- 论文: Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
- 官方代码(caffe): https://github.com/ZhaofanQiu/pseudo-3d-residual-networks
- 非官方(pytorch): https://github.com/qijiezhao/pseudo-3d-pytorch
- 由微软和中科大提出
- 被ICCV2017收录
一、核心创新
- 提出将3D卷积进行时间和空间的拆分来代替一个3D卷积
- 提出了几种变形的残差块
- 提出了P3D(Presudo-3D) ResNet
二、P3D Blocks和P3D ResNet
2.1 3D卷积解耦
3D卷积是同时提取空间信息和时间信息。拿核大小为3 x 3 x 3大小的3D卷积核来说,可以将其自然的解耦为一个1 x 3 x 3大小的卷积核和一个3 x 1 x 1大小的卷积核的组合。解耦的3D卷积称为伪(Pseudo)3D卷积。
2.2 Pseudo-3D Blocks
思想是将3D CNN按照2.1里面的解耦思想改造成P3D CNN,但是需要考虑两点:
- 时间维度和空间维度的计算是否需要直接或者间接的互相关联
- 两种维度的计算是否需要直接与输出关联
基于这两点考虑设计出下面三种P3D CNN:

又基于上面的三种链接的CNN和原始ResNet Block,提出下列三种P3D Block:
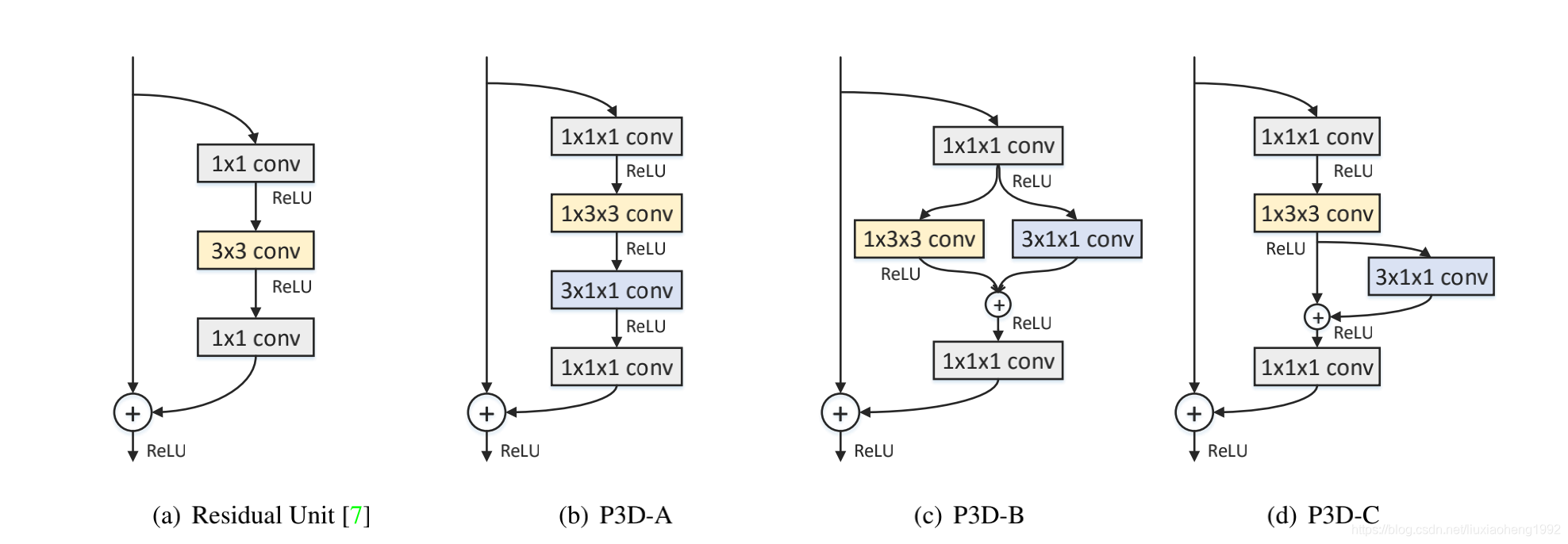
2.3 Pseudo-3D ResNet
为了检验那种P3D Block效果好,进行如下实验:
- 对于原始的ResNet,使用UCF101视帧进行finetune,输入图片从resized为240 x 320的视频帧中随机截取240 x 240,固定除去第一层BN后的所有BN参数,并且最后加入了droprate为0.9的dropout操作
- 对于原始的ResNet,测试时对每一帧进行预测,然后算平均值
- 其它的三类P3D ResNet参数初始化使用上一步训练好的参数
- P3D ResNet的输入为16 x 160 x 160,来源于从视频中截取不重叠的视频段16 x 182 x 242中随机截取
- 输入片段随机水平翻转
- batch为128
- SGD,lr初始为0.001,每迭代3k除以10,迭代7.5k
- 其它的三类P3D ResNet测试结果计算方法没提
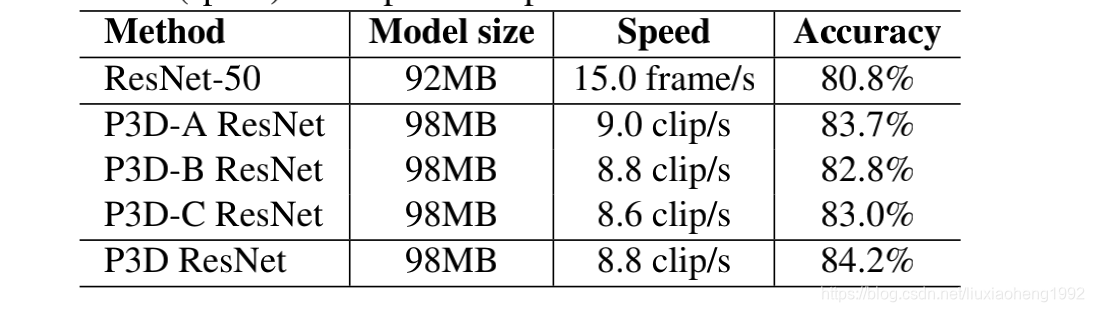
为了使得P3D Block在网络中多样,文章简单的按照P3D-A→P3D-B→P3D-C顺序进行block替换这种网络就称为P3D ResNet,实验结果在上面表中也有显示。

其他具体的参数和实验结果详情可以看原文和代码。
视频算法QQ交流群:657626967