线性回归(liner regression)
1、回归问题
回归问题和分类问题很相似,回归问题输出的是一个标量(scalar),即输出的是一个连续的值。

回归其实就是预测,根据输入(Input)得到输出(output)。关键是 如何描述输入与输出的关系,输入与输出的关系 是一种映射关系,数学里面的函数关系(functiona relationship)。怎么样找到这种二者之间的这种关系?
这里面有两种数据,一种是训练数据(train set)和测试数据(test set data);训练数据是指使用该数据来找到 输入与输出之间关系的 数据,找到function的数据集;测试数据是用来判断 训练所得到 function 的好坏。
2、一般步骤
要寻找数据和对应连续值之间的关系,实际就是要找到一个函数,能够将数据映射到连续值上。
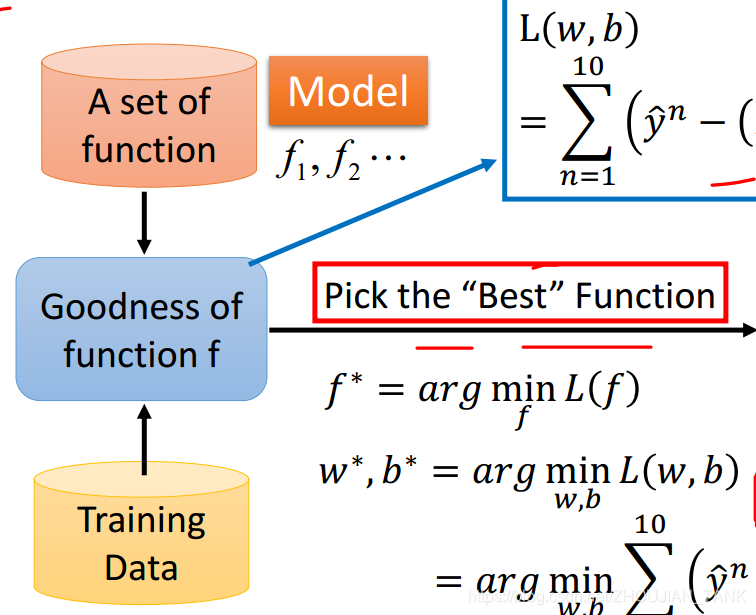
回归问题一般通过以下三步解决:
- Model: set a model (function set)
选择一个模型。模型实际就是函数的集合,线性回归模型,就是所有线性函数组成的集合 - Goodness of function
需要有一个评判标准,能够判断函数的好坏 (评价model中的某个function 预测的值与真实值之间的偏离程度的一个 loss function) - Best function
利用上一步中评判标准,在函数集合中找到最好的函数
对于不同的模型,寻找最好的函数的方法,很有可能是不一样的。但是对于同一个问题,判断函数好坏的方法往往是相同的。
2.1 set a model
本文我们所讨论的是线性模型,一般还有 核模型 ,层模型(神经网络)。
(1)首先,从学习对象f函数的输入是一维的情况开始说明。即输入只有一个变量,一个feature;
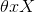 在这里
在这里 ***表示模的参数(标量)***,通过对这个参数的学习,训练,完成函数的近似相似。这是最简单的模型,只有一个参数 theta ,该参数也称之为weight(权重),可以外加一个bias。然而,因为这个模型只能表示线性的输入输出函数(即直线关系),所以在解决实际问题方面,往往没有太大的实用价值。
***表示模的参数(标量)***,通过对这个参数的学习,训练,完成函数的近似相似。这是最简单的模型,只有一个参数 theta ,该参数也称之为weight(权重),可以外加一个bias。然而,因为这个模型只能表示线性的输入输出函数(即直线关系),所以在解决实际问题方面,往往没有太大的实用价值。
(2)一般情况下。
现在,我们拓展一下,如果我们给定了d个属性(size和s就是两种属性)描述的样本如下:
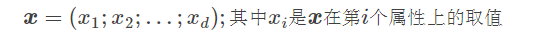
线性模型试图学习到一个通过属性的线性组合来进行预测的函数,即
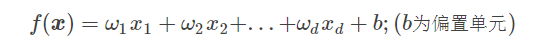
我们可以用向量形式表示
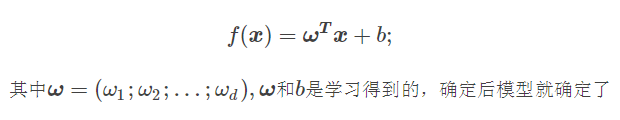
上面的式子就是线性模型的一般表达式了,可以看到线性模型的形式很简洁,而且易于建模。
2.2Goodness of function
在2.1中确定线性模型之后,可知该模型中有无数个 functiona,根据不同 w,b的取值就是一个function。我们要在这些function set中挑选出一个function?挑选这个functiona的原则就是 该function能很好的拟合训练数据,即***最终w,b所确定的function在训练集上所得到的预测值和真实值之间差别不是特别大。***

2.3pick the best function
如何求解W 和 b?

2.3.1最小二乘法(可参考图解机器学习 Chapter3)
当loss function为均方误差时,用最小二乘法可以直接计算出w和b的解析解。
最小二乘法找到的是误差平方和最小的函数:

最小二乘法实际是对w和b分别求偏导,令导数等于0

此种方法可进一步扩展,具体见图解机器学习。
2.3.2梯度下降(gradient descent)
当loss function改变了,最小二乘法很可能不再有用。这时,可以采用梯度下降法。梯度下降法是**一种迭代式的算法。**梯度下降法的基本思想,就是对loss function求参数的梯度,向梯度下降的方向更新参数:

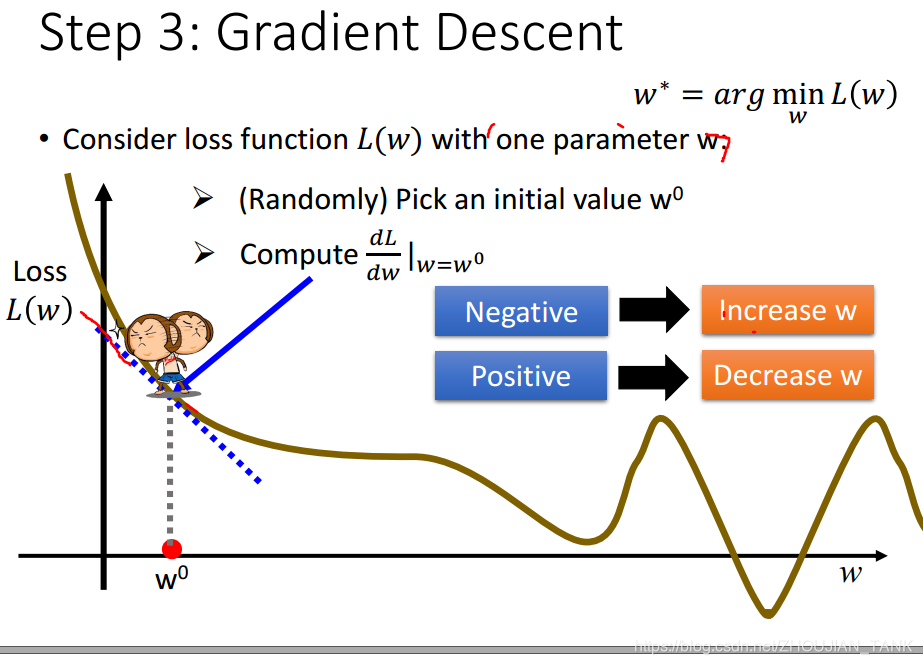

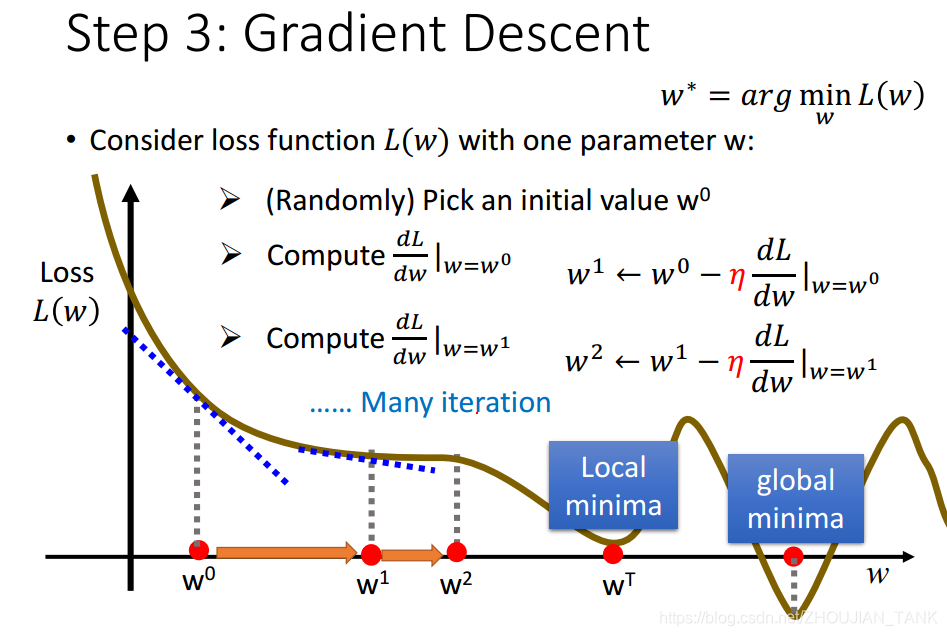

下面对gradient descent进行一定的改进:
(1)自动确定 learning rate:
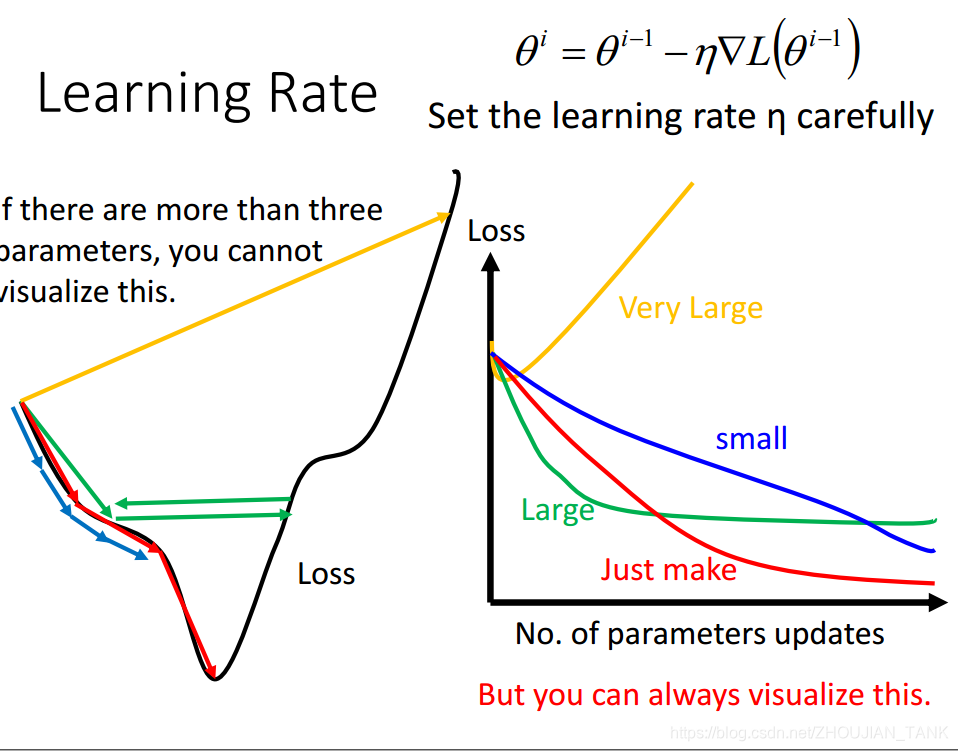
从上图可知,learning rate的选取对 loss function训练参数的最终确定速度是有影响的,当learning rate较小时 ,loss function 下降的速度较慢,当learning rate较大时 ,不易收敛。因此,设计出一种自动确定learning rate的方法。Adagrad

(2)Stochastic Gradient Descent随机梯度下降
一般的梯度下降,计算所有样本的loss function后,update参数
SGD:
- (随机)选择一个样本
- 计算这个样本的loss function,update参数
更新参数更频繁,有助于加速训练

(3)feature scaling**(数据集的归一化)**
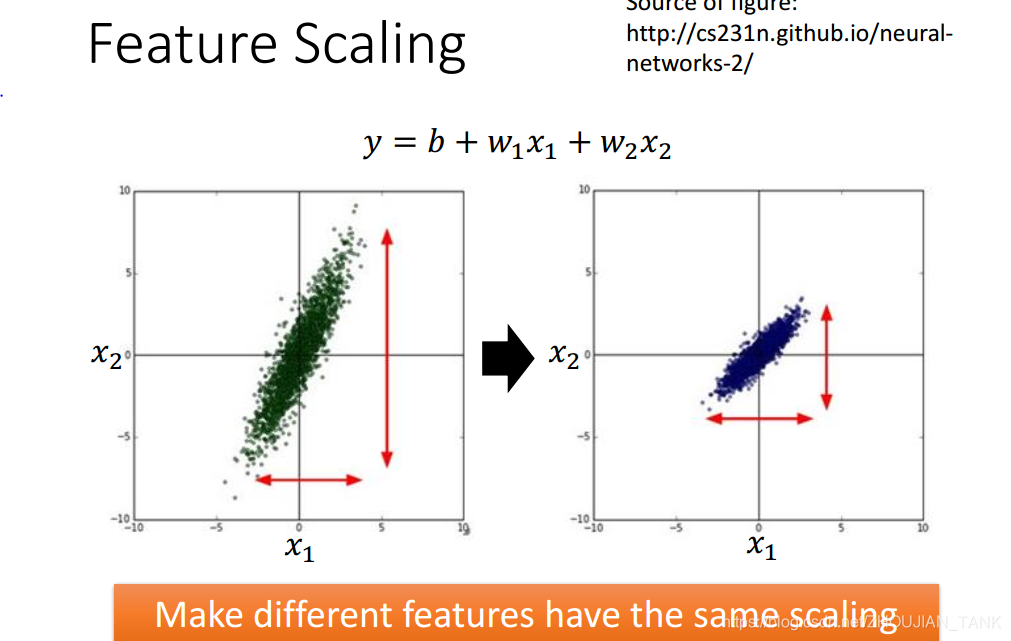
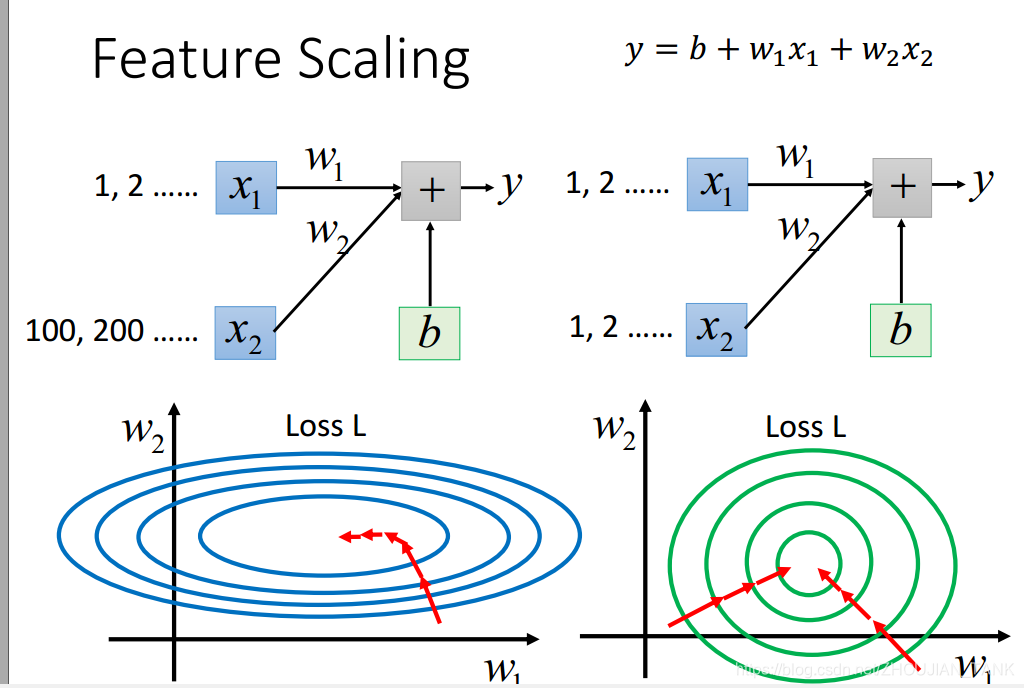
在机器学习中,我们常使用梯度下降法求解最优化问题,在使用梯度下降法时,要注意特征归一化(Feature Scaling).特征归一化有两个明显的好处:
1.提升模型的收敛速度,例如模型只有两个特征x1和x2,x1x1和x2,x1的取值为02000,而x2x2的取值为15,如果对其优化,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向在垂直等高线的方向而走之字形路线,这样迭代速度很降低。如果归一化,会使一个椭圆,梯度的方向为直接指向圆心,迭代速度就会很快。
2.提升模型的精度,这在涉及一些距离计算的算法时效果显著,比如算法要计算欧式距离,上面的x2x2的取值范围较小,计算时对结果的影响远比x1x1带来的小,可能会造成精度的损失.
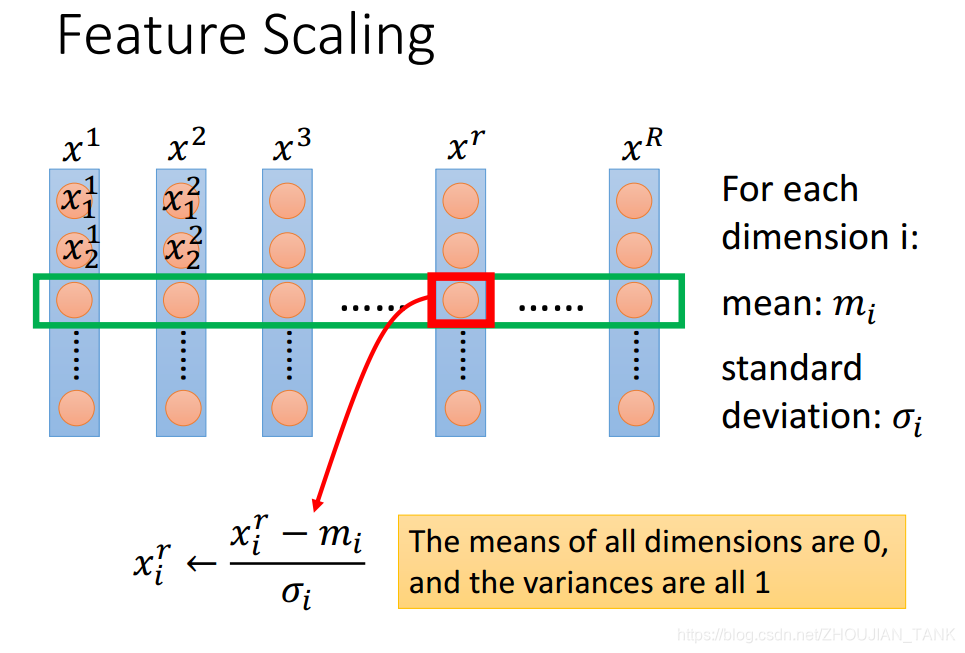
如何实现数据的归一化?
未完,待续 18/11/5
https://blog.csdn.net/u011974639/article/details/77102663
https://blog.csdn.net/ivonui/article/details/79263387