介绍
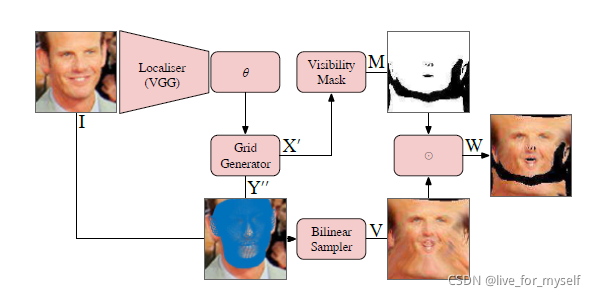
这篇论文展示了如何使用一个3d morphable model as a STN, 在这种情况下, 输入图像被重新采样的位置是由2D projection of a 3D deformable mesh 决定的。因此论文的3DMM-STN对3d shape和pose同时进行了估计。 对应网络的输出是一个resampled image in a flattened 2D texture sapce, 其中图像是密集的, 像素级的对应关系。因此这个输出可以送入后续的CNN进一步处理。 (我们的3DMM-STN的输出是对原始图像的二维重采样,它包含了人脸中所有的高频、可辨别的细节,而不是基于模型的重建,它只捕获了可由3DMM解释的外观的粗略、低频方面。)
- STN是spatial transformer network
3DMM-STN
原来的STN是这样的:
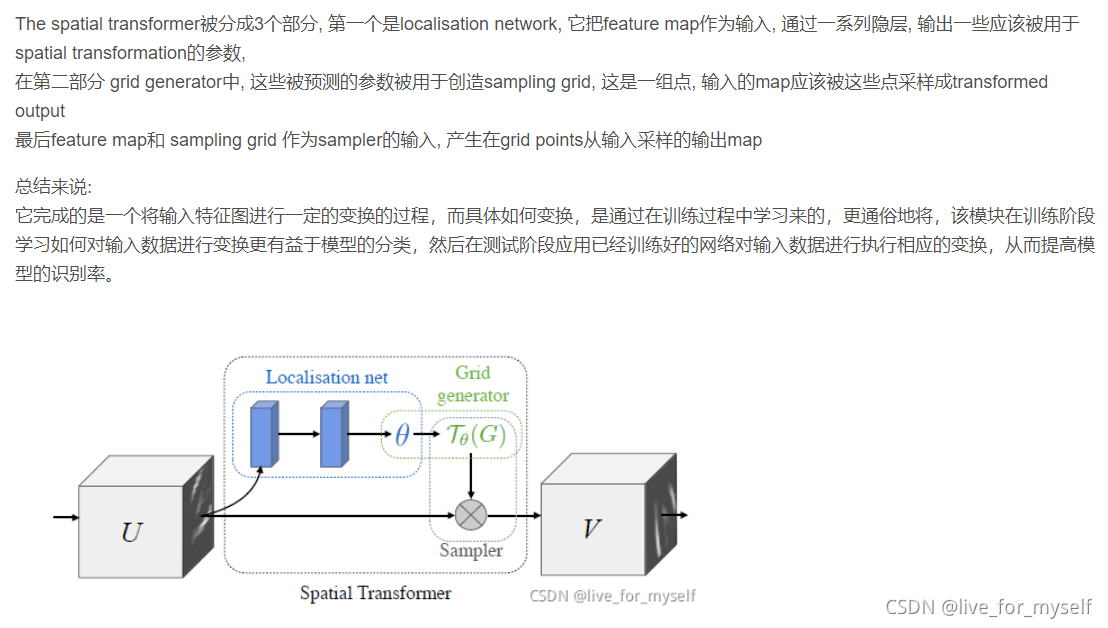
然后经过一些改进, 就可以适用于3DMM任务
Localiser network
这里改动了localisation net。
localiser network 是一个使用image作为输入然后回归出shape和pose 参数 θ \theta θ的CNN
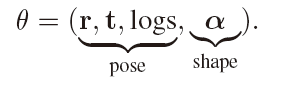

Grid generator network
同样这里也有变化, 因为上一步得到是一些人脸仿射变换的 θ \theta θ, 然后应用一些对3d mesh的transformation 和投影, intensities是从原图sample而来的, 然后把采样的强度分配给一个扁平化的二维网格中的相应点。
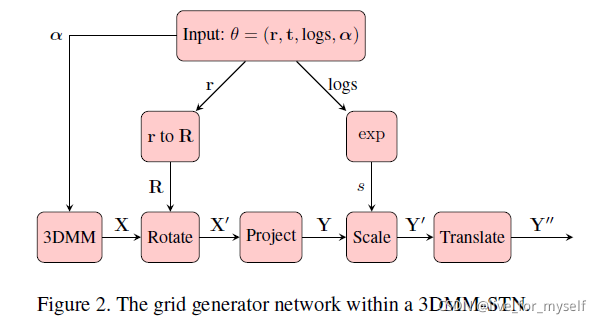
-
首先对前面得到 θ \theta θ经过3DMM层, 通过 θ \theta θ中的shape相关部分产生形状参数 X X X,
X是一些3d点:
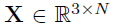
这里不太清除P是啥

得到形状参数
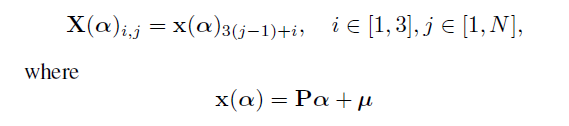
-
然后是旋转
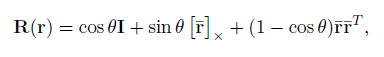
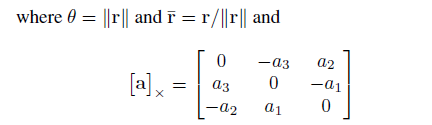
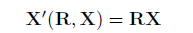
-
再是正交投影, 缩放, 平移
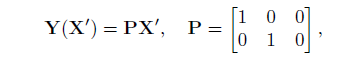

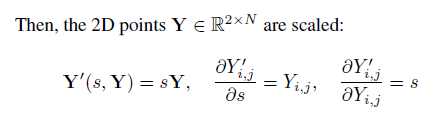
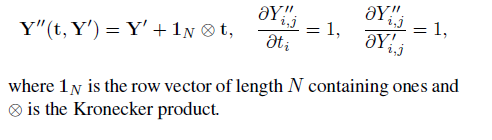
Sampling
原来的STN使用双线性采样, 从输入图像中取值然后变换到输出的grid中。 这里做的改动是把输出grid是一个texture space flattening of the 3DMM mesh。 第二双线性采样器会错误把face的一部分采样到self-occluded顶点上, 因此我们引入了额外的层, 计算哪些顶点是遮挡的,并对采样的图像进行适当的屏蔽。
output grid
STN的目的是将输入图像转化为规范的、姿势正常化的视图。在三维模型的背景下,我们可以想象有许多类似的方式可以对输入图像进行标准化处理。例如,STN的输出可以是rendering of the
mean face shape in a frontal pose with the sampled texture
on the mesh
相反,我们选择在一个二维嵌入中输出采样的纹理,(Instead, we choose to output sampled textures in a 2D embedding obtained by flattening the mean shape of the 3DMM.)这个二维嵌入是通过平坦化3DMM的平均形状得到的。这确保了输出的图像相对于平均形状来说是近似面积均匀的,而且整个输出的图像包含人脸信息
-
总体架构
-
有点想放弃了, 因为3d的确很难