图像b、c 、d 、e 、f 分别为使用卷积层conv1_2、conv2_2 、conv3 _2 、conv4_2 、conv5_2 的还原图像。可以发现:浅层的还原效果往往比较好,卷积特征基本保留了所高原始图像中形状、位置、颜色、纹理等信息; 深层对应的还原图像丢失了部分颜色和纹理信息,但大体保留原始图像中物体的形状和位置。

还原图像的方法是梯度下降法。设原始图像为![]() ,期望还原的图像为
,期望还原的图像为![]() (即自动生成的图像)。使用的卷积是第l层,原始图像
(即自动生成的图像)。使用的卷积是第l层,原始图像![]() 在第l层的特征为
在第l层的特征为![]() 。i表示卷积的第i个通道,j表示卷积的第j个位置。通常卷积的特征是三维的,三维坐标分别对应(高、宽、通道)。此处不考虑具体的高和宽,只考虑位置j,相当于把卷积“压扁”了。比如一个10x10x32的卷积特征,对应1⩽i⩽32,1⩽j⩽100。对于生成图像
。i表示卷积的第i个通道,j表示卷积的第j个位置。通常卷积的特征是三维的,三维坐标分别对应(高、宽、通道)。此处不考虑具体的高和宽,只考虑位置j,相当于把卷积“压扁”了。比如一个10x10x32的卷积特征,对应1⩽i⩽32,1⩽j⩽100。对于生成图像![]() ,同样定义它在l层的卷积特征为
,同样定义它在l层的卷积特征为![]() 。
。
有了上面这些符号后,可以写出“内容损失”(Content Loss)。内容损失![]() 的定义是:
的定义是:
![]()


其中,图7-3b是由conv1_1的风格损失还原的,图7-3c是由conv1_1,conv2_1两层的风格损失还原的,图7-3d是由conv1_1,conv2_1,conv3_1,图7-3e为conv1_1,conv2_1,conv3_1,conv4_1风格损失还原的。使用浅层还原的“风格图像”的纹理尺度往往比较小,只保留了颜色和局部的纹理(如图7-3b);组合深层、浅层还原出的“风格图像”更加真实且接近原图片(如图7-3f)。
总结一下,到目前为止介绍了两个内容:
- 利用内容损失还原图像内容
- 利用风格损失还原图像风格
那么,可不可以将内容损失和风格损失组合起来,在还原一张图像的同时还原里一张图像的风格呢?答案是肯定的,这是图像风格迁移的基本算法。





2 在TensorFlow 中实现快速风格迁移
在本节中,首先会介绍代码结构,然后讲解如何使用预训练的模型,以及如何自己训练模型,最后说明该项目的一些实现细节。
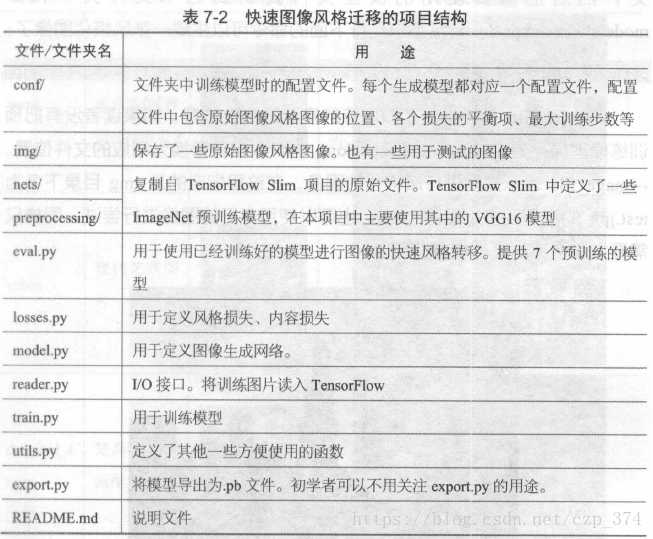
快速图像风格迁移的项目结构见表7-2
这个项目可在我的github上进行下载https://github.com/tongxiaobin/Deep-Learning/tree/master/chapter_7
首先下载这个项目,得到上面表格的文件。
使用预训练模型 (针对七种不同的风格图像,训练好了七个图像生成网络模型):
我的百度网盘里已经提供你了7个预训练模型:wave.ckpt-done、cubist.ckpt-done、denoised_starry.skpt-done、mosaic.ckpt-done、scream.ckpt-done、feathers. ckpt-done。回到源码目录下,在其中新建一个models文件夹,然后把需要使用的模型文件复制到这个文件夹下,如models/wave.ckpt-done。接下来运行下面的命令可以生成一张风格化图像了:
预训练模型下载链接:https://pan.baidu.com/s/1iSFnNNK4LP4M_7KTIIJuSQ 提取码:w0yg
run eval.py --model_file models/denoised_starry.ckpt-done --image_file img/test.jpg --model_file后面指定了与训练的模型的文件位置,--image_file表示需要进行风格化的图像,在这里指定的是img目录下名为
test.jpg 的示例图像),也可以使用自己的图像进行尝试,同样只需要指定文件位置即可。
执行后可能出现如下错误:TypeError: Value passed to parameter ‘paddings’ has DataType float32 not in list of allowed values: int32, int64
这可能是tensorFlow版本不同引起的,新版本的tf对数据格式要求更为严格。解决方法是打开model.py文件,将第9行代码
![]()
修改为(加上int强制类型转换即可):

再运行后,成功风格化的图像会被写到generate/res.jpg。读者可以打开该文件进行查看。除了模型denoised_starry.ckpt-done ,还可以运行其他的预训练、模型。denoised_starry风格化的图片效果如下:



3 训练自己的模型
如何训练自己的图像生成模型呢?这里以wave为例,介绍训练模型的全过程。
在训练之前,需要完成两项前期准备工作。首先下载VGG16模型,将下载到的压缩包解压后会得到一个vgg16.ckpt文件。在该项目文件夹下新建一个pretrained文件夹,并将vgg16.ckpt复制到pretrained文件夹中。最后文件的路径是pretrained/vgg16.ckpt。另外需要下载COCO数据集。将该数据集解压后会得到一个train2014文件夹,其中应该含有大量jpg格式的图片,将train2014文件夹移动到该项目文件夹下。
接下来可以训练模型了。以模型wave为例,对应的训练命令是:
python train.py -c conf/wave.yml该命令的含义是利用已经写好的conf/wave.yml文件来训练模型。wave.yml为配置文件,内容为:
## Basic configuration 基础配置
style_image: img/wave.jpg # targeted style image 指定原始的风格图像
# 这个模型的名字,一般和图像名称保持一致。这个名字决定了checkpoint和events文件的保存文件夹
naming: "wave" # the name of this model. Determine the path
to save checkpoint and events file.
# checkpoint和events文件保存的根目录。最后所有的checkpoint和events文件会被保存在<model_path>/<naming>下
model_path: models # root path to save checkpoint and events file. The final path would be <model_path>/<naming>
## Weight of the loss 各损失权重
content_weight: 1.0 # weight for content features loss内容损失的权重
style_weight: 220.0 # weight for style features loss风格损失权重
# 损失的权重。这是原论文中提到的一个损失。在这个项目中发现设定它的权重为0也不会影响收敛,所以没有提及
tv_weight: 0.0 # weight for total variation loss
## The size, the iter number to run
image_size: 256 #训练原始图像大小
batch_size: 4 #一次batch的样本数
epoch: 2 # 跑的epoch的运行次数
## Loss Network 损失网络
loss_model: "vgg_16" #使用vgg_16模型
content_layers: # use these layers for content loss使用conv3_3定义内容损失
- "vgg_16/conv3/conv3_3"
style_layers: # use these layers for style loss使用这些卷积层定义风格损失
- "vgg_16/conv1/conv1_2"
- "vgg_16/conv2/conv2_2"
- "vgg_16/conv3/conv3_3"
- "vgg_16/conv4/conv4_3"
checkpoint_exclude_scopes: "vgg_16/fc" # we only use the convolution layers, so ignore fc layers.我们只用到卷积层,所以不需要fc层
loss_model_file: "pretrained/vgg_16.ckpt" # the path to the checkpoint # 预训练模型vgg_16.ckpt对应的位置如果我们希望训练新的“风格”,可以选取一张风格图片,并编写新的yml配置文件。其中,需要把style_image修改为新图片所在位置,并修改对应的模型名称naming。这样就可以进行训练了。最后,可以使用训练完成的checkpoint生成图片。在训练新的“风格”时,有可能会需要调整个个损失之间的权重。调整的方法在下一节中进行叙述。
4 在TensorBoard中监控训练情况
在训练过程中,可以打开TensorBoard监控训练情况。仍以wave模型为例:
在anaconda prompt终端先将路径切换到保存的训练数据和日志下即wave文件夹下:
cd /d E:\360MoveData\Users\Administrator\Desktop\python_DL\7.图像风格迁移\models\wave继续输入以下命令(最好用绝对路径):
tensorboard --logdir= E:\360MoveData\Users\Administrator\Desktop\python_DL\7.图像风格迁移\models\wave 执行完后会出现一个网址,在谷歌浏览器中(最好是谷歌,其它浏览器不一定行)访问该网址即可打开Tensorboard的主页面。训练时最先关心的应该是损失损失下降的情况。损失主要由风格损失、内容损失两项构成。展开loss选项卡可以看到损失的变化情况,如图7-7所示:

center_loss和style_loss分别对应了内容损失和风格损失,中间的regularizer_loss可以暂时不用理会。最理想的情况是content_loss和style_loss随着训练不断下降。在训练的初期可能会出现只有style_loss下降而content_loss上升的情况,不过这是暂时的,最后两个损失都会出现较为稳定的下降。
当训练新的“风格”时,有时可能还会需要调整配置文件中的content_ weight 和style_ weight 。当content_weight 过大时,观察到的generated图像会非常接近原始的origin图像。而style_ weight 过大时,会导致图像过于接近原始的风格图像,此时的generated 图像如图7-9 所示,几乎看不到origin图像的内容。在训练时,需要合理调整style_weight和content_weight的比重。

5、项目实现细节
最后讨论项目的细节。该项目使用了两个网络,即损失网络与生成网络。损失网络为VGG16模型,用的是TensorFlow Slim中已经写好的代码,图像生成网络可以自己进行定义。
1. 损失网络、图像生成网络的定义与引用
损失网络使用TenorFlow Slim 的VGG16模型, 它的实际定义位置是在nets/vgg.py文件中,不过没再必要知道它的详细源码,只需要了解是如何在训练过程中引用它的。
而图像生成网络在model.py 中定义,它的关键代码如下:
# 定义图像生成网络
def net(image, training):
# 一开始在图片的上下左右加上一些额外的“边框”,目的是消除边缘效应
# Less border effects when padding a little before passing through ..
image = tf.pad(image, [[0, 0], [10, 10], [10, 10], [0, 0]], mode='REFLECT')
# 三层卷积层
with tf.variable_scope('conv1'):
#conv2d在该文件前面有定义,四个参数分别为输入通道、输出通道、卷积核、步长
conv1 = relu(instance_norm(conv2d(image, 3, 32, 9, 1)))
with tf.variable_scope('conv2'):
conv2 = relu(instance_norm(conv2d(conv1, 32, 64, 3, 2)))
with tf.variable_scope('conv3'):
conv3 = relu(instance_norm(conv2d(conv2, 64, 128, 3, 2)))
# 仿照ResNet定义一些跳过连接
with tf.variable_scope('res1'):
res1 = residual(conv3, 128, 3, 1)
with tf.variable_scope('res2'):
res2 = residual(res1, 128, 3, 1)
with tf.variable_scope('res3'):
res3 = residual(res2, 128, 3, 1)
with tf.variable_scope('res4'):
res4 = residual(res3, 128, 3, 1)
with tf.variable_scope('res5'):
res5 = residual(res4, 128, 3, 1)
# 定义卷积之后定义反卷积
# 反卷积不采用通常的转置卷积的方式,而是采用先放大,在做卷积的方式
# print(res5.get_shape())
with tf.variable_scope('deconv1'):
# deconv1 = relu(instance_norm(conv2d_transpose(res5, 128, 64, 3, 2)))
deconv1 = relu(instance_norm(resize_conv2d(res5, 128, 64, 3, 2, training)))
with tf.variable_scope('deconv2'):
# deconv2 = relu(instance_norm(conv2d_transpose(deconv1, 64, 32, 3, 2)))
deconv2 = relu(instance_norm(resize_conv2d(deconv1, 64, 32, 3, 2, training)))
with tf.variable_scope('deconv3'):
# deconv_test = relu(instance_norm(conv2d(deconv2, 32, 32, 2, 1)))
deconv3 = tf.nn.tanh(instance_norm(conv2d(deconv2, 32, 3, 9, 1)))
# decanv3是经过tanh函数得到的输出值,所以它的值域范围是-1~1
# 知道RGB图像的像素范围是0~255,所以这里对deconv3进行这样的缩放
y = (deconv3 + 1) * 127.5
# Remove border effect reducing padding.
# 最后取出一开始为了防止边缘效应而加入的“边框”
height = tf.shape(y)[1]
width = tf.shape(y)[2]
y = tf.slice(y, [0, 10, 10, 0], tf.stack([-1, height - 20, width - 20, -1]))
return y图像生成网络的原理主要是先对图像卷积计算,然后再进行“反卷积”计算。相当于对图像进行编码,然后再还原为图像。如下(不同卷积层对应的通道数):3——》32——》64——》128——》64——》32——》3
在“反卷积”的过程中,一般使用转置卷积,但在这里可能会导致一些堆叠噪声。此处,使用resize_conv2d来代替转置卷积,它的原理是先对图片放大,然后再进行卷积计算。此外,还有一些提高图像质量的小技巧。比如使用所谓的instance normalization 代替常用的batch normalization 。关于instance normalization 、转置卷积的详细原理,可以参阅相关资料进行了解,这里不再详细展 开了。
定义好图像生成网络和损失网络后,可以在训练时引用。相应的代码在train.py 文件中:
# network_fn是损失网络的函数。因为不需要对损失函数训练,所以is_training = False
network_fn = nets_factory.get_network_fn(
FLAGS.loss_model,
num_classes=1,
is_training=False)
# 损失网络中要用的图像的预处理函数
image_preprocessing_fn, image_unprocessing_fn = preprocessing_factory.get_preprocessing(
FLAGS.loss_model,
is_training=False)
# 读入训练图像
processed_images = reader.image(FLAGS.batch_size, FLAGS.image_size, FLAGS.image_size,
'train2014/', image_preprocessing_fn, epochs=FLAGS.epoch)
# 此处引用图像生成网络。model.net是图像生成网络,generated是生成的图像
# 设置training = True,因为要训练该网络
generated = model.net(processed_images, training=True)
# 将生成的图像generated同样使用image_preprocessing_fn进行处理
# 因为generated同样需要送到损失网络中计算loss
processed_generated = [image_preprocessing_fn(image, FLAGS.image_size, FLAGS.image_size)
for image in tf.unstack(generated, axis=0, num=FLAGS.batch_size)
]
processed_generated = tf.stack(processed_generated)
# 将原始图像、生成图像送到损失网络中
# 这里将它们合并后再送到网络中计算,因为同一的计算可以加快速度
# 将原始图像、生成图像送到损失网络并计算后,将使用结果endpoints_dict 计算损失
_, endpoints_dict = network_fn(tf.concat([processed_generated, processed_images], 0), spatial_squeeze=False)2.内容损失和风格损失的定义
损失的定义基本由文件loss .py中的函数完成。先来介绍如何定义内容损失:
# endpoints_dict是上一节提到的损失网络各层的计算结果
# content_layers是定义使用哪些层的差距计算损失,默认配置是conv3_3
def content_loss(endpoints_dict, content_layers):
content_loss = 0
for layer in content_layers:
# 上一节中把生成的图像、原始图像同时传入损失网络中计算
# 所以这里先把他们区分开
# 读者可以参照函数tf.concat与tf.split的文档理解此处的内容
generated_images, content_images = tf.split(endpoints_dict[layer], 2, 0)
size = tf.size(generated_images)
# 所谓的内容损失,是生成图片generated_images与原始图片激活content_images的L*L距离
content_loss += tf.nn.l2_loss(generated_images - content_images) * 2 / tf.to_float(size) # remain the same as in the paper
return content_loss再看如何定义风格损失:
#定义风格损失
# style_layers为定义使用哪些层计算风格损失。默认为conv1_2、conv2_2、conv3_3、conv4_3
# style_features_t是利用原始的风格图片计算的层的激活
# 如在wave模型中是img/wave.jpg计算的激活
def style_loss(endpoints_dict, style_features_t, style_layers):
style_loss = 0
# summary是为TensorBoard服务的
style_loss_summary = {}
for style_gram, layer in zip(style_features_t, style_layers):
# 计算风格损失,只需要计算生成图片generated_imgs与目标风格
# style_features_t的差距。因此不需要取出content_images
generated_images, _ = tf.split(endpoints_dict[layer], 2, 0)
size = tf.size(generated_images)
# 调用gram函数计算Gram矩阵。风格损失定义为生成图片与目标风格Gram矩阵的L*L的Loss
layer_style_loss = tf.nn.l2_loss(gram(generated_images) - style_gram) * 2 / tf.to_float(size)
style_loss_summary[layer] = layer_style_loss
style_loss += layer_style_loss
return style_loss, style_loss_summary在train.py中,直接利用上面的函数可以得到总的损失:
"""Build Losses"""
# 定义内容损失
content_loss = losses.content_loss(endpoints_dict, FLAGS.content_layers)
# 定义风格损失
style_loss, style_loss_summary = losses.style_loss(endpoints_dict, style_features_t, FLAGS.style_layers)
# 定义tv损失,该损失在实际训练中并没有被用到,因为在训练时都采用tv_weight=0
tv_loss = losses.total_variation_loss(generated) # use the unprocessed image
# 总损失是这些损失的加权和,最后利用总损失优化图像生成网络即可
loss = FLAGS.style_weight * style_loss + FLAGS.content_weight * content_loss + FLAGS.tv_weight * tv_loss3. 确定训练、保存的变量
在本项目中,只需要训练图像生成网络中的变量,而不需要训练损失网络(这里用的是VGG16)中的变量。在把模型保存成checkpoint时,也只需要保存图像生成网络中的变量。TenorFlow会默认训练、保存所有变量,因此必须把需要训练和需要保存的变量找出来,这也是本项目中的一个注意点。对应的代码同样在 train.py中:
# 找出需要训练的变量
variable_to_train = []
# 使用tf.trainable_variables()找出所有可训练的变量
for variable in tf.trainable_variables():
# 如果不在损失网络中,把它们加入列表variable_to_train
if not(variable.name.startswith(FLAGS.loss_model)):
variable_to_train.append(variable)
# 定义训练步骤时指定var_list=variable_to_train。这样不会训练损失网络
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss, global_step=global_step, var_list=variable_to_train)
# 找出所有需要保存的变量
variables_to_restore = []
# 用tf.global_variable()找出所有变量
for v in tf.global_variables():
# 不在损失网络中则加入列表variables_to_restore
if not(v.name.startswith(FLAGS.loss_model)):
variables_to_restore.append(v)
# 定义saver时指定只会保存variables_to_restore
saver = tf.train.Saver(variables_to_restore, write_version=tf.train.SaverDef.V1)6、总结
这篇文章首先详细介绍了原始图像风格迁移的基本原理,其中内容损失、风格损失两种损失函数的定义尤为关键。接着介绍了快速图像风格迁移的原理,并学习了如何使用TenorFlow实现快速图像风格迁移。最后一起研究了项目中的一些实现细节。相信通过这篇文章的介绍,我们可以基本掌握风格迁移这一领域的基本思想与TenorFlow中相应的实现方法。
参考文章:21个项目玩转深度学习
Value passed to parameter 'paddings' has DataType float32 not in list of allowed values: int32, int6