CVPR2016 来自Korea的POSTECH这个团队
大部分算法(例如HCF, DeepLMCF)只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,这些做法证实利用CNN深度特征对跟踪结果有显著提升。
但是毕竟clssification 和 tracking是两个不同的课题
(predicting object class labels VS locating targets of arbitrary classes.)
所以作者设计了一个网络来做跟踪。
出发点:
1、对于跟踪问题来说,CNN应该是由视频跟踪的数据训练得到的更为合理。所有的跟踪目标,虽然类别各不相同,但其实他们应该都存在某种共性,这是需要网络去学的。
2、用跟踪数据来训练很难,因为同一个object,在某个序列中是目标,在另外一个序列中可能就是背景,而且每个序列的目标存在相当大的差异,而且会经历各种挑战,比如遮挡、形变等等。
3、现有的很多训练好的网络主要针对的任务比如目标检测、分类、分割等的网络很大,因为他们要分出很多类别的目标。而在跟踪问题中,一个网络只需要分两类:目标和背景。而且目标一般都相对比较小,那么其实不需要这么大的网络,会增加计算负担。
针对这三点,作者提出了Multi-Domain Network,多域学习的网络结构,来学习这些目标的共性。
什么是multi-domain learning??
训练数据来源于多个domain,domain information被纳入学习过程。是自然语言处理领域一个常见的学习方法(例如用在多个产品的情感分类和多个用户的垃圾邮件过滤等课题中),但很少有人应在计算机视觉领域。
Multi-Domain Network(MDNet)
网络结构
首先来看看MDNet的网络结构:
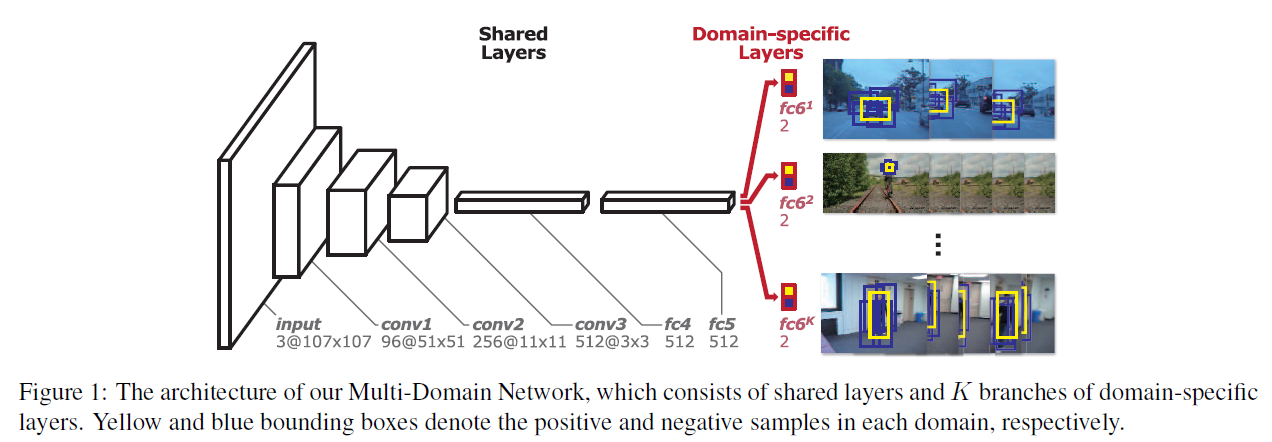
- Input: 网络的输入是107x107的Bounding box,设置为这个尺寸是为了在卷积层conv3能够得到3x3的feature map。
- Convolutional layers: 网络的卷积层conv1-conv3来自于VGG-M [1]网络,只是输入的大小做了改变。
- Fully connected layers: 接下来的两个全连接层fc4,fc5各有512个输出单元,并设计有ReLUs和Dropouts。fc6是一个二分类层(Domain-specific layers),一共有K个,对应K个Branches(即K个不同的视频),每次训练的时候只有对应该视频的fc6被使用,前面的层都是共享的。
tip:卷积层是一个相对通用的特征提取器,而fc层更多的是针对task和数据集的不同进行自适应调整
可以看出,这个网络比clssification重所用的那种AlexNet、VGG-Nets等小很多,这也契合作者的第三条出发点:现有的很多训练好的网络主要针对的任务比如目标检测、分类、分割等的网络很大,因为他们要分出很多类别的目标。而在跟踪问题中,一个网络只需要分两类:目标和背景。而且目标一般都相对比较小,那么其实不需要这么大的网络,会增加计算负担。
这里再来强调一下小网络在tracking中的适用性:
1、tracking旨在区分目标和背景两个类别,这比目前一般的视觉识别问题(如1000类的ImageNet分类)要求的模型复杂程度少得多。
2、深度CNN对于精确目标定位的效果较差,因为随着网络的深入,空间信息往往会被淡化。
3、在跟踪任务中通常目标较小,所以输入大小(input size)也就小,网络结构自然也就更浅。
4、跟踪通常是一个实时任务,一个较小的网络在跟踪问题上明显更有效率,训练和测试都可以在线进行的。 当我们测试更大的网络时,算法不太准确,并且变得更慢。
那么这个和多域学习有关的Domain-specific layers到底是如何训练的呢?又是如何能够学习跟踪目标的共性,从而契合第一条出发点(所有的跟踪目标,虽然类别各不相同,但其实他们应该都存在某种共性,这是需要网络去学的。)呢?
算法的目标是训练一个 multi-domain CNN 以在任何 domain 辨别 target 和 background。这并非很直观,因为来源不同 domain的 train data 拥有不同的 target 和 background 的定义。但是,这其中仍然存在着一些共同的属性,如:对光照变化,运动模糊,尺寸变化的鲁棒性等等。为了提取出满足上述属性的特征,作者通过 multi-domain learning framework,从 domain-specific 的信息中分离出 domain-independent 的信息。
为了学到不同视频中目标的共性,采用Domain-specific的训练方式:假设用K个视频来做训练,一共做N次循环。每一个mini-batch的构成是从某一视频中随机采8帧图片,在这8帧图片上随机采32个正样本和96个负样本,即每个mini-batch由某一个视频的128个框来构成。在每一次循环中,会做K次迭代,依次用K个视频的mini-batch来做训练,重复进行N次循环。用SGD进行训练,每个视频会对应自己的fc6层。通过这样的训练来学得各个视频中目标的共性。
训练好的网络在做test的时候,会新建一个fc6层,在线fine-tune fc4-fc6层,卷积层保持不变。
用MDNet来做跟踪
网络在线更新策略
采用long-term和short-term两种更新方式。
这考虑了两个互补的方面,即:robustness 和 adaptiveness。
Long-term update 是按照常规间隔后进行更新。
short-term updates 当出现潜在的跟踪失败的时候进行更新,此处潜在的跟踪失败是指:预测目标的positive score 小于 0.5。在跟踪的过程当中,我们保持一个单独的网络,这两种更新的执行依赖于物体外观变化的速度。
long-term对应历史的100个样本(超过100个抛弃最早的),固定时间间隔做一次网络的更新(程序中设置为每8帧更新一次),short-term对应20个(超过20个抛弃最早的),在目标得分低于0.5进行更新。负样本都是用short-term的方式收集的(因为旧的负样本往往是冗余的或与当前帧无关。)。
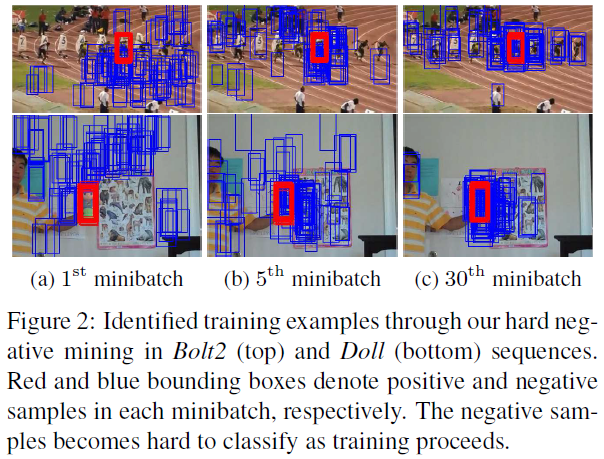
另外在训练中负样本的生成用到了hard negative mining,就是让负样本越来越难分,从而使得网络的判别能力越来越强。
可以看下图,负样本越来越hard negative:(作者称这个步骤叫做Hard Minibatch Mining)
目标跟踪
每次新来一帧图片,以上一帧的目标位置为中心,用多维高斯分布(宽,高,尺度三个维度)的形式进行采样256个candidates,将他们大小统一为107x107后,分别作为网络的输入进行计算。
网络的输出是一个二维的向量,分别表示输入的bounding box对应目标和背景的概率。目标最终是确定为目标得分概率最高的那个bounding box:
最后得到的candidate其实不是直接作为目标,还要做一步bounding box regression。作者说bounding box regression涉及到的细节与R-CNN一样。这一步对最后的结果贡献还是有的,可以看下面的实验结果。
the single domain learning method (SDNet), where the network is trained with a single branch using the data from multiple sequences.
MDNet without bounding box regression (MDNet–BB)
MDNet without bounding box regression and hard negative mining (MDNet–BB–HM).
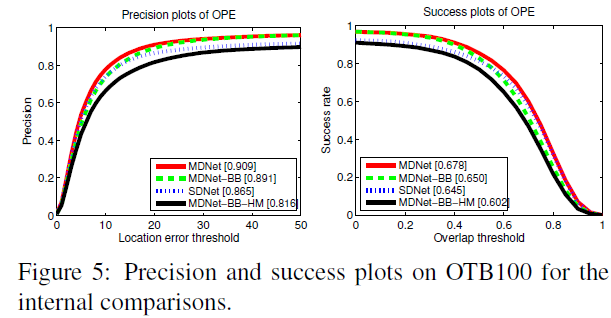
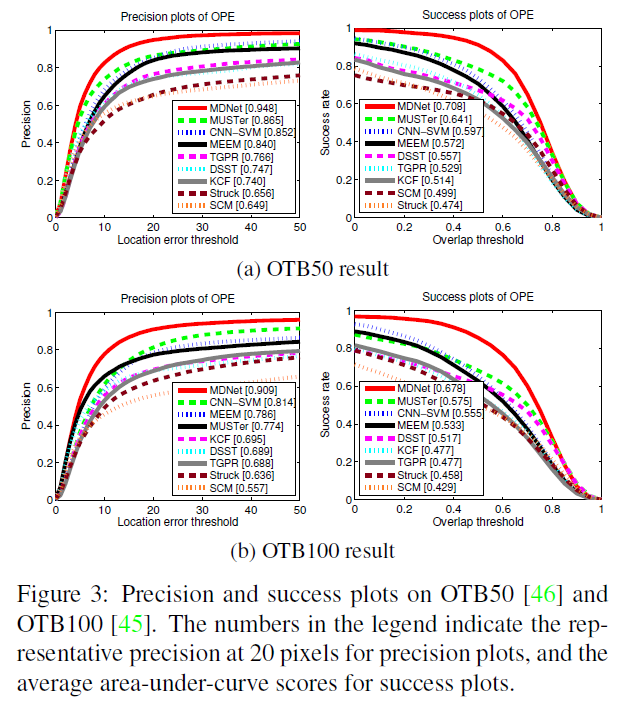
总结一下MDNet效果好的原因:(摘自博客)
- 用了CNN特征,并且是专门为了tracking设计的网络,用tracking的数据集做了训练
- 有做在线的微调fine-tune,这一点虽然使得速度慢,但是对结果很重要
- Candidates的采样同时也考虑到了尺度,使得对尺度变化的视频也相对鲁棒
- Hard negative mining和bounding box regression这两个策略的使用,使得结果更加精确
整体流程:

整体效果:
跑代码:
