在上篇整理过IN,LN,GN等归一化操作。但还有一些操作名词和它们密切相关,如AdaIN,LIN,AdaLIN等,因为它们主要是出现在图像风格迁移任务中,所以这篇单独拿出来讲一下这几个名词。
AdaIN
(首先回顾一下IN:)
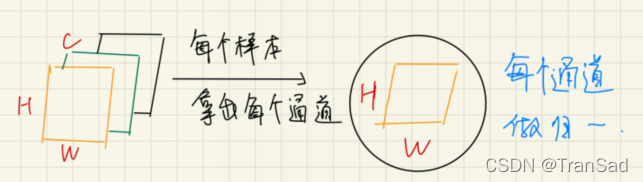
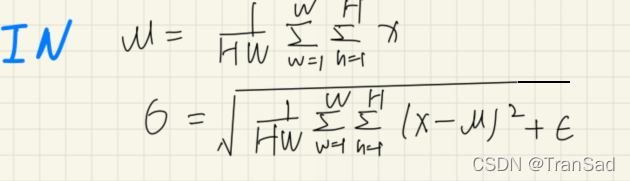
通过上篇我们已经知道IN是对于特征图的每一个通道的H、W求均值和标准差,IN的示意图和公式回顾如下:
我们的IN在进行初步“减均值比标准差”操作过后,还需要通过γ和β来进行线性变换,即:
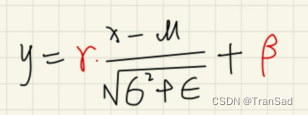
(开始讲AdaIN:)
而AdaIN并没有要学习的放射参数γ和β——但这并不意味着AdaIN没有最后变换步骤,它是现场通过自己的网络计算得到的“γ”和“β”来进行变换。这么一听可能有点奇怪,什么叫通过自己的网络来计算呢?我们先来明确一下AdaIN的应用场景,AdaIN是用于图像风格迁移的,一般来说我们给AdaIN传入的输入有两个:内容输入x和风格输入y,然后通过AdaIN进行处理,将y的风格迁移到x的内容上,从而完成两个输入的整合。
对于内容输入x和风格输入y,二者一开始都是图像,但通过我们初步的卷积神经网络(比如VGG)会将它们提取成特征图,这个时候,我们使用IN进行归一化,就可以得到μ(x),σ(x)以及μ(y),σ(y),分别表示内容的均值和方差、风格的均值和方差。注意,这个时候,我们的AdaIN的意思就是,用σ(y)来充当γ,μ(y)来充当β。
也就是说我们的AdaIN可以表示为:
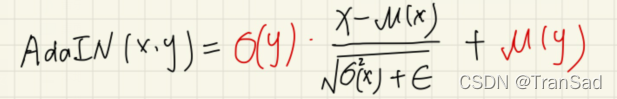
说白了,我们的AdaIN进行了这样的一个操作:
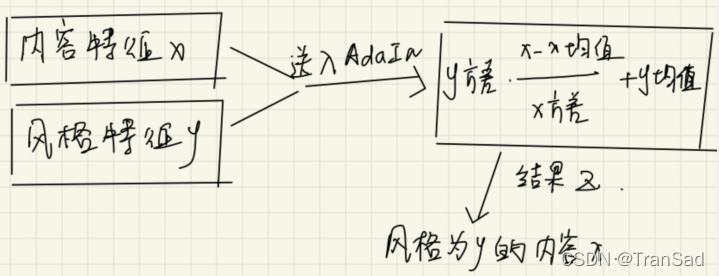
拿到AdaIN的输出之后,我们再进行一系列神经网络(解码操作)就可以得到目标结果了。其中x,y,z可以简单举例如下:



到这里,我们AdaIN就讲完了。因此我们说:AdaIN并不需要额外的学习参数γ和β,而是用自己计算得到的。也有说法说AdaIN是通过自己的MLP网络来计算得到γ和β,这个“MLP“网络其实就指处理输入风格图像的VGG网络。更详细地说:γ和β并不仅是VGG网络的输出,而是在这个输出特征层的基础上再进行IN操作的结果。
LIN
LIN看这个名字其实就能猜到个差不多:融合了LN和IN而得名。我们上篇讲GN的时候也说GN其实是介于LN和IN之间的一种归一化方式,GN是通过“对通道分组“的方式来体现。而LIN就更直接了,直接通过一个参数ρ来对IN和LN进行加权融合。
LIN的公式示意如下:
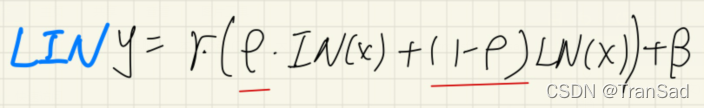
其实就是多了个参数ρ嘛,还是挺好理解的,这里附上一段LIN的代码做参考:
class LIN(nn.Module):
def __init__(self, num_features, eps=1e-5):
super(LIN, self).__init__()
self.eps = eps#防止分母为0的极小值ε
self.rho = Parameter(torch.Tensor(1, num_features, 1, 1))#权重ρ
self.gamma = Parameter(torch.Tensor(1, num_features, 1, 1))#γ
self.beta = Parameter(torch.Tensor(1, num_features, 1, 1))#beta
self.rho.data.fill_(0.0)
self.gamma.data.fill_(1.0)
self.beta.data.fill_(0.0)
def forward(self, input):
#使用IN,对W和H维度做均值和方差计算,得到IN下的均值in_mean和方差in_var
in_mean, in_var = torch.mean(input, dim=[2, 3], keepdim=True), torch.var(input, dim=[2, 3], keepdim=True)
#通过得到的in_mean和in_var进行归一化,得到IN结果out_in
out_in = (input - in_mean) / torch.sqrt(in_var + self.eps)
#使用LN,对C,W和H维度做均值和方差计算
ln_mean, ln_var = torch.mean(input, dim=[1, 2, 3], keepdim=True), torch.var(input, dim=[1, 2, 3], keepdim=True)
#同理得到LN归一化结果out_ln
out_ln = (input - ln_mean) / torch.sqrt(ln_var + self.eps)
#通过ρ控制IN和LN的加权融合
out = self.rho.expand(input.shape[0], -1, -1, -1) * out_in + (1-self.rho.expand(input.shape[0], -1, -1, -1)) * out_ln
#最外边再加上γ和β做调整变换
out = out * self.gamma.expand(input.shape[0], -1, -1, -1) + self.beta.expand(input.shape[0], -1, -1, -1)
#out就是我们LIN的最终结果啦
return outAdaLIN
AdaLIN和LIN的区别与AdaIN和IN的区别差不太多,AdaLIN当中的γ和β也不是自己学习出的,而是自己(通过网络)计算出的。

小结:
这篇文章简单梳理了一下AdaIN,LIN,AdaLIN等操作。至此结合上篇,从BN,IN,LN到后面“不管什么N”都大概提及了,如果要修改再做补充~