1、Contribution
- we propose a two-stream ConvNet architecture which incorporates spatial and temporal networks
- demonstrate that a ConvNet trained on multi-frame dense optical flow is able to achieve very good performance in spite of limited training data.
- show that multitask learning, applied to two different action classification datasets, can be used to increase the amount of training data and improve the performance on both.
2、Introduction
文章的 Introduction 主要围绕这几方面展开:
- Why Recognition of human actions in videos has received a significant amount of attention?
- temporal information & natural data augmentation
- How to do the AR in the past?
- Traditionally, design some hand-crafted features (HOF、HOG); Stacking frames directly as channels feed into the network(do not capture the motion well)
- Theoretical Basis: two-streams hypothesis
- human visual cortex contains two pathways: the ventral stream (which performs object recognition) and the dorsal stream (which recognises motion);
3、Network Architecture
截图自 https://www.jianshu.com/p/e5156a67c71d

4、Optical Flow input configurations


5、Multi-task learning
论文中提到 Data Augmentation 的两个 Options:
- add the images from the classes, which do not appear in the original dataset
- Multi-task learning:learn a (video) representation, which is applicable not only to the task in question (such as HMDB-51 classification), but also to other tasks (e.g. UCF-101 classification). In our case, a ConvNet architecture is modified so that it has two softmax classification layers on top of the last fully-connected layer: one softmax layer computes HMDB-51 classification scores, the other one – the UCF-101 scores. Each of the layers is equipped with its own loss function, which operates only on the videos, coming from the respective dataset. The overall training loss is computed as the sum of the individual tasks’ losses, and the network weight derivatives can be found by back-propagation.
-
补充阅读:到底什么是 Multi-task learning?
参考阅读 1:
现在大多数机器学习任务都是单任务学习。对于复杂的问题,也可以分解为简单且相互独立的子问题来单独解决,然后再合并结果,得到最初复杂问题的结果。
这样做看似合理,其实是不正确的,因为现实世界中很多问题不能分解为一个一个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。
把现实问题当做一个个独立的单任务处理,忽略了问题之间所富含的丰富的关联信息。多任务学习就是为了解决这个问题而诞生的。多个任务之间共享一些因素,它们可以在学习过程中,共享它们所学到的信息,这是单任务学习所不具备的。相关联的多任务学习比单任务学习能去的更好的泛化(generalization)效果。
单任务学习时,各个任务之间的模型空间(Trained Model)是相互独立的(图1上)。多任务学习时,多个任务之间的模型空间(Trained Model)是共享的。
单任务学习时,各个task任务的学习是相互独立的,多任务学习时,多个任务之间的浅层表示共享。

参考阅读 2:
Alternate Training
TensorFlow 实现:
Training at the Same Time - Joint Training
TensorFlow 实现:




6、Further Reading 1:What makes motion such a useful feature for video classification?
参考:
论文: On the Integration of Optical Flow and Action Recognition
论文讲解: https://blog.csdn.net/elaine_bao/article/details/80891173
结论:
Optical flow is useful for action recognition as it is invariant to appearance, even when temporal coherence is not maintained.
光流中真正包含的最重要的信息是表观不变性(Invariant to Appearance)。
当运动的轨迹被破坏了,总的 acc 还是很高(shuffled flow fields, 78.64%)。这说明连贯的时序轨迹并不是光流最重要的特征。
那即使是上面提到的 shuffled flow fields,也还是包含了 temporal 的信息,因为单帧的光流本身也是通过两张相邻的帧计算出来的。为此,我们将用于提光流的RGB图片也做了 shuffle,这样的话得到的光流就和物理上的运动没有关系了,但是它仍然包含运动物体的形状。如表1所示,这时候的acc下降到了59.5%(shuffled images),虽然这已经是一个比较大的变化了,但是它还是比随机猜(~1%)的概率要高很多,这说明光流的大部分的 acc 可能不是从 motion 得到的。
We argue that instead much of the value of optical flow is that it is invariant to the appearance of the input images, resulting in a simpler learning problem as less variance needs to be captured by the action recognition network.
为了验证上述想法,通过将UCF101的colormap进行变化进行实验。具体地,首先将 RGB 图片转成灰度图,然后再随机 sample 到某种 colormap 如 jet,brg,hsv 等,将其再转成彩色,如图2的例子。观察 acc 的变化,如表1所示,我们发现对于RGB来说,虽然人眼来看 altered colormap 并没有什么画面上的变化,但是模型的结果看 acc 下降了50%,而对于 flow 来说,altered colormap 没什么大的影响。

7、Further Reading 2:How to calculate the Optical Flow ?
论文:Determining Optical Flow
参考:
- https://blog.csdn.net/qq_41368247/article/details/82562165
- https://blog.csdn.net/qq_42463478/article/details/81183517?utm_source=blogxgwz8
- https://www.mathworks.com/help/vision/ref/opticalflowhs.html
- https://blog.csdn.net/u012841922/article/details/85274061
- https://blog.csdn.net/u012841922/article/details/85273852
Constraint 1:Brightness Constraint
考虑一个像素I(x,y,t)在第一帧的光强度(其中t代表其所在的时间维度)。它移动了 (dx,dy) 的距离到下一帧,用了dt时间。因为是同一个像素点,依据上文提到的第一个假设我们认为该像素在运动前后的光强度是不变的


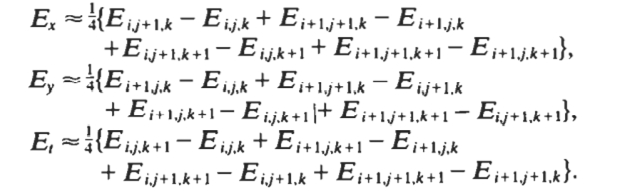

Constraint 2:Smoothness Constraint
neighboring points on the objects have similar velocities and the velocity field of the brightness patterns in the image varies smoothly almost everywhere.
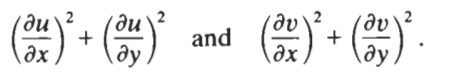
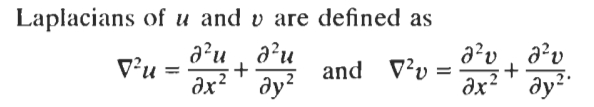


Minimization
![]()
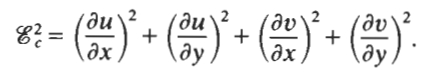
Matlab 计算过程

8、Datasets
- UCF-101: https://blog.csdn.net/hehuaiyuyu/article/details/107052599
- UCF101是一个现实动作视频的动作识别数据集,收集自 YouTube,提供了来自101个动作类别的13320个视频。
- UCF101在动作方面提供了最大的多样性,并且在摄像机运动、对象外观和姿态、对象规模、视点、杂乱的背景、照明条件等方面有很大的变化。
- 101个动作类别中的视频被分成25组,每组可以包含一个动作的4-7个视频。同一组的视频可能有一些共同的特点,比如相似的背景,相似的观点等等。
- 包括5大类动作 : 人与物体交互 单纯的肢体动作 人与人交互 演奏乐器 体育运动
- 这些类别有:化眼妆、涂唇膏、射箭、婴儿爬行、平衡木、乐队游行、棒球、打篮球、扣篮、卧推、骑自行车、台球、吹干头发、吹蜡烛、下蹲、保龄球、拳击、出气筒、蛙泳、刷牙、挺举、悬崖跳水、保龄球、板球、潜水、打鼓、击剑、曲棍球、体操、飞盘、爬泳、高尔夫挥杆、理发、扔链球、锤击、倒立俯卧撑…
- 注意:在训练和测试时,将属于同一组的视频分开是非常重要的。由于一组视频是由单个的长视频获得的,因此在训练和测试集中共享同一组的视频会获得较高的性能。
- HMDB 51: https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/
- Here we introduce HMDB collected from various sources, mostly from movies, and a small proportion from public databases such as the Prelinger archive, YouTube and Google videos. The dataset contains 6849 clips divided into 51 action categories, each containing a minimum of 101 clips. The actions categories can be grouped in five types:
- General facial actions smile, laugh, chew, talk.
- Facial actions with object manipulation: smoke, eat, drink.
- General body movements: cartwheel, clap hands, climb, climb stairs, dive, fall on the floor, backhand flip, handstand, jump, pull up, push up, run, sit down, sit up, somersault, stand up, turn, walk, wave.
- Body movements with object interaction: brush hair, catch, draw sword, dribble, golf, hit something, kick ball, pick, pour, push something, ride bike, ride horse, shoot ball, shoot bow, shoot gun, swing baseball bat, sword exercise, throw.
- Body movements for human interaction: fencing, hug, kick someone, kiss, punch, shake hands, sword fight.
- Here we introduce HMDB collected from various sources, mostly from movies, and a small proportion from public databases such as the Prelinger archive, YouTube and Google videos. The dataset contains 6849 clips divided into 51 action categories, each containing a minimum of 101 clips. The actions categories can be grouped in five types: