【论文阅读】Learning Spatiotemporal Features with 3D Convolutional Networks
这是一篇15年ICCV的论文,本篇论文提出的C3D卷积网络是3D卷积网络的里程碑,以3D卷积核为基础的3D卷积网络从此发展起来。
论文地址:下载地址
基于pytorch的c3d模型代码:下载地址
简介
文章认为一个有效的视频描述子应该具备以下特点:
- 良好的泛化性(generic)
- 压缩性好(compact)
- 计算效率高(efficient)
- 计算方法简单(simple)
本文首先通过实验说明了3D卷积网络在视频的时空特征提取方面是有效的,然后探索了最优的3D卷积核结构为3x3x3,提出了C3D卷积网络结构,最后在标准数据集上与其他方法做了比较。
正文
3D卷积与2D卷积的区别:
首先论文介绍了3D卷积与2D卷积的区别,如图所示:

从上图中可以看到,图中省略了特征图的channel,所以2D卷积的结果是一张特征图,只包含高和宽,而3D卷积的结果是一个立方体,除了高和宽之外,还包含有时间维度。但是上图没有反映两种卷积核内部的区别,我自己画了下图来更清晰地表达这两种卷积核的内部结构的区别。
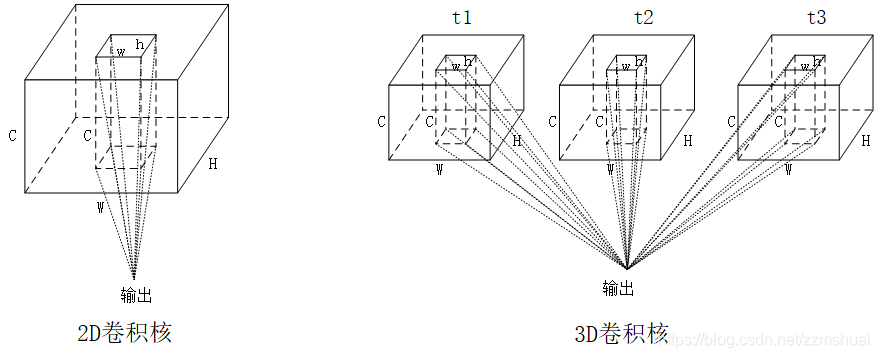 从上图中可以看到,对于2D卷积核,其大小为:
,其中
表示卷积核的通道数,
和
表示卷积核的高和宽。而对于3D卷积核,其大小为:
,其中
为3D卷积核的时间长度。所以3D卷积核与2D卷积核相比,其多了时间维度的卷积。
从上图中可以看到,对于2D卷积核,其大小为:
,其中
表示卷积核的通道数,
和
表示卷积核的高和宽。而对于3D卷积核,其大小为:
,其中
为3D卷积核的时间长度。所以3D卷积核与2D卷积核相比,其多了时间维度的卷积。
最优的3D卷积核尺寸:
然后文章通过实验探索了最优的3D卷积核的尺寸,因为在[1]中表明,当时
尺寸的2D卷积核取得了非常好的效果,所以文章就将3D卷积核的高和宽定位
,通过实验探索卷积核最优的时间深度。同时作者设计了另一个实验:为了设计能更好地组合时间信息的3D卷积网络,作者改变3D卷积网络中不同层的卷积核的时间深度,实验结果如下:
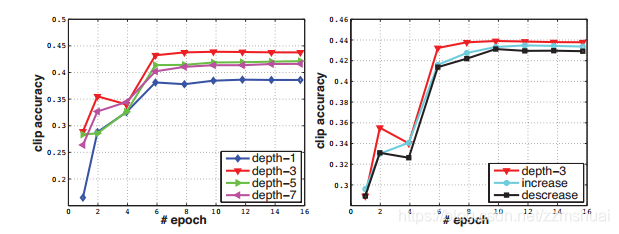
上图是在UCF101上的实验结果,首先看左图,为探索3D卷积核时间深度的实验结果。可以看到作者设置了4种固定尺寸的3D卷积核,分别为 , , , ,实验表明 尺寸的卷积核取得了最优的结果。然后看右图,作者设置3种对比的网络结构,不同层的3D卷积核的时间深度分别为时间深度不变: ,时间深度递增: ,时间深度递减: 。实验结果表明当卷积网络中所有的3D卷积核的时间深度一致,尺寸都为 时,得到的效果最好。
C3D的网络结构
受到当时GPU显存的限制,作者设计了C3D网络结构,如下图所示:

该网络包含8个卷积层,5个池化层,2个全连接层和1个softmax输出层。所有层的3D卷积核的尺寸为
,步长为
。第一层池化层的尺寸为
,步长为
,其余池化层的尺寸为
,步长为
。文章认为不那么过早地池化时间信息,可以在早期阶段保留更多的时间信息。网络的输入的视频长度为16帧,输入的视频帧尺寸为
。
训练细节
在sports-1M数据集上训练时,首先从每一个视频中随机抽取5个2秒长的视频段,然后视频段的每一帧的尺寸被归一化为 ,然后该视频段被随机地裁剪为 作为网络的输入。使用了0.5几率随机水平翻转的数据增强的方法,使用随机梯度下降法来优化,batch size设置为30,初始学习率为0.003,每经过150K次迭代学习率除以2,在第1.9M次迭代(大约13个epoch)的时候停止。
探索性的实验分析
3D卷积网络的反卷积可视化
文章首先根据[2]中提出的反卷积方法,将C3D第5层卷积层得到的feature map 反卷积可视化,如下图所示。

从上图可以看到,文章认为在视频的前几帧,C3D主要关注的是视频帧中的显著性区域,在之后的几帧中会跟踪这些显著变化的区域。其实[3]中也对3D卷积网络的feature map进行了反卷积可视化,可以两个结果对比着看。
个人目前的观点:目前我感觉3D卷积网络对视频中的运动变化区域敏感,但是容易受到复杂影响的干扰,所以需要大量的训练数据使其对object的变化响应。自己的理解也可能有误,如果你有自己的想法和观点,欢迎一起讨论。
C3D描述子
所谓的C3D描述子,就是C3D网络第一个全连接层输出的特征经过L2归一化后的结果,文章对该描述子的做了实验,表明该描述子有良好的压缩性和泛化性。
压缩性
作者使用PCA降维的方法对C3D描述子进行了降维,并与Imagenet特征[4]和iDT特征[5]做了比较,实验结果如下图所示。
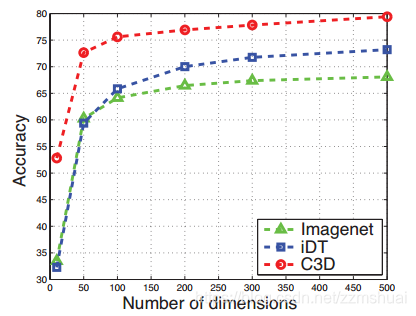
可以发现C3D描述子还是由很好的压缩性的,这对大规模快速视频检索很有帮助。
泛化性
这里没完全看明白,我的理解是从UCF101数据集中随机抽取100K个视频段,然后提取这些视频段的Imagenet特征和C3D特征,对这些特征使用t-SNE降维可视化的方法,如下图所示。
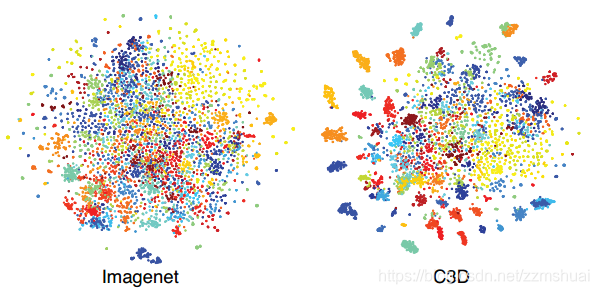
从上图可以看出,C3D特征相同类的特征更加聚集,更容易区分,所以其泛化性更好。
其他
作者技术水平有限,可能会出现一些疏漏,如果您有任何疑问,请联系我。
[1] Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
[2] Zeiler, Matthew D., and Rob Fergus. “Visualizing and understanding convolutional networks.” In European conference on computer vision, pp. 818-833. Springer, Cham, 2014.
[3] Varol, Gül, Ivan Laptev, and Cordelia Schmid. “Long-term temporal convolutions for action recognition.” IEEE transactions on pattern analysis and machine intelligence 40, no. 6 (2018): 1510-1517.
[4]Donahue, Jeff, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. “A deep convolutional activation feature for generic visual recognition. arXiv preprint.” arXiv preprint arXiv:1310.1531 (2013).
[5]Wang, Heng, and Cordelia Schmid. “Action recognition with improved trajectories.” In Proceedings of the IEEE international conference on computer vision, pp. 3551-3558. 2013.