线性回归算法
1 简单线性回归(Simple Liner Regression)
- 解决回归问题
- 思想简答,容易实现
- 许多强大的非线性模型的基础
- 结果具有很好的可解释性
- 蕴含机器学习中的很多重要思想
1.1 什么是线性回归算法?
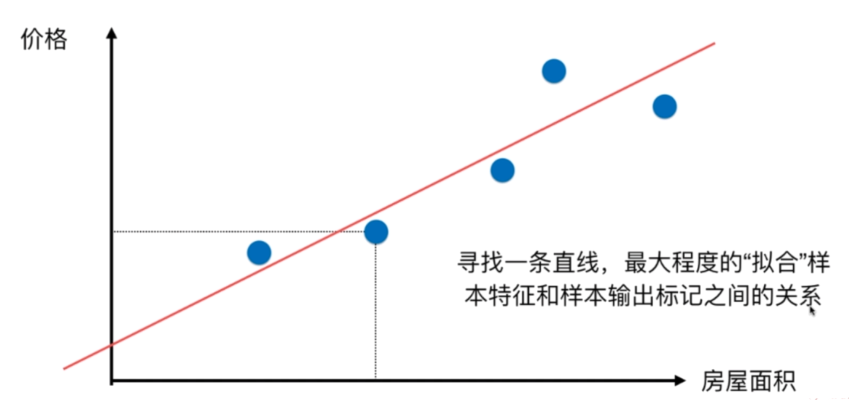
一个简单的例子就是房屋的面积与房子的价格,通过对样本点的学习从而找到一条最大程度拟合所有样本点的直线
从而每次获得一个新的样本带入模型即可给出预测的
值,像这样的特征值只有一个的我们称之为简单线性回归,特征值有多个的我们称之为多元线性回归。
1.2 如何寻找“最大程度”拟合的这条直线呢?
假设我们已经找到了最佳拟合的直线方程:
则对于每一个样本点
根据我们的线性方程,则可计算出预测值为
而我们希望真实值
与预测值
的差距尽量小,而如何来衡量这两者的差距呢?最简单的方式就是两者作差
,然而这种方式计算出的差值有正有负,求和之后值可能为零,所以这种衡量方式并不可行。另一种方式即两者作差的绝对值,即
,然而绝对值在某些地方并不可导,对后续的求导求最值有影响,所以也不考虑这种方式。最后一种,考虑所有的样本
这种衡量方式显然符合要求。所以现在的目标就是使得目标函数
尽可能小,通过最优化这个损失函数以此获得机器学习模型。这是一个典型的最小二乘法的问题,我们通过求解后得出的参数
和
:
由此我们即可确定最大程度拟合的这条直线。
1.3 简单线性回归的实现
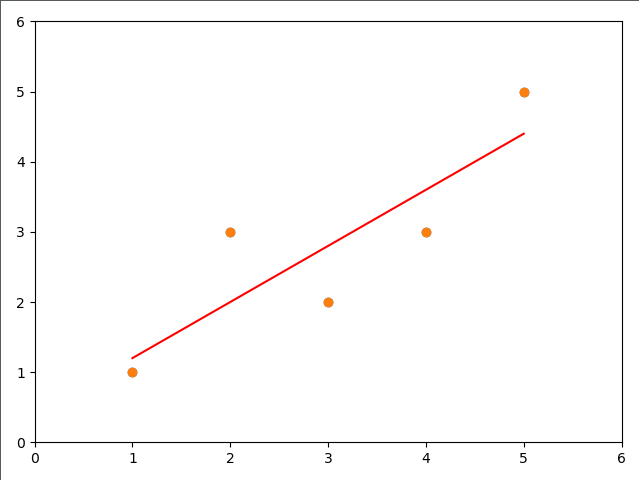
手动生成五个点 求一条最佳直线来拟合这五个点
#SimpleLinearRegression.py
import numpy as np
class SimpleLinearRegression1:
def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train, y_train训练 SimpleLinearRegression模型"""
assert x_train.ndim == 1,\
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train),\
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x,y in zip(x_train, y_train):
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2 self.a_ = num/d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回x_predict的结果向量"""
assert x_predict.ndim == 1,\
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None,\
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1()"
*****************************************************************************
#test.py
import numpy as np
from SimpleLinearRegression import SimpleLinearRegression1
import matplotlib.pyplot as plt
x = np.array([1.,2.,3.,4.,5.])
y = np.array([1.,3.,2.,3.,5.])
x_predict = 6 reg1= SimpleLinearRegression1()
reg1.fit(x, y)
y_predict = reg1.predict(np.array([x_predict]))
print(y_predict)
y_hat = reg1.a_ * x + reg1.b_
plt.scatter(x, y)
plt.plot(x, y_hat, color = 'r')
plt.axis([0,6,0,6])
plt.show()
运行结果:
[5.2]
1.4 向量化
在1.3中我们在计
的值时使用了for循环来计算,然而在numpy中,通过向量的方法来计算性能会快很多。
观察
和
学习过线性代数的同学都知道两个向量的点乘运算就是两个向量的对应元素相乘再相加,上面的
这个式子其实就可以看做两个向量的点乘运算,即
其中(
和
均为向量),如此我们就可以把上述
的式子改写为分子分母均为两个向量做点乘运算的式子,如此在numpy中使用.dot方法会比使用for循环的方法在性能上有显著的提高。
在1.3中我们已经将SimpleLinearRegression的fit方法和predict方法进行了封装,现在我们只需要将fit方法中计算斜率的计算方式改写即可。
在下面的代码中我们新建了一个类叫做SimpleLinearRegression2,在这个方法中我们对斜率a的计算改为了向量运算,然后我们用两种方法分别对一组数据进行测试
#***************************
#SimpleLinearRegression.py *
#***************************
import numpy as np
#使用for循环计算a的值
class SimpleLinearRegression1:
def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train, y_train训练 SimpleLinearRegression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x, y in zip(x_train, y_train):
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1()"
#使用向量计算a的值
class SimpleLinearRegression2:
def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train, y_train训练 SimpleLinearRegression模型"""
assert x_train.ndim == 1,\
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train),\
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = (x_train - x_mean).dot(y_train - y_mean)
d = (x_train - x_mean).dot(x_train - x_mean)
self.a_ = num/d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回x_predict的结果向量"""
assert x_predict.ndim == 1,\
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None,\
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1()"
#***************************
# test.py *
#***************************
import numpy as np
from timeit import timeit
from SimpleLinearRegression import SimpleLinearRegression1
from SimpleLinearRegression import SimpleLinearRegression2
reg1 = SimpleLinearRegression1()
reg2 = SimpleLinearRegression2()
m = 10000
big_x = np.random.random(size=m)
big_y = big_x * 2 + 3.0 + np.random.normal(size=m)
def timereg1():
reg1.fit(big_x, big_y)
def timereg2():
reg2.fit(big_x, big_y)
#计算使用两种算法的运行时间
t1 = timeit('timereg1()', 'from __main__ import timereg1', number=100)
t2 = timeit('timereg2()', 'from __main__ import timereg2', number=100)
print(t1)
print(t2)
#************************************************************************
# 运行结果:
# 1.4340187229999999
# 0.009358100000000036
从上面的代码运行结果我们可以看到,使用reg1方法(for循环)执行100次平均花费时间1.434秒,而使用reg2方法(向量)执行100次平均花费0.009秒,两者在性能上有着显著的差异。
2 衡量线性回归的性能指标
2.1 均方误差MSE(Mean Squared Error)
2.2 均方根误差RMSE(Root Mean Squared Error)
2.3 平均绝对误差MAE(Mean Absolute Error)
2.4 以波士顿房价数据集使用线性回归方法预测房价并求几个性能指标
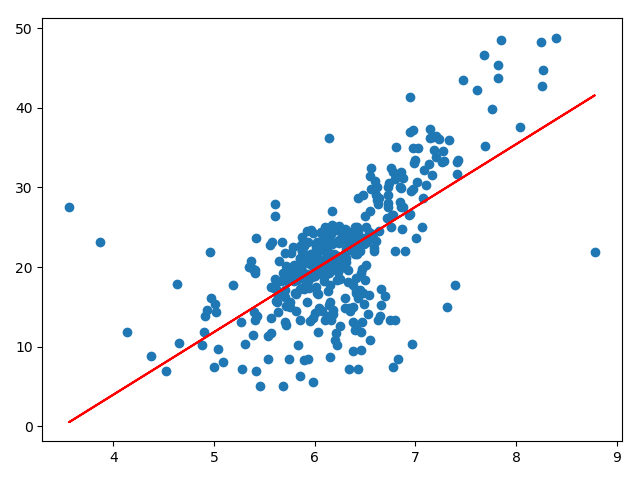
由于目前为止我们只学习了简单线性回归即数据只有一个特征,所以我们将只把波士顿房产数据中的RM(房间数量)作为数据对象
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from math import sqrt
#波士顿房产数据
boston = datasets.load_boston()
#查看数据描述
# print(boston.DESCR)
#print(boston.feature_names)
#只选择第6列的数据(RM)
x = boston.data[:,5]
y = boston.target
#这里使用fancy indexing将房价大于等于50的数据剔除
x = x[y < 50.0]
y = y[y < 50.0]
#使用简单线性回归法训练模型
from model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,y,seed=666)
# print(x_train.shape)
from SimpleLinearRegression import SimpleLinearRegression2
reg2 = SimpleLinearRegression2()
reg2.fit(x_train, y_train)
print("预测出的直线斜率为:", reg2.a_)
print("预测出的直线截距为:", reg2.b_)
plt.scatter(x_train, y_train)
plt.plot(x_train, reg2.predict(x_train), color='r')
# plt.show()
y_predict = reg2.predict(x_test)
#MSE
mse_test = np.sum(((y_predict - y_test) ** 2) / len(y_test))
print("均方误差:",mse_test)
#RMSE
rmse_test = sqrt(mse_test)
print("均方根误差:",rmse_test)
#MAE
mae_test = np.sum(np.absolute(y_predict - y_test) / len(y_test))
print("平均绝对误差:", mae_test)
#scikit-learn中MSE和MAE的实现
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
print(mean_squared_error(y_test, y_predict))
print(mean_absolute_error(y_test, y_predict))
#************************************************************************
# 运行结果:
# 预测出的直线斜率为: 7.8608543562689555
# 预测出的直线截距为: -27.459342806705543
# 均方误差: 24.15660213438744
# 均方根误差: 4.914936635846636
# 平均绝对误差: 3.543097440946387
2.5 最好的衡量线性回归法的指标
R Squared
分母: 使用我们自己的模型预测产生的错误
分子: 使用
(Baseline Model)预测产生的错误
这个模型通俗的理解就是对于待预测的每一个y值我都让其等于其平均值,用这样一个模型作为基准模型来衡量我们自己训练的模型的好坏程度。
- 越大越好。当我们的预测模型不犯任何错误时, 得到最大值1
- 当我们的模型等于基准模型时, 为0
- 如果 ,说明我们学习到的模型还不如基准模型。此时很有可能我们的数据不存在任何线性关系
3 多元线性回归和正规方程解
3.1 多元线性回归
对于一个简单线性回归问题,我们只需要找到一条
的这样一条最佳拟合所有数据的直线就可以解决我们需要解决的问题了,对于多元线性回归问题来说,我们的特征不再只有一个,所以这时我们需要找到一条这样的直线来拟合我们的数据
对于简单线性回归来说我们只需要求出两个参数的值 (
和
)。而对于多元线性回归我们需要求出
和参数的值,即
、
……
。
对于这样一个问题的求解,我们同样是使目标函数
尽可能地小,只不过这里的
对于上述式子中的
、
……
我们可以整理为向量的形式,即:
然后在
后面乘以一个
,其中
,这样整个式子就变成了
此时又可以把上述式子中的
、
……
整理成为
此时
因此,只要我们求解出
这个列向量,对于任意的一个特征矩阵
我们都可以求得其预测值为
目标函数
依旧可以整理成为向量的形式,这个式子的数学意义为每一个真值减去其预测值座平方运算再做求和运算,我们可以将其写成向量点乘的形式(向量点乘的运算法则就是对应元素相乘再相加),因此我们假设所有的真值为一个列向量
则:
因此我们需要求得列向量
的值是的目标函数最小,下面直接给出结果
这个结果就被称为多元线性回归的正规方程解
3.2 波士顿房价预测(多元线性回归法实现)
在之前我们通过简单线性回归法预测波士顿房价时知道,这一组数据其实有13个特征,而我们仅仅使用了RM这一个特征使用简单线性回归法去做了预测,在我们学习过多元线性回归法之后综合考虑这13个特征再次做一下预测,看看效果如何。
首先我们在LinearRegression.py中封装了fit_nomal和predict还有score方法分别用于训练模型,预测模型和给出R方评价。在LinearRegressionTest.py中实现了房价预测
#***************************
# LinearRegression.py *
#***************************
import numpy as np
class LinearRegression:
def __init__(self):
"""初始化LinearRegression模型"""
self.coef_ = None
self.interception_ = None
self._theta = None
def fit_nomal(self, X_train, y_train):
"""根据训练数据集X_train训练 Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0],\
"the size of X_train must be equal to the size of y_train"
X_b = np.hstack([np.ones((len(X_train),1)), X_train])
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待测数据集 X_predict,返回X_predict的结果向量"""
assert self.interception_ is not None and self.coef_ is not None,\
"must fit berore predict"
assert X_predict.shape[1] == len(self.coef_),\
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的精确度"""
y_predict = self.predict(X_test)
return 1 - (np.sum(((y_predict - y_test) ** 2) / len(y_test))) / (np.var(y_test))
def __repr__(self):
return "LinearRegression()"
#*******************************
# LinearRegressionTest.py *
#*******************************
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
X = X[y < 50.0]
y = y[y < 50.0]
from model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
print(len(X_train))
from LinearRegression import LinearRegression
reg = LinearRegression()
reg.fit_nomal(X_train, y_train)
print("截距:", reg.interception_)
print("系数:", reg.coef_)
print("测试数据R方值:", reg.score(X_test, y_test))
#************************************************************************
# 运行结果:
# 截距: 34.16143549623008
# 系数: [-1.18919477e-01 3.63991462e-02
# -3.56494193e-02 5.66737830e-02
# -1.16195486e+01 3.42022185e+00
# -2.31470282e-02 -1.19509560e+00
# 2.59339091e-01 -1.40112724e-02
# -8.36521175e-01 7.92283639e-03
# -3.81966137e-01]
# 测试数据R方值: 0.8129802602658653