论文阅读笔记: 2016 ECCV Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
本博客主要学习介绍2016 ECCV的一篇文章,这篇文章用于行为识别,来自瑞士苏黎世联邦理工大学计算机视觉实验室
主要思想
设计了一个时间分割网络 Temporal Segment Network(TSN),一种特定的基于长范围时间结构的用于视频动作识别的网络。模型结合了稀疏时间采样策略和视频等级监督方法,可以使用整体的动作视频进行便捷和有效的学习。
实验结果:在HMDB51(69.4%)和UCF101(94.2%)数据集上达到了当前最好的性能。
解决问题:如何设计一种有效的基于视频的网络结构能够学习视频的表现进而捕捉 long-range 时间结构。如何在有限的训练样本下学习卷积神经网络模型。
网络结构

对于一个输入的视频,将被分成K(k=3)个segments,从每个segment中随机地选择一个short snippet。将选择的snippets通过two-stream卷积神经网络得到不同snippets的class scores,最后将它们融合。不同片段的类别得分采用段共识函数(The segmental consensus function)进行融合来产生段共识(segmental consensus),这是一个视频级的预测。然后对所有模式的预测融合产生最终的预测结果。(这种方法大大降低了计算开销)
网络的具体思路:实验中设置片段的数量为 3;从每个序列中随机采样得到片段序列,随后输入卷积网络得到对应的得分,运用平均均值的聚合方法推断类别得分,获得相应的结果(使用Softmax函数);使用标准分类交叉熵损失(cross-entropy loss),随机梯度下降法(SGD)训练网络.
我们选择 Batch Normalization(BN)-Inception 结构设计 two-stream 卷积神经网络,由于它在准确率和效率之间有比较好的平衡。空间 stream 卷积神经网络作用在 single RGB images,时间 stream 卷积神经网络以 stacked optical flow field 作为输入。
正则化技术
在学习过程中,Batch Normalization 将估计每个 batch 内的激活均值和方差,并使用它们将这些激活值转换为标准高斯分布。这一操作虽可以加快训练的收敛速度,但由于要从有限数量的训练样本中对激活分布的偏移量进行估计,也会导致过拟合问题。因此,在用预训练模型初始化后,冻结所有 Batch Normalization 层的均值和方差参数,但第一个标准化层除外。由于光流的分布和 RGB 图像的分布不同,第一个卷积层的激活值将有不同的分布,于是,我们需要重新估计的均值和方差,称这种策略为部分 BN。
与此同时,在 BN-Inception 的全局 pooling 层后添加一个额外的 dropout 层,来进一步降低过拟合的影响。dropout 比例设置:空间流卷积网络设置为0.8,时间流卷积网络设置为0.7。
数据增强
数据增强能产生不同的训练样本并且可以防止严重的过拟合。在传统的 two-stream 中,采用随机裁剪和水平翻转方法增加训练样本。作者采用两个新方法:角裁剪(corner cropping)和尺度抖动(scale-jittering)。
角裁剪(corner cropping):仅从图片的边角或中心提取区域,来避免默认关注图片的中心。
尺度抖动(scale jittering):将输入图像或者光流场的大小固定为 ,裁剪区域的宽和高随机从 中选择。最终,这些裁剪区域将会被 resize 到 用于网络训练。事实上,这种方法不光包括了尺度抖动,还包括了宽高比抖动。
测试网络
由于在 TSN 中片段级的卷积网络共享模型参数,所以学习到的模型可以进行帧评估。具体来说,作者采用与 two-stream 相同的测试方案——即从动作视频中采样25个RGB帧或光流堆。同时,从采样得到的帧中裁剪4个边角和1个中心以及它们的水平翻转来评估卷积网络。为了根据训练测试模型,在Softmax之前融合了25帧和不同流的预测分数。
空间和时间流网络采用加权平均的方式进行融合。相比于 two-strean,TSN 中空间流卷积网络和时间流卷积网络的性能差距大大缩小。基于此,设置空间流的权重为1,设置时间流的权重为1.5。当正常和扭曲光流场都使用时,将其权重1.5分出1给正常光流场,0.5给扭曲光流场。
相关实验
UCF101数据集包含13,320个视频剪辑,其中共101类动作。HMDB51数据集是来自各种来源的大量现实视频的集合,比如:电影和网络视频,数据集包含来自51个动作分类的6,766个视频剪辑。
用在ImageNet上预训练的模型对网络权重进行初始化。实验中 learning rate 设置较小:对于空间网络,初始化为0.01,并且每2,000次迭代降为它的0.1 ,训练过程共迭代4,500次;对于时间网络,初始化为0.005,并且在第12,000和18,000次迭代之后降为它的 0.1,训练过程共迭代20,000次。
在UCF101 split 1上对不同训练策略进行实验的结果:
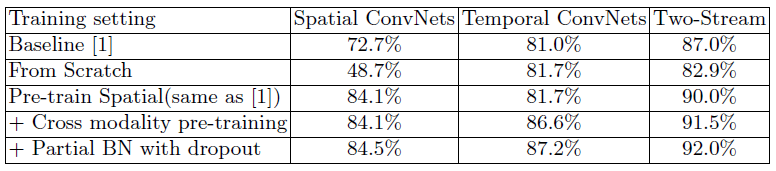
由上表可以看出,从零开始训练比基线算法(two-stream卷积网络)的表现要差很多,证明需要重新设计训练策略来降低过拟合的风险,特别是针对空间网络。对空间网络进行预训练、对时间网络进行交叉输入模式预训练,取得了比基线算法更好的效果。之后还在训练过程中采用部分 BN dropout 的方法,将识别准确率提高到了 92.0%。
不同输入模式的表现比较
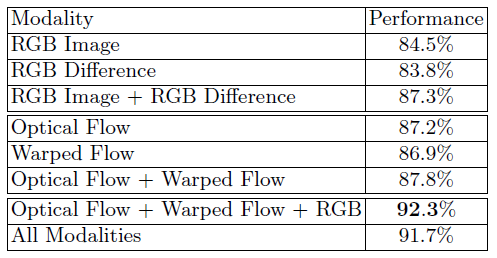
由上表可以看出:首先,RGB图像和RGB差异的结合可以将识别准确率提高到87.3%,这表明两者的结合可以编码一些补充信息。光流和扭曲光流的表现相近(87.2% vs 86.9%),两者融合可以提高到87.8%。四种模式的结合可以提高到91.7%。由于RGB差异可以描述相似但不稳定的动作模式,作者还评估了其他三种模式结合的表现(92.3% vs 91.7%)。作者推测光流可以更好地捕捉运动信息,而RGB差异在描述运动时是不稳定的。在另一方面,RGB差异可以当作运动表征的低质量、高速的替代方案。
TSN不同段共识函数的实验结果

由上表可以看出:平局池化函数达到最佳的性能。因此在接下来的实验中选择平均池化作为默认的聚合函数。
在不同深度卷积网络上的实验结果
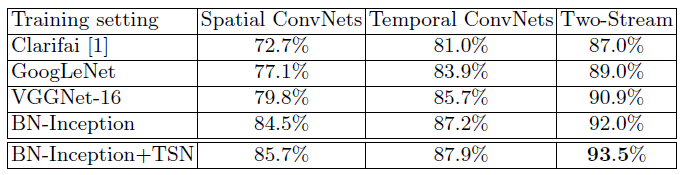
具体来说,比较了3个非常深的网络架构:BN-Inception、GoogLeNet和VGGNet-16。在这些架构中,BN-Inception表现最好,故选择它作为TSN的卷积网络架构。
Temporal Segment Networks
2016年的 ECCV: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
官方主页
配置/安装
下载github原始文件并编译安装.注意:此处编译OpenCV2.4.13\dense_flow\Caffe.
git clone --recursive https://github.com/yjxiong/temporal-segment-networks
bash build_all.sh随后,我们获取了视频数据(UCF101/HMDB51)和预训练模型.
bash scripts/get_reference_models.sh提取图像帧以及提取光流信息;
bash scripts/extract_optical_flow.sh SRC_FOLDER OUT_FOLDER NUM_WORKERDemo – testing
执行代码如下:
python tools/eval_net.py ucf101 1 rgb \
/home/ling/YH/work/Action_Recognition/dataset/UCF-101-flow \
models/ucf101/tsn_bn_inception_rgb_deploy.prototxt \
models/ucf101_split_1_tsn_rgb_reference_bn_inception.caffemodel \
--num_worker 1 \
--save_scores /home/ling/YH/work/Action_Recognition/temporal-segment-networks/result/RGB_SCORE_FILE_ucf101_split_1 通过代码:python tools/eval_scores.py SCORE_FILE可以得到对应的结果
Accuracy 86.02% (ucf101 1 rgb)
Accuracy 84.96% (ucf101 2 rgb)
Accuracy 84.55% (ucf101 3 rgb)
Accuracy 85.10% (UCF101 3 Splits Average)
Demo – training
执行代码如下:提取结果将被放置在文件夹data/下,文件名为ucf101_rgb_train_split_1.txt,形式为video_frame_path 100 10(路径,视频提取帧数,类别数)
bash scripts/build_file_list.sh ucf101 FRAME_PATH # 其中,FRAME_PATH为图片提取帧后的地址随后,我们训练网络:
bash scripts/train_tsn.sh ucf101 rgb # 训练网络训练结果如下所示:
# ucf101_rgb_split1
Iteration 3500, Testing net (#0)
I0402 22:00:20.749547 5647 solver.cpp:490] Test net output #0: accuracy = 0.836842
I0402 22:00:20.749697 5647 solver.cpp:490] Test net output #1: loss = 0.698602 (* 1 = 0.698602 loss)
**Accuracy 85.25% (UCF101 3 Splits Average)**Demo – 单视频测试
为了后续方便处理,我们这里对文件进行了相应的修改,从而可以进行单视频测试,修改如下:(这里,我们紧紧针对在 rgb 1 上进行修改)
首先:修改/data/ucf101_splits/文件夹中的测试集01 testlist01.txt,将其修改为你需要测试的单一视频,如:HandstandWalking/v_HandstandWalking_g07_c04.avi
接下来,修改/data/文件夹中的文件ucf101_rgb_val_split_1.txt,将将其修改为你需要测试的单一视频帧,如:dataset/v_HandstandWalking_g07_c04 192 37(这些文件是在 training 开始阶段产生的,请看上边的代码)
随后,制作数据集 dataset:dataset中只包括你的视频帧文件,如:dataset/v_HandstandWalking_g07_c04 192 37
最后,进行测试,测试代码示例如下:
python tools/eval_net.py ucf101 1 rgb \
dataset \ # 制作数据集位置
models/bn_inception_kinetics_rgb_pretrained/bn_inception_rgb_deploy.prototxt \ # 模型
single_test/ucf101_kinetics_rgb_split1_iter_6500.caffemodel \ # 模型参数
--num_worker 1 \ # GPU个数
--save_scores result/Kinetics_RGB_re_bn_SCORE_FILE_ucf101_split_1 # 存放结果