论文:
Image Style Transfer Using Convolutional Neural Networks

提出背景:
作者认为前人所研究的风格迁移问题,是基于从源图像中重新采样该图像的风格像素的分布,从而生成一个新的类似于源图像的风格像素分布,加到目标图像中,而该目标图像中保留下来的基本都是一些低维的像素点,效果并不太理想。随着深度学习的发展,作者就提出使用卷积神经网络来完成风格迁移的任务。
网络结构:
作者认为可以将源图像分为风格图像和内容图像,利用卷积神经网络分别提取各自的特征。风格图像在网络中提取出风格特征,内容图像在网络中提取出内容特征,然后引入初始白噪声图像,该噪声图像在网络中训练得出特征,为内容和风格各自定义一组与噪声特征的损失函数,最后将两个损失函数合在一起进行优化,从而使得噪声图像越来越好的训练到内容和风格的特征,从而完成风格的迁移。其中使用的卷积神经网络是VGG19,因为该网络在当时有着非常好的效果,包括现在也是,VGG19网络结构如图1:

本文作者在使用该VGG19使,去除了最后的全连接和softmax,因为作者目的还是为了生成图像,所以无需这两层。
内容特征表示:
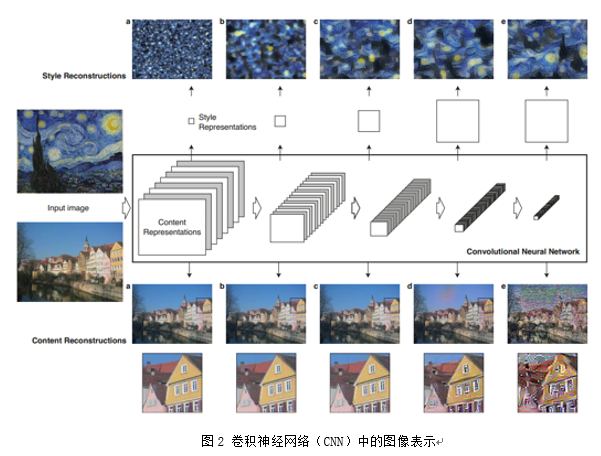
当我们把一张图片输入到VGG19网络中,会在开始处变成一系列向量(每个像素上包含三个channel,代表了图像长什么样)。而在网络的每层中,能得到中间向量,比如 conv3_1,conv4_2(分别代表第三个卷积层的第一个feature map和第四个卷积层的第二个feature map),但是它们并没有内在的含义。不过对于一个训练好的网络,比如 VGG19,其参数已经确定,通过该参数计算得出的中间向量就可以代表该图像本身,这样就可以定义某一个卷积层中的某个feature map作为该图像的内容,比如前面说的conv4_2,可以根据自己的网络结构进行调整,不过拿不同的feature map作为图像的内容对结果会有影响。作者认为,图像的内容可以简单的认为是通过某个训练好的网络(比如 VGG19)进行计算后,某个卷积层中的某个feature map(比如conv4_2)。作者给出的图2中,发现在内容特征表示中,越低层的feature map(比如图2下面的a-c)可以提取出较好的内容特征,而到了高层的feature map,一些像素点就会开始消失,但是会保留高级的内容(比如图2下面的d和e)。
理解了神经网络中每层feature map的信息,然后作者定义了在内容特征上的损失函数,这里使用了平方误差的loss函数:




这里公式中是拿某一个卷积层(比如conv3)中所有的feature map 作为内容,并和新的图像在同一卷积层中的所有feature map进行比较,然后进行平方差求和。不过,这和上面说的某一个卷积层中的某一个feature map作为内容好像不一样,其实作为图像的内容,可以是某一层的全部feature map,也可以是某一个feature map,这取决于你想要得到的结果。拿特定层的所有feature map作为内容,这样更加准确,但同时也增加了计算量,会使训练速度变慢,拿其中一个feature map作为内容,可以加快训练速度,但是内容保真度不能得到保证。
风格特征表示:
作者通过图2中观察每一层中某个feature map和该层中的所有feature map得到的风格特征,发现使用该层的所有feature map效果更好,这和内容特征表示是有点不同的,这里作者定义了一个用于捕获图像风格信息的特征空间,目的是为了保存每一层中多个滤波器(filter)的相关性组合,而这样的相关性组合其实就是feature map两两做内积。定义Gram 矩阵包含图片的纹理信息以及颜色信息,由Gram矩阵给出 :
:




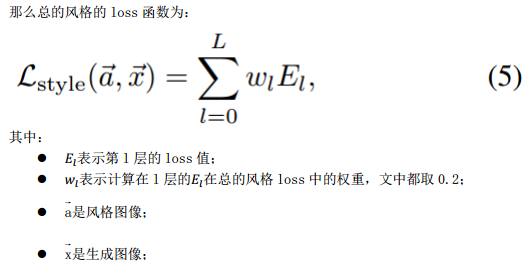
风格转换最终loss函数:
将前面定义好的内容loss函数和风格loss函数线性组合,就得到了最终的loss函数:
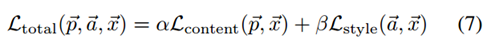
其中α和β分别是内容和风格的权重因子,和为1,若α/β的值越大,则合成图像越具体,若α/β的值越小,则越抽象。
该风格迁移训练的过程如下:

在图3的风格迁移算法中,左边对输入风格图像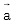 进行特征提取,对每一层所有的feature map都进行内积计算和保存,然后求每一层的loss函数;右边对输入内容图像
进行特征提取,对每一层所有的feature map都进行内积计算和保存,然后求每一层的loss函数;右边对输入内容图像 进行特征提取,只对conv4卷积层中的feature map进行loss计算;中间初始输入白色噪声图像,通过网络在每一层计算与风格的loss值,在conv4计算与内容的loss值,不断地反向传播优化,最后合成风格图像中的风格,内容图像中的内容。
进行特征提取,只对conv4卷积层中的feature map进行loss计算;中间初始输入白色噪声图像,通过网络在每一层计算与风格的loss值,在conv4计算与内容的loss值,不断地反向传播优化,最后合成风格图像中的风格,内容图像中的内容。
结果:
- 利用卷积神经网络可以很好的分离图片的内容和风格,可以独立的对图片的这两个信息进行特征提取,而且效果很好。

- α与β之间的比例会影响合成图片后的效果,α/β越大,合成的图片越具体,越小合成的图片风格化越严重(抽象)。

- 卷积层中不同层次的feature map会提取出不同的特征,因此其对合成图片会产生不同的影响。在风格特征的提取中,层次越高的feature map保持局部图像结构的规模越来越大,从而实现的更加平滑、连续;在内容特征的提取中,层次月底的feature map保留的内容越详细。

- 初始输入白噪声图片在该图片上面合成,和初始输入风格图片或内容图片在其上合成效果差别并不大。

算法的不足:
- 训练速度很慢,合成过程的速度在很大程度上取决于图像分辨率。
- 合成图片过程中会受到一些低级噪声影响。
- 对于图像中风格的定义尚且还不太清楚,对于风格特征从图像中分离出来尚不明确。