上一篇博客中,EmotiW 2016竞赛获胜者论文的很多实验参数都选自这篇论文。
Introduction
视频数据分析是个很重要的工作,但也是个难题,难点就在于如何有效地提取视频表征,尤其是视频序列中的运动信息。在该问题上急需寻找一种通用的视频描述符来以一种相似的方式解决大规模的视频任务,该种描述符必须满足generic、compact、simple和efficient的特点。本文即是希望寻找 3D 卷积网络中的最优滤波器结构,尤其是最优卷积核深度。
Model
1. 2D卷积与3D卷积
本文主要采用了3D卷积搭建模型完成多个视频任务,包括行为识别,动作相似性标记,场景和对象识别和运动时分析。3D与2D卷积不同点在于:如果在一张图片或多张图片上执行2D卷积操作,输出都为一张图片,由此在2D卷积操作后会丢失输入图片间的时间信息;而3D卷积对表象和运动信息同时建模,有效保留了视频中的时序信息,输出为一个output volume。2D与3D操作的对比图如图1所示。图1b与图1c的区别就在于卷积核选取的深度,b中卷积核深度与图片帧数相同,都为L,所以卷积操作的输出还是2D。

图1 2D与3D对比图
2. 在小数据集UCF101实验结果
本文希望先在一个小数据集下找到最佳的卷积核深度,再去探究找到的深度d是否也适用与其他的视频任务。
Notations:假定输入的短视频剪辑大小为c × l × h × w,其中c为图片通道数,l是选取的图片帧数,h和w为静态图片帧的高度和宽度。假定3D卷积核和采样核大小为d× k × k,d为核的时间深度,k为核的空间大小。
Common network setting:具体而言,对于UCF101数据集,先从每个视频中提取16个不重叠的静态图片帧作为输入,再将每一帧图片大小调整为128×171,由此网络的原始输入为3×16×128 × 171,经随机裁剪后输入变为3×16×112 × 112。搭建的3D CNN网络有5个卷积层、5个下采样层、2个全连接层和1个softmax分类层,1-5层中每层的卷积核个数为64、128、256、256和256。每个卷积层都设置合适的padding,使得卷积前后输入输出的大小相同。除第一个下采样层外,其余下采样层的核都设置为2×2×2,步长设置为1,这意味着每经一个下采样层,输出大小为该层输入的1/8。第一个下采样层的核大小设置为1 × 2 × 2,主要因为一共仅选取了16帧图片,第一层时序维度设为1可防止时序信息过早的被合并。
其他一些参数: 两个全连接层都有2048维输出,batchsize=30,表明一次选取30个视频,初始学习速率为0.003,每赐个周期学习速率下降为原来的1/10,一共训练16个周期。
varying network architectures:沿用常规2D CNN网络卷积核选取的思路,本文将卷积核的空间大小固定为3×3,仅变化核深度di。文章探究了两种结构:1)所有卷积层都有相同的di;2)di在不同层变化。
对于结构1:测试四种方案,di分别为1,3,5,7,其中di=1时网络相当于执行2D卷积;
对于结构2:测试两种方案,di在不同层分别为:3-3-5-5-7和7-5-5-3-3。
不同方案下网络参数数量不同,但参数数量的变动较小,对结果没有影响。在UCF101数据集上测试结果如图2所示。左图曲线表示结构1的分类结果,观察发现depth-1网络明显比其他网络性能差,因为它缺少了对运动信息的建模。右图曲线表示结构2的分类结果,观察结果发现所有层卷积核深度固定为3时,在两种结构中都取得了最优结果。
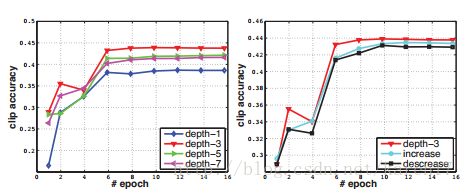
图2 不同核深度的分类性能比较
Experiment
1. 基本结构
实验发现在较小一点数据集下,3*3*3的卷积核是最优核。对于较大的数据集,搭建了8层卷积层、5层下采样曾、2层全连接层和1个softmax分类层的网络来进行测试,网络结构如图3所示。网络中所有的卷积核大小都为3*3*3,步长为1*1*1,除第一层外所有下采样层的核大小都为2*2*2,步长为2*2*2,第一层核与步长都为1*2*2。

图3 C3D结构
2. 数据集:Sports-1M
3. Training

4. what does C3D learn?
我们观察到,C3D刚开始在前几帧中关注外观信息,而在随后的帧中追踪明显的运动,如图4所示。在第一个例子中,特征首先聚焦于整个人,然后在其余的帧上跟踪撑杆跳的运动;同样,在第二个例子中,特征首先聚焦于眼睛,随后跟踪眼睛周围发生的运动。

图4 C3D可视化示例
Conclusion
1.最后作者用提出的3*3*3的卷积核在action recognition,action similarity labeling和scene and object recognition 中都取得了不错的成绩。
2.论文《3D Convolutional Neural Networks forHuman Action Recognition》首先提出将3D ConvNet应用于行为识别任务中。本文较该论文探讨的更为深入,一方面为3D ConvNet找到最佳的卷积核深度,并在多种视频识别任务中验证了该种卷积核的有效性;另一方面在诸多任务上验证了3D卷积网络确实可较好的表示表象和运动信息,将3D ConvNet提取的特征输入SVM中得到的结果优于或接近当前最好的方法。