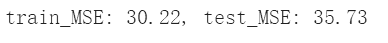版权声明:本文版权归作者所有,未经允许不得转载! https://blog.csdn.net/m0_37827994/article/details/86572817
线性回归
一、理论
其中,
- 是预测值,N行1列(N是样本数)
- 是输入值,N行D列(D是特征数)
- 是权重,D行1列
目标:根据线性模型使用输入 来预测输出 ,该模型将是一条最佳拟合直线,使预测结果与目标结果之间的距离最小。训练数据 被用来训练模型并根据随机梯度下降法来学习权重 。
训练步骤:
1、随机初始化模型的权重
2、向模型中喂入数据
,得到预测值
3、根据目标函数来比较预测值
与真实值
之间的差距来确定损失函数
。一般来说线性回归的目标函数都是均方值误差(MSE),即:
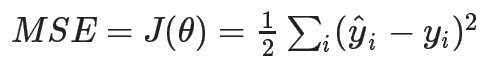
4、计算损失函数的梯度:
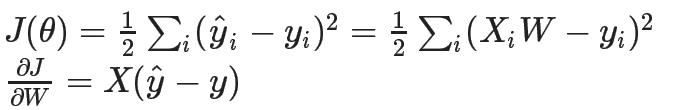
5、根据后向传播来更新权重:
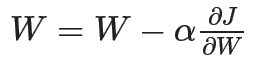
6、重复步骤2~5,直到模型训练的很好。
二、代码实现
1、自己制造数据
from argparse import Namespace
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Arguments
args = Namespace(
seed=1234,
data_file="sample_data.csv",
num_samples=100,
train_size=0.75,
test_size=0.25,
num_epochs=100,
)
# Set seed for reproducability
np.random.seed(args.seed)
# Generate synthetic data
def generate_data(num_samples):
X = np.array(range(num_samples))
random_noise = np.random.uniform(-10,10,size=num_samples)
y = 3.65*X + 10 + random_noise # add some noise
return X, y
# Generate random (linear) data
X, y = generate_data(args.num_samples)
data = np.vstack([X, y]).T
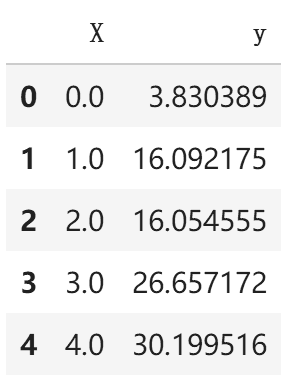
df = pd.DataFrame(data, columns=['X', 'y'])
df.head()
输出结果:
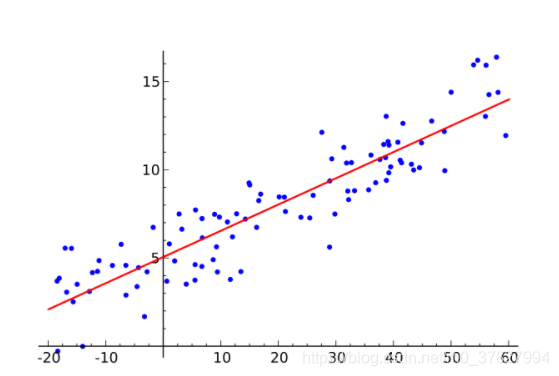
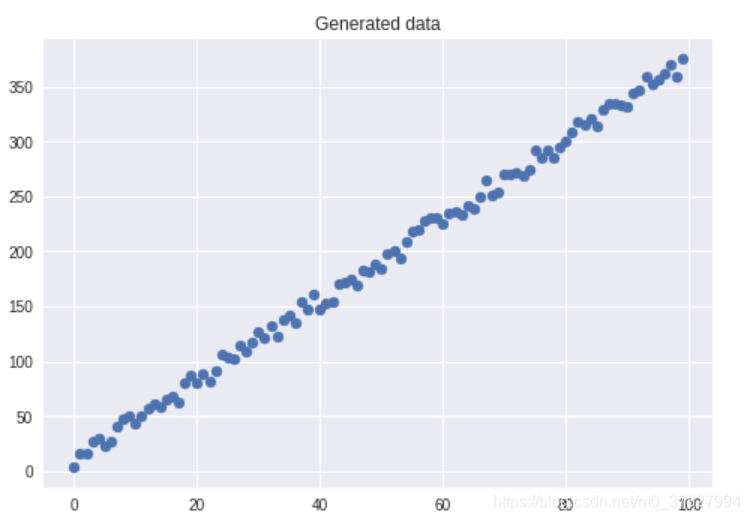
# Scatter plot
plt.title("Generated data")
plt.scatter(x=df["X"], y=df["y"])
plt.show()
输出结果:
2、使用Scikit-learn来实现线性回归
# Import packages
from sklearn.linear_model.stochastic_gradient import SGDRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Create data splits
X_train, X_test, y_train, y_test = train_test_split(
df["X"].values.reshape(-1, 1), df["y"], test_size=args.test_size,
random_state=args.seed)
print ("X_train:", X_train.shape)
print ("y_train:", y_train.shape)
print ("X_test:", X_test.shape)
print ("y_test:", y_test.shape)
输出结果:

# Standardize the data (mean=0, std=1) using training data
X_scaler = StandardScaler().fit(X_train)
y_scaler = StandardScaler().fit(y_train.values.reshape(-1,1))
# Apply scaler on training and test data
standardized_X_train = X_scaler.transform(X_train)
standardized_y_train = y_scaler.transform(y_train.values.reshape(-1,1)).ravel()
standardized_X_test = X_scaler.transform(X_test)
standardized_y_test = y_scaler.transform(y_test.values.reshape(-1,1)).ravel()
# Check
print ("mean:", np.mean(standardized_X_train, axis=0),
np.mean(standardized_y_train, axis=0)) # mean should be ~0
print ("std:", np.std(standardized_X_train, axis=0),
np.std(standardized_y_train, axis=0)) # std should be 1
输出结果:

# Initialize the model
lm = SGDRegressor(loss="squared_loss", penalty="none", max_iter=args.num_epochs)
# Train
lm.fit(X=standardized_X_train, y=standardized_y_train)
输出结果:

# Predictions (unstandardize them)
pred_train = (lm.predict(standardized_X_train) * np.sqrt(y_scaler.var_)) + y_scaler.mean_
pred_test = (lm.predict(standardized_X_test) * np.sqrt(y_scaler.var_)) + y_scaler.mean_
- 注:这里没有使用正则化,后面会给出加上正则化的结果。
3、评估
import matplotlib.pyplot as plt
# Train and test MSE
train_mse = np.mean((y_train - pred_train) ** 2)
test_mse = np.mean((y_test - pred_test) ** 2)
print ("train_MSE: {0:.2f}, test_MSE: {1:.2f}".format(train_mse, test_mse))
输出结果:
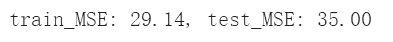
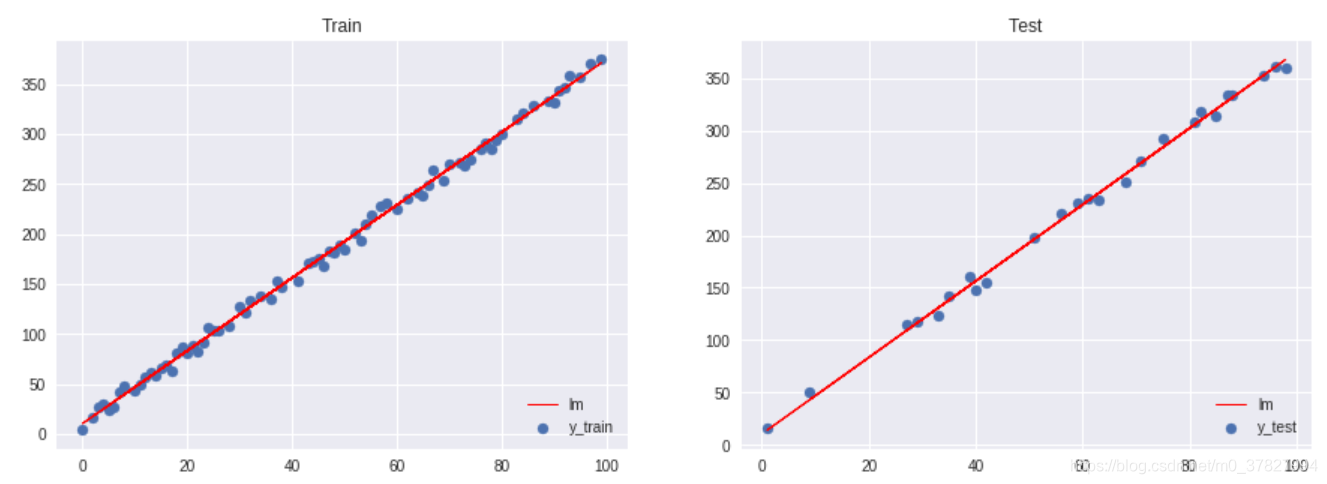
# Figure size
plt.figure(figsize=(15,5))
# Plot train data
plt.subplot(1, 2, 1)
plt.title("Train")
plt.scatter(X_train, y_train, label="y_train")
plt.plot(X_train, pred_train, color="red", linewidth=1, linestyle="-", label="lm")
plt.legend(loc='lower right')
# Plot test data
plt.subplot(1, 2, 2)
plt.title("Test")
plt.scatter(X_test, y_test, label="y_test")
plt.plot(X_test, pred_test, color="red", linewidth=1, linestyle="-", label="lm")
plt.legend(loc='lower right')
# Show plots
plt.show()
输出结果:
4、应用在新样本上
# Feed in your own inputs
X_infer = np.array((0, 1, 2), dtype=np.float32)
standardized_X_infer = X_scaler.transform(X_infer.reshape(-1, 1))
pred_infer = (lm.predict(standardized_X_infer) * np.sqrt(y_scaler.var_)) + y_scaler.mean_
print (pred_infer)
df.head(3)
输出结果:

*5、使用正则化
使用正则化能够避免过拟合。下面是L2正则化。
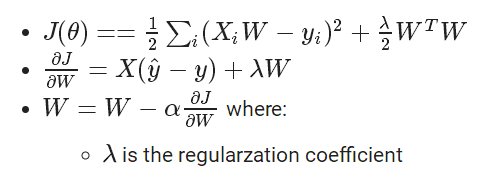
# Initialize the model with L2 regularization
lm = SGDRegressor(loss="squared_loss", penalty='l2', alpha=1e-2,
max_iter=args.num_epochs)
# Train
lm.fit(X=standardized_X_train, y=standardized_y_train)
输出结果:

# Predictions (unstandardize them)
pred_train = (lm.predict(standardized_X_train) * np.sqrt(y_scaler.var_)) + y_scaler.mean_
pred_test = (lm.predict(standardized_X_test) * np.sqrt(y_scaler.var_)) + y_scaler.mean_
# Train and test MSE
train_mse = np.mean((y_train - pred_train) ** 2)
test_mse = np.mean((y_test - pred_test) ** 2)
print ("train_MSE: {0:.2f}, test_MSE: {1:.2f}".format(
train_mse, test_mse))
输出结果: