Action Genome 是第一个同时提供动作标签和时空场景图标签的大型视频数据库。
论文地址:https://arxiv.org/pdf/1912.06992.pdf
GitHub地址:https://github.com/JingweiJ/ActionGenome
主要贡献

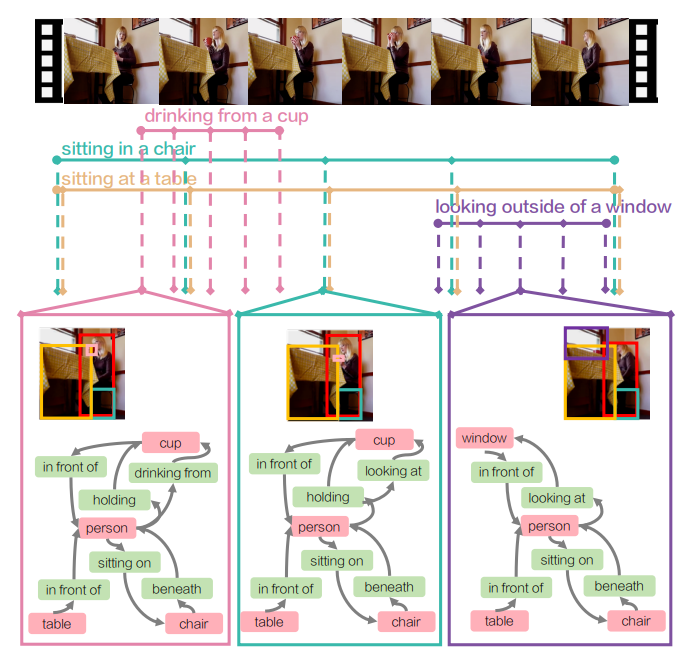
提供了Action Genome数据集,这是一种将动作分解为时空场景图的表示,场景图解释了对象及其关系如何随着动作的发生而变化,如上图所示;
使用Action Genome成功改进动作识别和少镜头动作识别的最新结果;
以现有的场景图模型为基准,提出了时空场景图预测的新任务。
相关背景
以动作识别为代表的视频理解任务通常将动作和活动视为发生在视频中的单个事件,即把视频当成一个单独的动作进行分析。相对应地,很多数据集对一个视频也用一个动作进行标注(端到端),而没有明确地将时间分解为一系列对象之间的交互。
虽然在图像领域,像基于图像的结构化如场景图已经被证明可以在很多任务上提升模型的性能。但在视频领域,对时间的拆解(objects以及对应关系)还处于未太多探索状态。
同时,在认知科学中,已经有研究支持人类会将长的视频分成几段以便理解,其积极地将正在进行的活动编码为分层部分结构。受到这个启发,Action Genome提供了研究人与物关系变化时行为动态的框架。它能够改进动作识别,实现少镜头动作检测,并引入时空场景图预测。
主要实现
在视频领域,提出Action Genome,将动作分解成时空场景的形式,提高对时间的理解。
以“person sitting on a sofa“为例,Action Genome在其对应的帧上进行object和relation的注释:
object:person,sofa
relation:person next to sofa,person in front of sofa,person sitting on sofa>
基于Charades构建含有场景图的数据集:Action Genome;按照上面所示的例子,对视频进行时空场景的标注工作,具体包括object以及relation;
最后的数据集包含:
157 动作类别 action categories;
234K 视频帧 video frames;
476K 对象包围盒 bounding boxes;
1.72M 关系 relationships。
在三种任务上证明了时空场景图对于视频理解的帮助:
动作识别 action recognition;
少镜头动作识别 few-shot action recognition;
时空场景图预测spatio-temporal scene graph prediction。
具体实现
数据集
先简单介绍一下场景图:
node:object(物体对应图里的节点)
edge:realtionship(物体之间的关系对应图中节点之间的边)
对应数据集的标注与构建:
整个数据集基于Charades构建起来;
标注的方法是以视频中的action为导向进行标注。
对空间-时间的视觉概念进行建模
如图所示,对于视频中的每个action(不同的颜色段),在这个时间范围内统一取样 5帧进行注释。假设一段视频中有4个actions(action本身可包含,可覆盖),那总共会有4x5=20帧视频帧被标注到。
注释器先标出跟这个action相关的object(bounding box),然后再标注relationships。
其中总共包含3类realtionships:
attention(looking or not)
spatial (空间位置)
contact (交互方式)
最后的数据集信息:
234253 帧 frames;
35 目标类型 object classes;
476229 包围框 bounding boxes;
25 关系类别 relationship classes;
1715568 实例 instances。
大多数对象都均匀地参与了三种类型的关系。
不像视觉基因组,数据集偏差会给预测给定对象类别的关系提供了一个强有力的基线,行动基因组没有这样的偏差。
实现方法
提出了一种场景图特征库SGFB方法,将时空场景图融合到动作识别中,使用信息库来表示特征,如:用于表示视频中出现的对象类别,甚至包括对象所在的位置。
SGFB模型包含两个组件,第一个组件生成时空场景图;第二个组件对图进行编码以预测动作标签。
SGFB为给定的视频序列中的每一帧生成一个时空场景图。预测视频中每一帧的场景图,这些场景图进行编码,被转换成特征表示,然后使用类似于长期特征库的方法进行组合,形成一个时空场景图特征库。最终与3DCNN特征合并,并用于预测动作标签。
具体分析如下图:
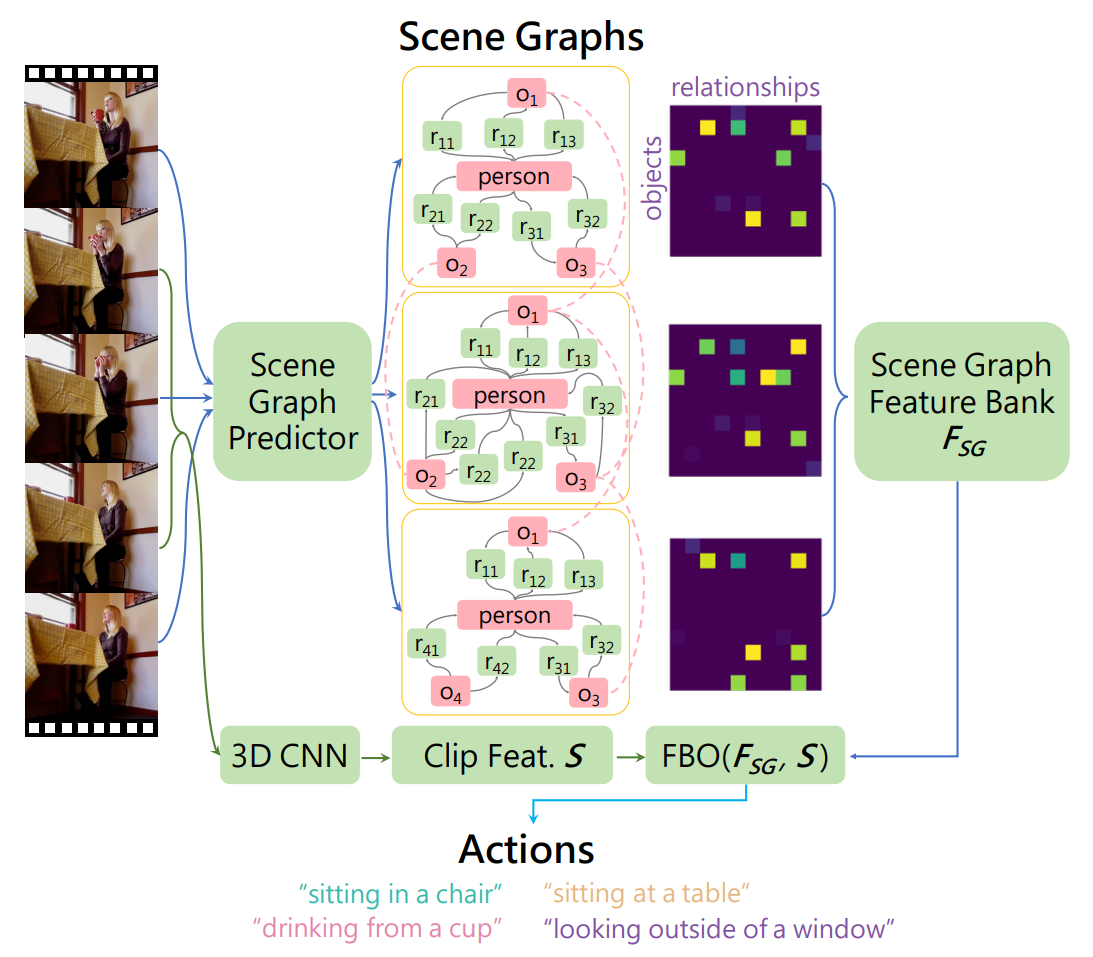
看颜色的线路(蓝 vs 绿),最终的特征来源最终包含2个部分:时空场景图和3D CNN。
其中时空场景图的部分:对于视频中的每一帧经过时空场景图预测(先用Faster RCNN进行目标检测,再用RelDN进行关系检测)构建对应的图,然后用类似long-term feature bank中的方法获取到图对应的特征表示。
具体而言,图中看到的feature map是|O| x |R|大小的,|O|表示所有object的数目(已经包含person),|R|表示所有relationship的种类,其值等于对应object的置信度乘上对应relationship的置信度。然后对于每一帧,都把这个map展开作为这一帧的feature,最后对不同帧之间做一个融合得到场景图这一路得到的特征。
3D CNN这一路是取视频中比较短的片段过3D conv主导的网络,最终得到的feature,这样可以结合短距离信息和长距离信息。3D CNN将短期信息嵌入S,为FSG提供上下文。
实验结果
动作识别上的结果
在Charader数据集上,通过用时空场景图特征替换LFB(long-term feature bank)的特征库,能在SOTA的LFB上提升1.8% mAP。且其在更小尺寸上能捕捉更多识别动作的信息。
细节:在每一帧上预测一个场景图,然后构建一个用于动作识别的时空场景图特征库,用Faster R-CNN和ResNet101作为区域提议和目标检测的骨干。利用ReIDN预测视觉关系。场景图预测在Action Genome上训练,遵循与Charader数据集相同的训练集和验证集分割视频。动作识别使用与LFB相同的特征提取器、超参数和求解调度程序。
优化目标探测器:假设真实的scene graph是存在的情况下,直接用手工标注的GT进行scene-graph的构建,时空场景图特征库直接从真实对象和标注框架的视觉关系中编码出一个特征向量,将这些特征库放入SGFB模型中,能在mAP上获得16%的提升。
如图可以看到,当基于视频的场景图模型使用时空场景图预测时,性能的提升显示了Action Genome和组合动作理解的潜力。

少命中动作识别的结果
Object:137个基类和20个新类。
首先在积累的所有视频示例上训练主干特征提取器(R101-I2D-NL)这个LFB\SGFB\SGFB oracle共享。接下来,只从每个新类中选取k个例子来训练每个模型,k=1,5,10;epoch=50。
结果:如下图所示,SGFB的表现优于LFB。
可知,SGFB更好地捕捉涉及物体和关系的动态动作。


时空场景图预测的结果
基于图像的场景图预测只有一个图像作为输入;而时空场景图则输入一个视频,利用邻近帧的时间信息来加强预测。
使用三种标准评价模式:
场景图预测SGDet,它期望输入图像并预测边界框位置、对象类别和谓词标签;
场景图分类SGCls,它期望预测真实框和对象类别、谓词标签;
谓词分类PredCls,期望预测真实框和边界框和对象类别来预测谓词标签。
将视频结果每一帧取平均值作为测试集的最终结果,如下图所示:
(1)IMP优于许多最近提出的方法;RelDN性能优于IMP,这表明对象和关系类之间的建模相似性提高了我们的任务性能;
(2)Predcls和sgcls任务之间的性能差距很小,表明这些模型无法准确地检测视频帧中的目标。

总结:改进专为视频设计的物体检测器可以提高性能。
因为模型只使用了Action Genome进行训练,而没有添加微调,添加微调后希望能有提高。
期望
时空动作本地化
大多数时空动作定位方法都专注于定位执行动作的人,而忽略了与人交互的对象。Action Genome可以同时研究行动者和对象的定位,形成更全面的有基础的行动定位任务。
可辩解的行为模型
动作基因组以物体的形式提供框架级别的注意力标签,执行动作的人要么在看,要么在与之互动。识别标签可以用于进一步训练可解释模型。
从时空场景图生成视频
最近的研究探索了从场景图生成图像。通过结构化的视频表示,希望能研究从时空场景图生成视频。
总结
Action Genome将动作分解成时空场景图。场景图解释了对象及其关系如何随着动作的发生而变化。通过收集大数据集的时空场景图来展示Action Genome的作用,并使用它来改进动作识别和少镜头动作识别的最新结果。最后,对新的场景图时空预测任务的结果进行了测试,实现了一定的性能提高。
希望Action Genome能在可分解和一般化的视频理解上激发一个新的研究方向。