图像风格迁移
最后要生成的图片是怎样的是难以想象的,所以朴素的监督学习方法可能不会生效,
Content Loss
根据输入图片和输出图片的像素差别可以比较损失
\(l_{content} = \frac{1}{2}\sum (C_c-T_c)^2\)
Style Loss
从中间提取多个特征层来衡量损失。
利用\(Gram\) \(Matrix\)(格拉姆矩阵)可以衡量风格的相关性,对于一个实矩阵\(X\),矩阵\(XX^T\)是\(X\)的行向量的格拉姆矩阵
\(l_{style}=\sum wi(Ts-Ss)^2\)
总的损失函数
\(L_{total(S,C,T)}=\alpha l_{content}(C,T)+\beta L_{style}(S,T)\)
代码
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.optim as optim
from torchvision import transforms, models
vgg = models.vgg19(pretrained=True).features #使用预训练的VGG19,features表示只提取不包括全连接层的部分
for i in vgg.parameters():
i.requires_grad_(False) #不要求训练VGG的参数定义一个显示图片的函数
def load_img(path, max_size=400,shape=None):
img = Image.open(path).convert('RGB')
if(max(img.size)) > max_size: #规定图像的最大尺寸
size = max_size
else:
size = max(img.size)
if shape is not None:
size = shape
transform = transforms.Compose([
transforms.Resize(size),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),
(0.229, 0.224, 0.225))
])
'''删除alpha通道(jpg), 转为png,补足另一个维度-batch'''
img = transform(img)[:3,:,:].unsqueeze(0)
return img载入图像
content = load_img('./images/turtle.jpg')
style = load_img('./images/wave.jpg', shape=content.shape[-2:]) #让两张图尺寸一样
'''转换为plt可以画出来的形式'''
def im_convert(tensor):
img = tensor.clone().detach()
img = img.numpy().squeeze()
img = img.transpose(1,2,0)
img = img * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))
img = img.clip(0,1)
return img使用的图像为(左边为Content Image,右边为Style Image):

扫描二维码关注公众号,回复:
5608593 查看本文章

定义几个待会要用到的函数
def get_features(img, model, layers=None):
'''获取特征层'''
if layers is None:
layers = {
'0':'conv1_1',
'5':'conv2_1',
'10':'conv3_1',
'19':'conv4_1',
'21':'conv4_2', #content层
'28':'conv5_1'
}
features = {}
x = img
for name, layer in model._modules.items():
x = layer(x)
if name in layers:
features[layers[name]] = x
return features
def gram_matrix(tensor):
'''计算Gram matrix'''
_, d, h, w = tensor.size() #第一个是batch_size
tensor = tensor.view(d, h*w)
gram = torch.mm(tensor, tensor.t())
return gram
content_features = get_features(content, vgg)
style_features = get_features(style, vgg)
style_grams = {layer:gram_matrix(style_features[layer]) for layer in style_features}
target = content.clone().requires_grad_(True)
'''定义不同层的权重'''
style_weights = {
'conv1_1': 1,
'conv2_1': 0.8,
'conv3_1': 0.5,
'conv4_1': 0.3,
'conv5_1': 0.1,
}
'''定义2种损失对应的权重'''
content_weight = 1
style_weight = 1e6训练过程
show_every = 400
optimizer = optim.Adam([target], lr=0.003)
steps = 2000
for ii in range(steps):
target_features = get_features(target, vgg)
content_loss = torch.mean((target_features['conv4_2'] - content_features['conv4_2'])**2)
style_loss = 0
'''加上每一层的gram_matrix矩阵的损失'''
for layer in style_weights:
target_feature = target_features[layer]
target_gram = gram_matrix(target_feature)
_, d, h, w = target_feature.shape
style_gram = style_grams[layer]
layer_style_loss = style_weights[layer] * torch.mean((target_gram - style_gram)**2)
style_loss += layer_style_loss/(d*h*w) #加到总的style_loss里,除以大小
total_loss = content_weight * content_loss + style_weight * style_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
if ii % show_every == 0 :
print('Total Loss:',total_loss.item())
plt.imshow(im_convert(target))
plt.show()将输入的图像和最后得到的混合图作比较:
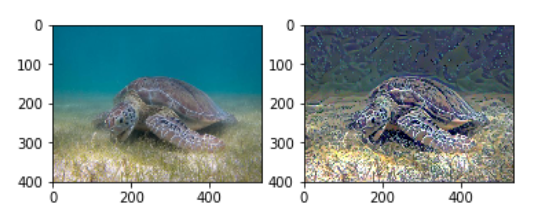
没有达到最好的效果,还有可以优化的空间√
参考:
- Image Style Transfer Using Convolutional Neural Networks论文
- Udacity——PyTorch Scholarship Challenge