目录
Convolutional-De-Convolutional(CDC)networks
downsampling 和 upsampling 的必要性
Design of CDC network architecture
写在前面
这是接触的第一篇时序动作定位相关的论文,可能需要补充一些检测相关的知识。
论文名称:CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos
下载地址:https://arxiv.org/pdf/1703.01515.pdf
代码(Caffe):https://bitbucket.org/columbiadvmm/cdc/src/master/
project website:https://www.ee.columbia.edu/ln/dvmm/researchProjects/cdc/cdc.html
Abstract
时序动作定位(Temporal Action Localization)除了要对动作进行分类,还要找到动作发生的起始时间点和结束时间点。
作者提出以往的方法细粒度(granularity)不够高,都是 segment level 的,作者提出时序动作定位要更精细(frame-level)。
于是,作者提出 Convolutional-De-Convolutional(CDC)网络:在 C3D 网络(可参考:https://blog.csdn.net/qq_36627158/article/details/112576527)上放几层 CDC filters。提出的 CDC filters 可以同时在时序维度上进行上采样,在空间维度上进行下采样。以此达到在 frame-level 细粒度上进行预测动作的任务。
CDC 模型可以进行端到端地训练,而且非常 efficient(在一块 12G 的 GPU 上 1s 可以处理 500 frames)。
Introduction
经典的框架都是在 sliding windows 或者 segment proposal 上提取大量特征,并训练分类器。其中,Segment-CNN(S-CNN)包含:(1)proposal network:产生候选 video segments (2)localization network:预测 segment-level 的动作分类分数。 其缺陷在于:该方法检测的动作时序边界受限于 proposal segments 预先定义好的边界。
所以,这篇论文的主要目标:对 proposal segments 里 action instance 的 temporal boundaries 进行更进一步的 refinement 。
由于 S-CNN 是 segment-level 的,不能直接对其进行 frame-level 的 refinement。所以,作者有考虑过一些已有的方法:(1)Single-frame classifiers operate on each frame individually (2) Recurrent Neural Networks (RNN) further take into account temporal dependencies across frames. 但这些方法都不能直接从原始的视频中显式的提取 spatio-temporal information。
作者决定采用另一种方法:3D CNN 确实可以直接从原始的视频中直接学习到 spatio-temporal 的高层次的语义信息,但也丢失了时间维度上的细粒度。如下图,一段视频从 C3D 框架的 conv1a 层到 conv5b 层后,时序长度直接变为原来的 1/8.【详细参考https://blog.csdn.net/qq_36627158/article/details/112576527】
为了解决丢失时间维度上细粒度的问题,作者参考了一种在像素级别上语义分割非常有效的方法:de-convolution。它是一种能把 output up-sample 到和 input 同样分辨率的方法。【待深入了解】
那如果想使用 3D CNN 的方法来做时序动作定位的话,网络的输出需要在时序维度上上采样到和输入一样长,在空间维度上需要下采样到 1 1,于是作者就提出了 CDC filters:一种能在时序维度上上采样,同时在空间维度上下采样的方法。
那么,在 3D ConvNet 上堆叠几层 CDC layers 就形成了 CDC network。
总的来说,这篇论文的贡献如下:
- 这是第一个将两个相反的操作(convolution 和 de-convolution)结合成一个 CDC filter 的工作,它可以在时序维度上上采样,同时在空间维度上下采样。这样既可以得到高层次的动作语义信息,又可以在时序维度上达到一个更精细的细粒度。
- 用提出的 CDC filter 构建了一个 CDC network,它可以从原始视频直接产生密集的(以帧为细粒度)分数,以此进行端到端的训练。其中,以帧为细粒度的密集分数可以用来得到一个动作实例更精准的时间界限。
- CDC model 在视频单帧动作标记的任务上超越了许多 sota,同时还大大增加了时序动作定位的准确度。
Related Work
- Action recognition and detection. 【略】这一块看得比较多了,其中,spatial-temporal action detection 应该是我看完 temporal action localization 的下一步:
There are also studies on spatio-temporal action detection, which aim to detect action regions with bounding boxes over consecutive frames. Various methods have been developed, from the perspective of supervoxel merging [20, 54, 55], tracking [69, 42, 62, 52], object detection and linking [28, 14, 75, 42, 62], spatio-temporal segmenta- tion [31, 70], and leveraging still images [21, 58, 22].
- Temporal action localization【可重点了解,作为后续重点阅读、了解 temporal action localization 的参考文献】
首先是 Gaidon et al. [11, 12] 引入了 temporal action localization 这个问题。
再接着有学者根据这个问题构建的数据集:THUMOS、MEXaction2
经典(传统)方法:[67, 53, 39, 65, 26] is extracting a pool of features, which are fed to train SVM classifiers, and then applying these classifiers on sliding windows or segment proposals for prediction.
深度学习相关方法:RNN、LSTM [9、73、72、76、59、31]、Shou et al. [47] proposed an end-to-end Segment-based 3D CNN framework (S-CNN)
- De-convolution and semantic segmentation
最初是 Zeiler 等人 [78、77] 提出的 deconvolution【刚好上回看的 ZFNet 就是他的:https://blog.csdn.net/qq_36627158/article/details/113626345】.
后面 Long 等人 [34, 45] 用在了图像语义分割上。
最近,Tran 等人 [61] 把 de-convolution 从 2D 延伸到 3D 上。本篇论文和他们的不同就是:本篇论文虽然在 time 上 up-sampling,但 space 上还是要保持 down-sampling 的。
Convolutional-De-Convolutional(CDC)networks
downsampling 和 upsampling 的必要性
由于 C3D 的出色表现,作者使用 C3D 的 conv1a 到 conv5b 层作为 CDC 网络的第一个部分。作者继续保留 pool5 层,对 spatial 的高、宽继续执行 max-pooling,但保持 temporal length 不变。
输入:112 112,对给定时序长度 L 的 input video,pool5 层的输出尺寸为:(512,L/8,4,4).
那么,为了能在原时序分辨率上对动作进行分数的预测,需要在时间维度上 up-sample(L/8 → L),在空间维度上 down-sample(4 4 → 1
1)

CDC filter
作者用了一个具体的例子说明如何 CDC filter 如何进行操作。
- 如果将 C3D 网络中的 FC6 直接转换成 conv6,如下图中的(a),conv6 确实在空间维度上将 4
4 down-sample 成了 1
- 接着,为了在时序维度上 up-sample,一种简单直接的方法就是像图(b)一样,在 conv6 层后多接一个 deconv6 层。但这种 up-sampling 和 down-sampling 是分开的。
- 于是,作者提出了像图(c)一样的 CDC filter,它包含了 2 个在同一个 4
作者认为(b)(c)的区别:(c)在时间维度上的每个输出来自于一个独立的卷积核,而(b)在时间维度上的每个输出都是共享着相同的高级语义信息。

CDC filter:
假设 CDC filter 的 kernel size 为(,
,
),意思是对输入 X 中高为
、宽为
的感受野进行相应的 CDC 操作,得到在时间维度上连续
个输出值 Y。图(c)的
=
= 4,
= 2。

反向传播时,梯度为:
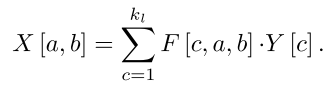
Design of CDC network architecture
【注意,CDC6 层中的 CDC filter = 4,也就是说,每个 4
4 的 feature map 会得到 4 个 output node。但作者设置 stride = 2,也就是说每连续两个 feature maps 会有两个 output node 重叠,CDC6 的时序长度还是从 L/8 上采样到 L/4,每个 ouput node 是连续两个 input feature map 的加和。】

如图,CDC 网络的最后输出形状是(K+1,L,1,1),其中 K 是动作的类别数,+1 是因为还要算上一类不是动作的背景类别。
最后,CDC8 的输出将送入一个 frame-wise 的 softmax layer,以此得到每一帧的动作分类分数。
在有 N 个training segments 的 mini-batch 中,对于其中的第 n 个 segment,CDC8 的输出 的形状为(K+1,L,1,1)。针对某一个 segment 中的某一帧 t,
和 Softmax 输出
都是 K+1 维的向量。
那么,某一个 segment 中某一帧 t 属于某个类别 i 的概率就为:
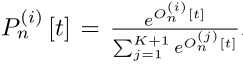 。
。
这个 mini-batch 的 Loss Function:
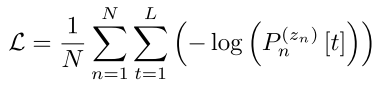
Training and prediction
Training data construction:
由于 GPU 的限制,我们将视频切分为一个个没有 overlap 的 32 帧小视频(但理论上 CDC networks 是可以喂入不固定长度的视频),丢入 CDC 网络中进行时间维度上的密集预测训练。 为了阻止数据包含太多背景帧,我们只对“至少包含一张属于某个类别”的小视频进行训练。
Fine-grained prediction and precise localization:
丢给模型一整段视频,模型可以给出每一帧的动作类别分数,然后再设定 confidence score,并把拥有相同标签且相邻的帧 group 起来,就可以对视频进行时序动作定位了,但这种很容易受到噪声影响。
于是作者利用【47、9 等】方法先产生一些高 recall 的候选片段(proposal segment),对这些 proposal segment 的两端进行 1/8 长度的延长,然后像训练数据的构建一样,用一个没有 overlap 的窗口对 extended proposal segment 进行滑动切分(也是保证这些切分好的视频至少包含 extended proposal segment 里的一帧)得到 windows,再将这些 windows 送入 CDC 网络中,得到每一帧的动作类别分数。
接着,(1)proposal segment 的动作分类:proposal segment 中所有帧的动作类别分数按照类别相加,分数最高的一个类别就是这个 proposal segment 最后的动作类别(prediced class)。
(2)proposal segment 的动作定位:取出片段中所有帧的 prediced class 这一类的分数,用高斯核密度估计得到这组分数的平均值 u 和标准差 σ。然后从 extended proposal segment 的两端开始往中间 shrink,直到碰到 confidence score 不低于 u-σ 的那一帧,形成 refined proposal segment。最后这个 segment 的 prediction score 就为 refined proposal segment 中所有帧 prediced class 这一类分数的平均值。

Experiments
Per-frame labeling
THUMOS' 14 数据集评价标准:https://www.crcv.ucf.edu/THUMOS14/THUMOS14_Evaluation.pdf

本篇文章在 THUMOS' 14 数据集上 per-frame labelling 的结果:

Temporal action localization
评价指标:除了类别分对,temporal overlap IoU 也要超过设定的阈值才算定位准确
结果:

Discussion
The necessity of predicting at a fine granularity in time:

括号里的数字依次表示为 CDC6、7、8 分别在时序维度上 up-sample 几倍。
Efficiency analysis:
- compact:1GB storage
- fast:500 FPS on a 12GB GPU
Temporal activity localization:
作者发现这个方法在定位有着高级语义且复杂的活动时,也非常有用。他们在 ActivityNet Challenge 2016 数据集上做了实验:对当年第一名方法的结果使用 CDC 网络来进行更精准的边界定位。下表是使用 CDC 网络来进行更精准边界定位的前后的效果:

Future Reading
- Related Work 中的 Temporal action localization